


Python-XML-Parser-Tutorial:Beispiel für XML-Datei lesen (Minidom, ElementTree)
Was ist XML?
XML steht für eXtensible Markup Language. Es wurde entwickelt, um kleine bis mittlere Datenmengen zu speichern und zu transportieren, und wird häufig zum Teilen strukturierter Informationen verwendet.
Mit Python können Sie XML-Dokumente analysieren und ändern. Um ein XML-Dokument zu analysieren, müssen Sie das gesamte XML-Dokument im Speicher haben. In diesem Tutorial werden wir sehen, wie wir die XML-Minidom-Klasse in Python verwenden können, um XML-Dateien zu laden und zu parsen.
In diesem Tutorial werden wir lernen-
- Wie man XML mit Minidom parst
- Erstellung eines XML-Knotens
- Wie man XML mit ElementTree parst
Wie man XML mit Minidom parst
Wir haben eine Beispiel-XML-Datei erstellt, die wir analysieren werden.
Schritt 1) In der Datei sehen wir Vorname, Nachname, Wohnort und das Fachgebiet (SQL, Python, Testing und Business)
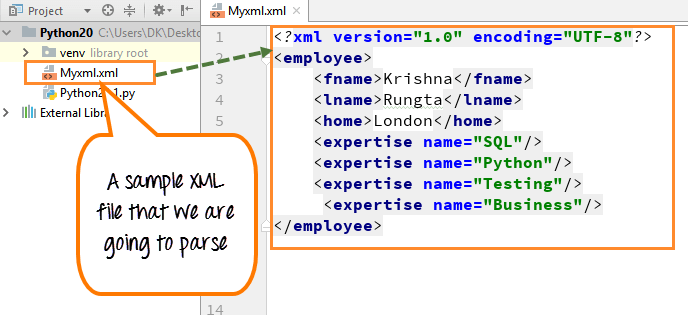
Schritt 2) Sobald wir das Dokument geparst haben, drucken wir den „Knotennamen“ aus des Stammverzeichnisses des Dokuments und dem „firstchild tagname“ . Tagname und nodename sind die Standardeigenschaften der XML-Datei.

- Importieren Sie das Modul xml.dom.minidom und deklarieren Sie die zu analysierende Datei (myxml.xml)
- Diese Datei enthält einige grundlegende Informationen über Mitarbeiter wie Vorname, Nachname, Wohnort, Fachwissen usw.
- Wir verwenden die Parse-Funktion auf dem XML-Minidom, um die XML-Datei zu laden und zu parsen
- Wir haben die Variable doc und doc erhält das Ergebnis der Parse-Funktion
- Wir möchten den Knotennamen und den untergeordneten Tagnamen aus der Datei drucken, also deklarieren wir ihn in der Druckfunktion
- Führen Sie den Code aus – Er gibt den Knotennamen (#document) aus der XML-Datei und den ersten untergeordneten Tagnamen (Mitarbeiter) aus der XML-Datei aus
Hinweis :
Knotenname und untergeordneter Tagname sind die Standardnamen oder Eigenschaften eines XML-Doms. Falls Sie mit dieser Art von Namenskonventionen nicht vertraut sind.
Schritt 3) Wir können auch die Liste der XML-Tags aus dem XML-Dokument aufrufen und ausdrucken. Hier haben wir die Skills wie SQL, Python, Testing und Business ausgedruckt.
