


Einführung in die Datenwissenschaft | Schlüsselkomponenten | Typen und Gelegenheiten
Was ist Data Science?
Data Science ist ein interdisziplinäres Gebiet, das sich mit wissenschaftlichen Methoden, Verfahren und Systemen zur Erhebung, Aufbereitung und Analyse von Daten in strukturierter und unstrukturierter Form befasst. Data Science nutzt verschiedene Bereiche, darunter Mathematik, Statistik, Datenbanken, Informationswissenschaft und Informatik. Die Daten können viele Typen und verschiedene Größen haben.
Bedarf an Data Science als eigenständiges Feld:
Der Hauptgrund für die Aufwertung der Datenwissenschaft auf die Ebene eines separaten Bereichs ist die exponentiell wachsende Datenrate um uns herum. Schätzungen zufolge werden bis 2020 rund 1,7 Megabyte an Daten pro Sekunde produziert. Die digitale Datenakkumulation wird 44 Billionen Gigabyte erreichen. Bei solch großen Datenmengen wird es immer schwieriger, sie zu verstehen und zu speichern. Daher benötigen wir eine Möglichkeit, diese Daten zu untersuchen und zu verstehen. Daher wurde Data Science als eigenständiges Fachgebiet anerkannt. 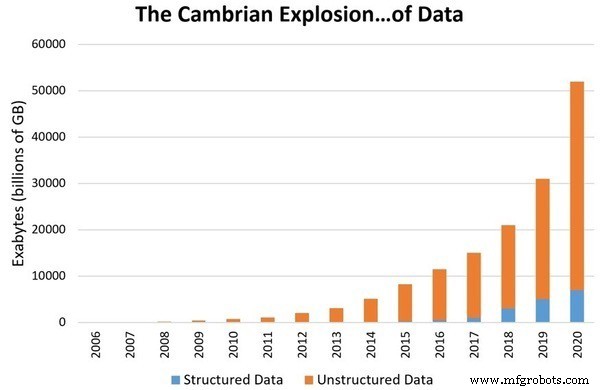
Datenwissenschaft um uns herum:
