


Entwickeln Sie neue Programmiergewohnheiten, um Fehler in eingebetteter Software zu reduzieren
Die Anwendungsgröße und -komplexität hat sich in den letzten zehn Jahren erheblich verschärft. Nehmen wir als Beispiel die Automobilbranche. Laut The New York Times Vor 20 Jahren hatte ein durchschnittliches Auto eine Million Codezeilen, aber 10 Jahre später hatte der Chevrolet Volt von General Motors 2010 etwa 10 Millionen Codezeilen – mehr als ein F-35-Kampfjet. Heute hat ein durchschnittliches Auto mehr als 100 Millionen Codezeilen.
Der Wechsel zu 32-Bit- und höheren Prozessoren mit viel Speicher und Leistung hat es Unternehmen ermöglicht, weit mehr wertschöpfende Funktionen und Fähigkeiten in Designs einzubauen; das ist die spitze. Der Nachteil ist, dass die Menge an Code und seine Komplexität oft zu Fehlern führen, die sich auf die Anwendungssicherheit und -sicherheit auswirken.
Es ist an der Zeit für einen besseren Ansatz. Zwei Haupttypen von Fehlern können in Software gefunden und mithilfe von Werkzeugen behoben werden, die die Einführung von Fehlern verhindern:
- Codierungsfehler:Ein Beispiel ist Code, der versucht, außerhalb der Grenzen eines Arrays zuzugreifen. Diese Art von Problemen kann durch eine statische Analyse erkannt werden.
- Anwendungsfehler:Diese können nur erkannt werden, wenn Sie genau wissen, was die Anwendung tun soll, dh anhand der Anforderungen getestet werden muss.
Beheben Sie diese Fehler und Entwicklungsingenieure werden einen langen Weg zu sicherem Code zurücklegen.
Eine Unze Prävention durch Code-Check
Fehler im Code passieren genauso leicht wie Fehler in E-Mail und Instant Messaging. Dies sind die einfachen Fehler, die passieren, weil Ingenieure es eilig haben und nicht Korrektur lesen. Aber mit der Komplexität kommt eine Reihe von Designfehlern, die große Herausforderungen mit sich bringen. Komplexität erfordert ein völlig neues Verständnis der Funktionsweise des Systems, der Weitergabe von Daten und der Definition von Werten. Unabhängig davon, ob Fehler durch Komplexität oder ein menschliches Problem verursacht werden, können sie dazu führen, dass ein Codeabschnitt versucht, auf einen Wert außerhalb der Grenzen eines Arrays zuzugreifen. Und ein Codierungsstandard fängt das ein.
Diese verwandten Artikel von Embedded könnten Sie auch interessieren:
Erstellen Sie sichere und zuverlässige eingebettete Systeme mit MISRA C/C++
Verwenden der statischen Analyse zum Erkennen von Codierungsfehlern in sicherheitskritischen Open-Source-Serveranwendungen
Wie vermeidet man solche Fehler? Legen Sie sie erst gar nicht dort ab. Obwohl dies offensichtlich klingt – und fast unmöglich – ist dies genau der Wert, den ein Codierungsstandard auf den Tisch bringt.
In der C- und C++-Welt werden 80 % der Softwarefehler durch die falsche oder unüberlegte Verwendung von etwa 20 % der Sprache verursacht. Der Kodierungsstandard schränkt die bekanntermaßen problematischen Teile der Sprache ein. Das Ergebnis:Fehler werden vermieden und die Softwarequalität deutlich gesteigert. Schauen wir uns ein paar Beispiele an.
Die meisten C- und C++-Programmierfehler werden durch undefinierte, implementierungsdefinierte und nicht spezifizierte Verhaltensweisen verursacht, die jeder Sprache innewohnen und zu Softwarefehlern und Sicherheitsproblemen führen. Dieses durch die Implementierung definierte Verhalten verbreitet ein höherwertiges Bit, wenn eine ganze Zahl mit Vorzeichen nach rechts verschoben wird. Abhängig vom verwendeten Compiler-Ingenieur kann das Ergebnis 0x40000000 oder 0xC0000000 sein, da C nicht die Reihenfolge angibt, in der Argumente für eine Funktion ausgewertet werden.
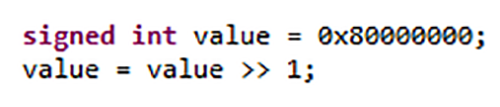
Abbildung 1. Das Verhalten einiger C- und C++-Konstrukte hängt vom verwendeten Compiler ab. Quelle:LDRA
In Abbildung 2 —wo die rollDice() Die Funktion liest einfach den nächsten Wert aus einem Ringpuffer, der die Werte „1,2,3 und 4“ enthält – der erwartete Rückgabewert wäre 1234. Aber dafür gibt es keine Garantie. Mindestens ein Compiler generiert Code, der den Wert 3412 zurückgibt.