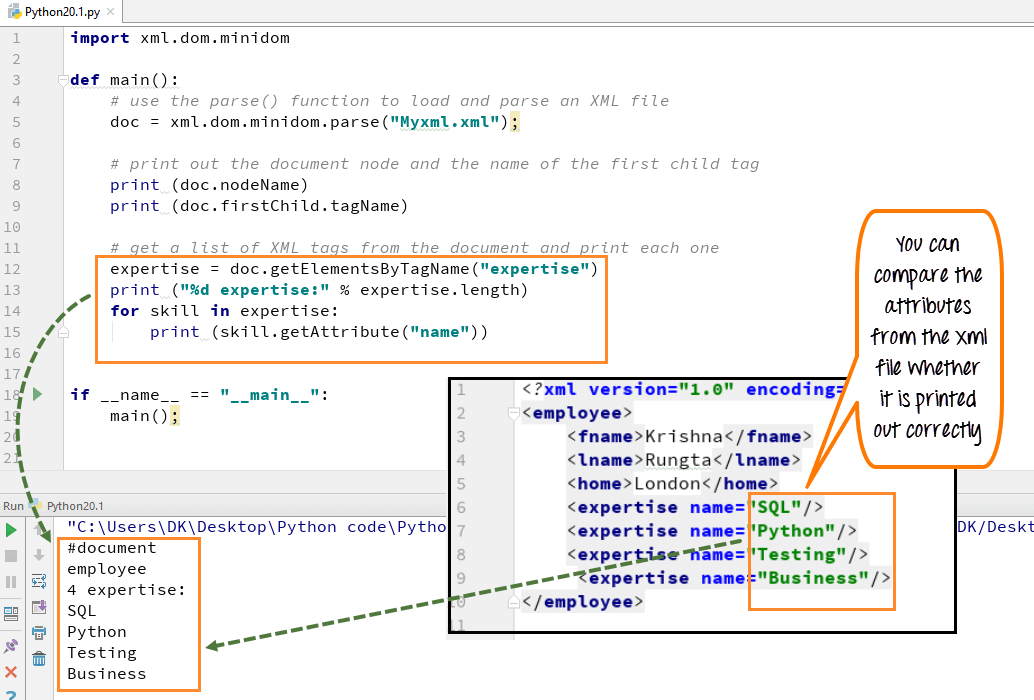
- Geben Sie die variable Expertise an, aus der wir die gesamte Expertise extrahieren, die der Name des Mitarbeiters hat
- Verwenden Sie die dom-Standardfunktion namens „getElementsByTagName“
- Dadurch werden alle Elemente namens skill abgerufen
- Deklarieren Sie eine Schleife über jedem Skill-Tag
- Führen Sie den Code aus – Es wird eine Liste mit vier Fertigkeiten angezeigt
So erstellen Sie einen XML-Knoten
Wir können ein neues Attribut erstellen, indem wir die Funktion „createElement“ verwenden und dieses neue Attribut oder Tag dann an die vorhandenen XML-Tags anhängen. Wir haben unserer XML-Datei ein neues Tag „BigData“ hinzugefügt.
- Sie müssen codieren, um das neue Attribut (BigData) zum vorhandenen XML-Tag hinzuzufügen
- Dann müssen Sie das XML-Tag mit neuen Attributen ausdrucken, die an das vorhandene XML-Tag angehängt sind
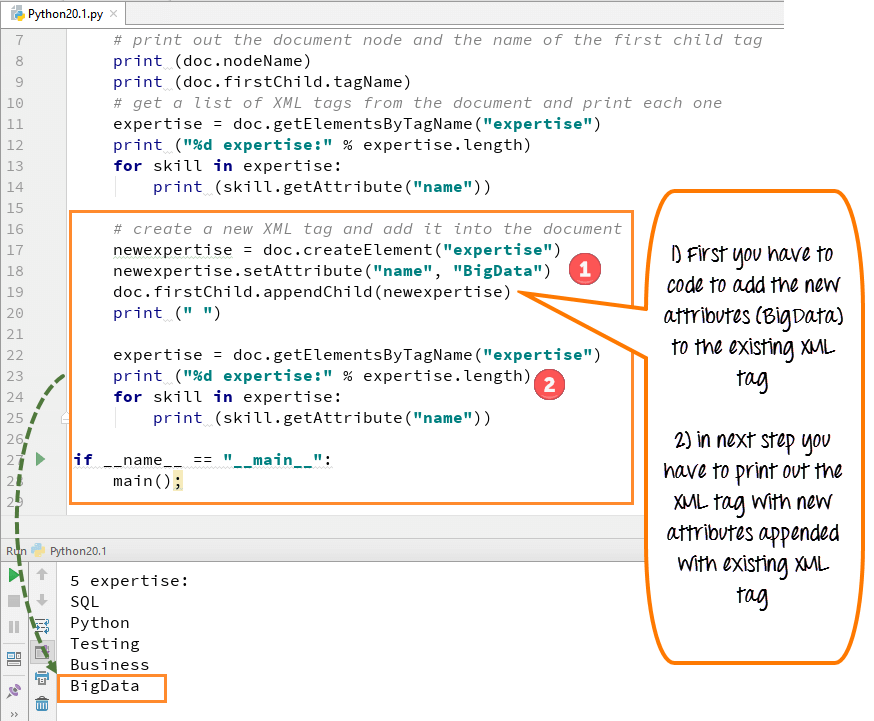
- Um ein neues XML hinzuzufügen und es dem Dokument hinzuzufügen, verwenden wir den Code „doc.create elements“
- Dieser Code erstellt ein neues Skill-Tag für unser neues Attribut „Big-Data“
- Fügen Sie dieses Skill-Tag in das erste Kind des Dokuments (Mitarbeiter) ein
- Führen Sie den Code aus – das neue Tag „Big Data“ wird mit der anderen Liste der Fachkenntnisse angezeigt
XML-Parser-Beispiel
Python 2-Beispiel
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print doc.nodeName
print doc.firstChild.tagName
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print " "
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
if name == "__main__":
main(); Python 3-Beispiel
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print (doc.nodeName)
print (doc.firstChild.tagName)
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print (" ")
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
if __name__ == "__main__":
main(); Wie man XML mit ElementTree parst