Unternehmen nutzen Data Science, um ihre Datenprozesse innerhalb des Unternehmens zu verstehen und einfach zu sortieren. Beispielsweise verwendet Google Data Science, um die Werbung zu personalisieren, die Nutzern auf den von ihnen verwendeten Websites angezeigt wird. Dies geschieht über ihr Programm AdSense, das es Publishern ermöglicht, Inhalte an bestimmte Zielgruppen zu liefern.
In ähnlicher Weise berechnet Uber, wie viel einem Kunden in Rechnung gestellt wird, wann Rabatte gewährt werden und an wen. Airbnb hilft Menschen, indem es mithilfe von Data Science den Preis schätzt, zu dem sie ihre Häuser mieten sollten. Einfach ausgedrückt können wir dies verstehen, indem wir Kunden und Benutzer als Rohdaten betrachten und Data Science hilft, diese Daten zu interpretieren. 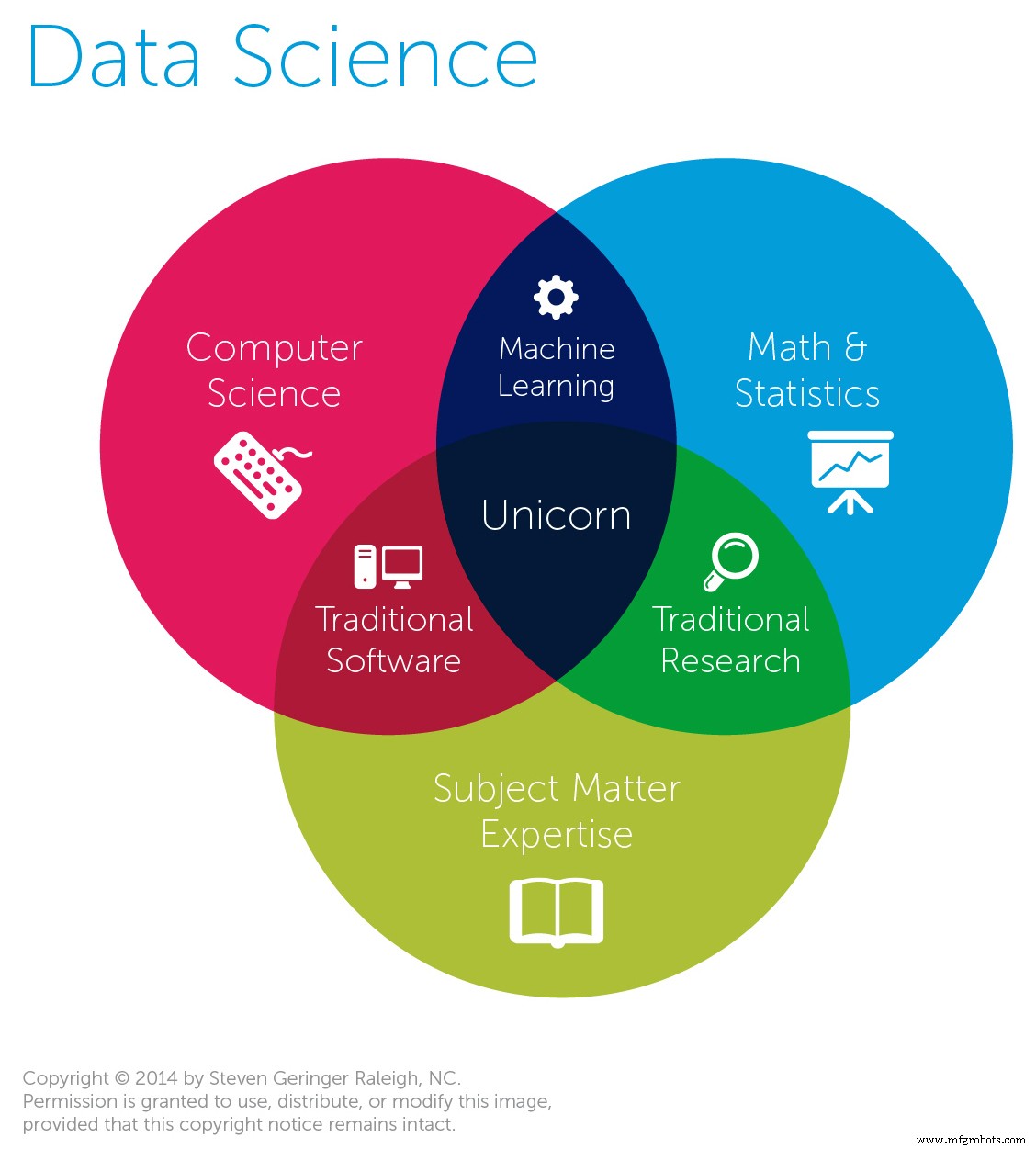
Datenwissenschaft in Regierungs- und Nichtregierungsorganisationen:
Daten sind ein kritischer Vermögenswert für Regierungsorganisationen. Jeden Tag werden immer mehr Daten gesammelt. Daher benötigen sie eine Möglichkeit, all diese Daten zu sortieren und zu speichern, was durch Data Science erfolgen kann. In ähnlicher Weise nutzen auch Nichtregierungsorganisationen Data Science. Der WWF nutzt die Datenwissenschaften, um Informationen in statistischer Hinsicht zu Wildtierproblemen aufzuzeigen und damit ihre Sache wirksam zu machen.