Abbildung 2. Das Verhalten einiger C- und C++-Konstrukte wird von den Sprachen nicht spezifiziert. Quelle:LDRA
Es gibt viele andere Fallstricke in der Sprache C/C++:Verwendung von Konstrukten wie goto oder malloc; Mischungen von vorzeichenbehafteten und vorzeichenlosen Werten; oder „kluger“ Code, der zwar hocheffizient und kompakt ist, aber so kryptisch und komplex ist, dass andere ihn nur schwer verstehen können. Jedes dieser Probleme kann zu Fehlern führen, Werteüberläufe, die plötzlich negativ werden, oder einfach die Wartung des Codes unmöglich machen.
Codierungsstandards bieten das Quäntchen Prävention für diese Krankheiten. Sie können die Verwendung dieser problematischen Konstrukte verhindern und Entwickler daran hindern, undokumentierten, übermäßig komplexen Code zu erstellen sowie die Konsistenz des Stils zu überprüfen. Sogar Dinge wie die Überprüfung, ob das Tabulatorzeichen nicht verwendet wird oder Klammern an einer bestimmten Position positioniert sind, können überwacht werden. Obwohl dies trivial erscheint, hilft das Befolgen des Stils enorm bei der manuellen Codeüberprüfung und verhindert Verwechslungen durch eine andere Tabulatorgröße, wenn der Code in einem anderen Editor angezeigt wird – alles Ablenkungen, die einen Prüfer daran hindern, sich auf den Code zu konzentrieren.
MISRA zur Rettung
Die bekanntesten Programmierstandards sind die MISRA-Richtlinien, die erstmals 1998 für die Automobilindustrie veröffentlicht wurden und heute von vielen eingebetteten Compilern, die ein gewisses Maß an MISRA-Prüfung bieten, allgemein angenommen werden. MISRA konzentriert sich auf die problematischen Konstrukte und Praktiken in den Sprachen C und C++ und empfiehlt die Verwendung konsistenter stilistischer Merkmale, ohne jedoch irgendwelche Vorschläge zu machen.
Die MISRA-Richtlinien bieten nützliche Erklärungen dazu, warum jede Regel existiert, zusammen mit Einzelheiten zu den verschiedenen Ausnahmen von dieser Regel und Beispielen für das undefinierte, nicht spezifizierte und durch die Implementierung definierte Verhalten. Abbildung 3 veranschaulicht das Niveau der Anleitung.

Abbildung 3. Diese MISRA C-Referenzen beziehen sich auf undefiniertes, nicht spezifiziertes und durch die Implementierung definiertes Verhalten. Quelle:LDRA
Die meisten MISRA-Richtlinien sind „entscheidbar“, d. h. das Tool kann erkennen, ob ein Verstoß vorliegt; Einige sind jedoch „unentscheidbar“, was bedeutet, dass das Tool nicht immer feststellen kann, ob ein Verstoß vorliegt.
Eine nicht initialisierte Variable, die an eine Systemfunktion übergeben wird, die sie initialisieren soll, wird möglicherweise nicht als Fehler registriert, wenn das statische Analysetool keinen Zugriff auf den Quellcode für die Systemfunktion hat. Es besteht die Möglichkeit eines falsch-negativen oder falsch-positiven Ergebnisses.
Im Jahr 2016 wurden 14 Richtlinien zu MISRA hinzugefügt, um die Prüfung auf sicherheitskritischen Code, nicht nur auf Sicherheit, zu ermöglichen. Abbildung 4 veranschaulicht, wie eine der neuen Richtlinien – Richtlinie 4.14 – dieses Problem löst und dabei hilft, Fallstricke aufgrund undefinierten Verhaltens zu vermeiden.

Abbildung 4. Die MISRA-Richtlinie 4.14 hilft, Fallstricke zu vermeiden, die durch undefiniertes Verhalten entstehen. Quelle:LDRA
Die strengen Codierungsstandards wurden traditionell mit funktional sicherer Software für kritische Anwendungen wie Autos, Flugzeuge und medizinische Geräte in Verbindung gebracht. Die Komplexität des Codes, die Bedeutung der Sicherheit und die geschäftliche Bedeutung der Erstellung von hochwertigem, robustem Code, der einfach zu warten und zu aktualisieren ist, machen die Codierungsstandards jedoch für alle Entwicklungsvorgänge entscheidend.
Um sicherzustellen, dass Fehler gar nicht erst in den Code eingeführt werden, müssen Entwicklungsteams:
- verringern Sie die Notwendigkeit für umfangreiches Debugging,
- bessere Kontrolle über den Zeitplan und
- Kontrollieren Sie den ROI, indem Sie die Gesamtkosten senken.
Die Codeprüfung bietet eine Toolbox mit enormen potenziellen Vorteilen.
Ein Pfund Heilung mit Testwerkzeugen
Während die Codeprüfung viele Probleme löst, können Anwendungsfehler nur gefunden werden, indem getestet wird, ob das Produkt tut, was es tun soll, und das bedeutet, dass es Anforderungen stellt. Um Anwendungsfehler zu vermeiden, müssen sowohl das richtige Produkt als auch das richtige Produkt entwickelt werden.