ElementTree ist eine API zum Bearbeiten von XML. ElementTree ist der einfache Weg, XML-Dateien zu verarbeiten.
Wir verwenden das folgende XML-Dokument als Beispieldaten:
<data>
<items>
<item name="expertise1">SQL</item>
<item name="expertise2">Python</item>
</items>
</data>
Lesen von XML mit ElementTree:
wir müssen zuerst das Modul xml.etree.ElementTree importieren.
import xml.etree.ElementTree as ET
Lassen Sie uns nun das Wurzelelement abrufen:
root = tree.getroot()
Im Folgenden finden Sie den vollständigen Code zum Lesen der obigen XML-Daten
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# all items data
print('Expertise Data:')
for elem in root:
for subelem in elem:
print(subelem.text)
Ausgabe:
Expertise Data: SQL Python
Zusammenfassung:
Mit Python können Sie das gesamte XML-Dokument auf einmal parsen und nicht nur jeweils eine Zeile. Um ein XML-Dokument zu analysieren, müssen Sie das gesamte Dokument im Speicher haben.
- XML-Dokument parsen
- xml.dom.minidom importieren
- Verwenden Sie die Funktion „parse“, um das Dokument zu parsen ( doc=xml.dom.minidom.parse (Dateiname);
- Aufrufen der Liste der XML-Tags aus dem XML-Dokument mit Code (=doc.getElementsByTagName( „Name der xml-Tags“)
- Um ein neues Attribut im XML-Dokument zu erstellen und hinzuzufügen
- Verwenden Sie die Funktion „createElement“
Python
- Python-Datei-I/O
- Java BufferedReader:Lesen von Dateien in Java mit Beispiel
- Python String strip() Funktion mit BEISPIEL
- Länge der Python-Zeichenfolge | len() Methode Beispiel
- Yield in Python Tutorial:Generator &Yield vs. Return Beispiel
- Python-Zähler in Sammlungen mit Beispiel
- Enumerate() Funktion in Python:Loop, Tuple, String (Beispiel)
- Python-Prüfung, ob Datei vorhanden ist | So prüfen Sie, ob ein Verzeichnis in Python existiert
- Python JSON:Codieren (Dumps), Decodieren (Laden) und JSON-Datei lesen
- Python List index() mit Beispiel