Möglichkeiten in der Datenwissenschaft:
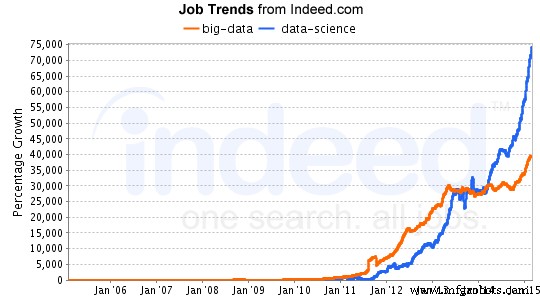
Da der Bereich Data Science weiter wächst, nehmen auch die Beschäftigungsmöglichkeiten in diesem Bereich exponentiell zu. Eine von LinkedIn durchgeführte Analyse zum Stellenwachstum in der Datenwissenschaft zeigte einen starken Anstieg im Bereich der Datenwissenschaft, insbesondere in den letzten 30 Jahren. Wenn Sie sich für Data Science interessieren, können Sie kostenlose Online-Kurse erhalten. Sehen Sie sich dieses Tutorial zu einer gemeinsamen Lounge an.
Schlüsselkomponenten:
Jetzt geben wir Ihnen einen Einblick in die Datenwissenschaft und ihre verschiedenen Komponenten.
1:Programmierung:
Bei Data Science dreht sich alles um Daten. Um diese Daten zu organisieren und zu analysieren, verwenden wir Programmierung. Es gibt viele Arten von Programmiersprachen. Die beiden am weitesten verbreiteten sind Python und R.
Python: Python ist die am besten lesbare und flexibelste Programmiersprache, daher ihre weit verbreitete Verwendung. Es verfügt über viele leistungsstarke statistische und numerische Pakete, darunter NumPy und Pandas, Matplotlib, Tensorflow, iPython usw. Python ist viel schneller und einfacher zu erlernen.
R: R ist eine andere Programmiersprache, aber das meiste konzentriert sich auf statistische und grafische Techniken. R wird von Statistikern und Data Minern häufig zur Entwicklung statistischer Software und Datenanalyse verwendet. Es ist eine Open-Source-Sprache.
2:Daten und ihre Typen:
Die nächste Schlüsselkomponente sind die Daten selbst. Um Daten zu verstehen, müssen wir zuerst ihre Typen verstehen.
Strukturierte Daten: Strukturierte Daten beziehen sich auf Informationen mit einem hohen Organisationsgrad. Sie lässt sich einfach tabellarisch darstellen, in Datenbanken speichern und weiterverarbeiten.
Unstrukturierte Daten: Unstrukturierte Daten sind Informationen, die kein Datenmodell haben oder nicht organisiert sind. Es kann aus Text oder Daten wie Daten, Zahlen, E-Mails, PDF-Dateien, Bildern, Videos usw. bestehen
Natürliche Sprache: Daten in Form von geschriebenen Sprachen, die zur Kommunikation verwendet werden, wie Englisch, Spanisch und Urdu usw. Sie können als Untertyp von unstrukturierten Daten betrachtet werden.
Bild, Video, Audio: Auch Bilder, Videos und Audios sind in ihrer Form unstrukturiert. Sie werden mit Kameras und Mikrofonen erzeugt. Die zunehmende Nutzung zeigt sich bei Smartphones, wo täglich Bilder und Videos gespeichert und verarbeitet werden.
Grafikbasierte Daten: Graph ist eine Menge von Ecken und Kanten. Es ist eine mathematische Struktur, die verwendet wird, um die Beziehung zwischen zwei Entitäten darzustellen.
Maschinell generiert: Maschinengenerierte Daten werden von Computersystemen, Anwendungen oder Maschinen ohne menschliches Zutun erstellt.
3:Statistik, Wahrscheinlichkeit und ihre Beziehung zur Datenwissenschaft:
Statistiken: Statistik ist ein Zweig der Mathematik, der sich mit der Erhebung, Interpretation, Analyse, Präsentation und Organisation von Daten befasst. Es verwendet Programmieren, um Daten zu analysieren.
Wahrscheinlichkeit: Die Wahrscheinlichkeit ist das Maß für die Wahrscheinlichkeit, dass ein Ereignis eintritt. Sie wird als Zahl zwischen 0 und 1 quantifiziert, wobei 0 für Unmöglichkeit und 1 für Gewissheit steht.
Bezug zu Data Science: Statistik und Wahrscheinlichkeit haben beide mit Data Science zu tun. Sie sind die Grundlage für die Verarbeitung und Analyse von Daten. Wir verwenden diese beiden Wissenschaften in Verbindung mit Data Science, um Daten richtig zu interpretieren.
4:Maschinelles Lernen:
Maschinelles Lernen ist das Gebiet der Informatik, das aus der KI stammt. Es verwendet statistische Techniken, um Computern die Fähigkeit zu geben, zu lernen, ohne programmiert zu werden. Die Maschine verbessert schrittweise ihre Leistung bei einer bestimmten Aufgabe, indem sie die Struktur oder das Programm ändert. Es gibt drei Hauptziele des maschinellen Lernens. Erstens, um die Änderungen und die Darstellung dieser Änderungen zu lernen. Zweitens, um die Leistung zu verallgemeinern, damit sie nicht bei einer einzelnen Aufgabe, sondern bei ähnlichen Aufgaben gleichermaßen wirksam ist. Dritte. Um die Leistung einer Maschine zu verbessern und Wege zu finden, um eine Verschlechterung der Leistung zu verhindern. In der Datenwissenschaft wird Machine Learning in Algorithmen, Regressions- und Klassifikationsverfahren eingesetzt. Es wird verwendet, um das Ergebnis von Daten vorherzusagen, die auf unterschiedliche Weise verarbeitet werden.
5:Big Data:
Big Data ist die Bezeichnung für Daten, die so groß sind, dass das Speichern oder Verarbeiten dieser Daten eine große Anzahl von Computern erfordert. Es ist durch drei Vs gekennzeichnet:
Lautstärke: Daten in großen Mengen von Terabyte bis Zettabyte.
Sorte: Daten können eine große Vielfalt und Diversität aufweisen. Es kann eine Mischung aus zwei oder mehr Datentypen sein, z. B. sowohl strukturiert als auch unstrukturiert.
Geschwindigkeit: Daten werden mit einer ständig wachsenden Geschwindigkeit generiert. Im Wesentlichen ist es die Geschwindigkeit der Daten. 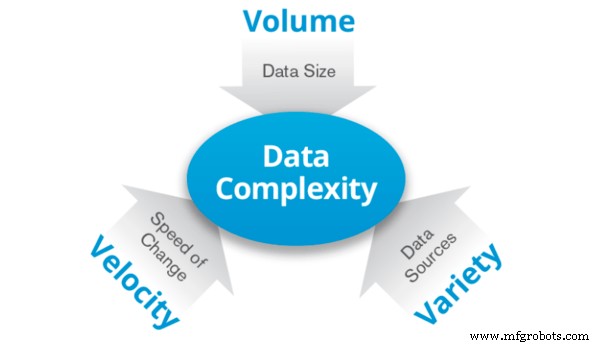
In der Datenwissenschaft werden Daten in viele Formen und Typen gruppiert. Als Big Data werden riesige Datenmengen bezeichnet, die mit herkömmlichen Anwendungen nicht verarbeitet werden können. Data Scientists verwenden verschiedene Tools, um Big Data zu untersuchen und zu verarbeiten, beispielsweise Hadoop, Spark, R und Java usw.
Industrietechnik
- C#-Variablen und (primitive) Datentypen
- Python-Datentypen
- Eine Einführung in Edge Computing und Anwendungsbeispiele
- 5 verschiedene Arten von Rechenzentren [mit Beispielen]
- C - Datentypen
- MATLAB - Datentypen
- C# - Datentypen
- Arten und Klassifizierung von Bearbeitungsprozessen | Fertigungswissenschaft
- Fräsmaschinen – Einführung und besprochene Typen
- Bedeutung und Typen des Herstellungsprozesses