Das richtige Produkt zu konzipieren bedeutet, im Vorfeld Anforderungen festzulegen und die bidirektionale Nachvollziehbarkeit zwischen den Anforderungen und dem Quellcode sicherzustellen, damit jede Anforderung umgesetzt wird und jede Softwarefunktion auf eine Anforderung zurückgeführt wird. Jede fehlende oder unnötige Funktionalität – die eine Anforderung nicht erfüllt – ist ein Anwendungsfehler. Das Entwerfen des Produktrechts ist der Prozess der Bestätigung, dass der entwickelte Systemcode die Projektanforderungen erfüllt. Das erreichen Sie, indem Sie anforderungsbasierte Tests durchführen.
Abbildung 5 zeigt ein Beispiel für die bidirektionale Rückverfolgbarkeit. Die einzelne ausgewählte Funktion verfolgt stromaufwärts von der Funktion zu einer Anforderung auf niedriger Ebene, dann zu einer Anforderung auf hoher Ebene und schließlich zu einer Anforderung auf Systemebene.
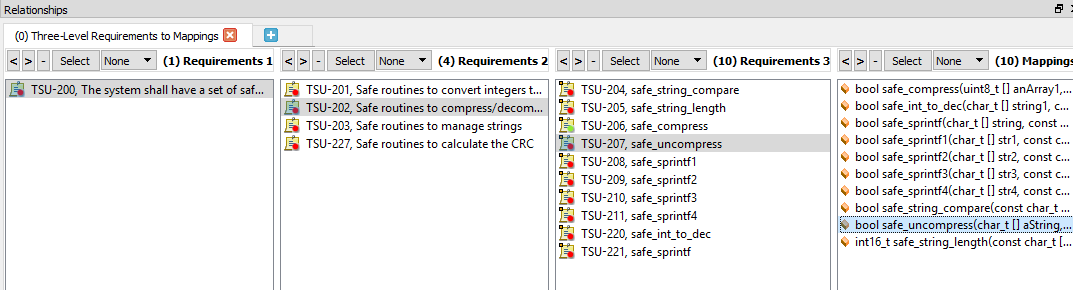
Abbildung 5. Dies ist ein Beispiel für die bidirektionale Rückverfolgbarkeit mit einer einzelnen ausgewählten Funktion. Quelle:LDRA
Abbildung 6 zeigt, wie die Auswahl einer High-Level-Anforderung sowohl die Upstream-Rückverfolgbarkeit zu einer System-Level-Anforderung als auch die Downstream- zu Low-Level-Anforderungen und weiter zu Quellcodefunktionen anzeigt.
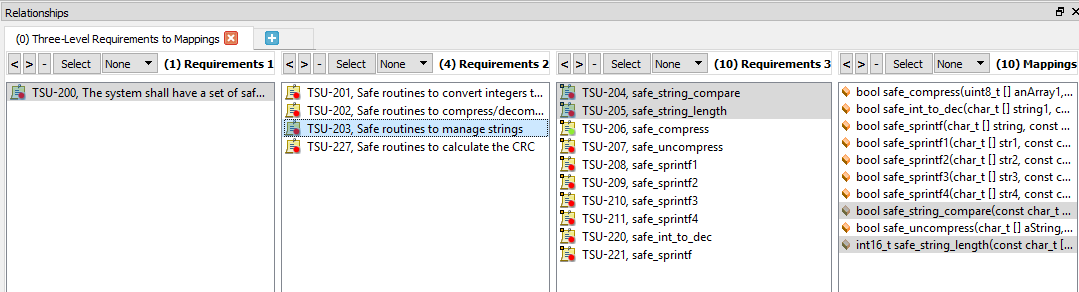
Abbildung 6. Dies ist ein Beispiel für die bidirektionale Rückverfolgbarkeit mit ausgewählten Anforderungen. Quelle:LDRA
Diese Möglichkeit, die Rückverfolgbarkeit zu visualisieren, kann dazu führen, dass Anwendungsfehler frühzeitig im Lebenszyklus erkannt werden.
Das Testen der Codefunktionalität erfordert ein Bewusstsein dafür, was sie tun soll, und das bedeutet, dass Low-Level-Anforderungen vorliegen, die angeben, was jede Funktion tut. Abbildung 7 zeigt ein Beispiel für eine Low-Level-Anforderung, die in diesem Fall eine einzelne Funktion vollständig beschreibt.
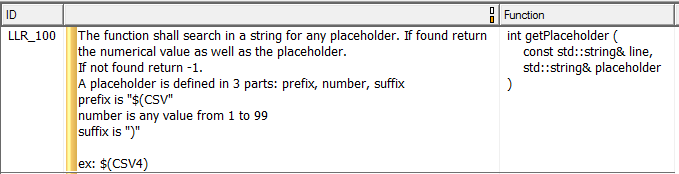
Abbildung 7. Dies ist ein Beispiel für eine Low-Level-Anforderung, die eine einzelne Funktion beschreibt. Quelle:LDRA
Testfälle werden aus Low-Level-Anforderungen abgeleitet, wie in Abbildung 8 dargestellt.
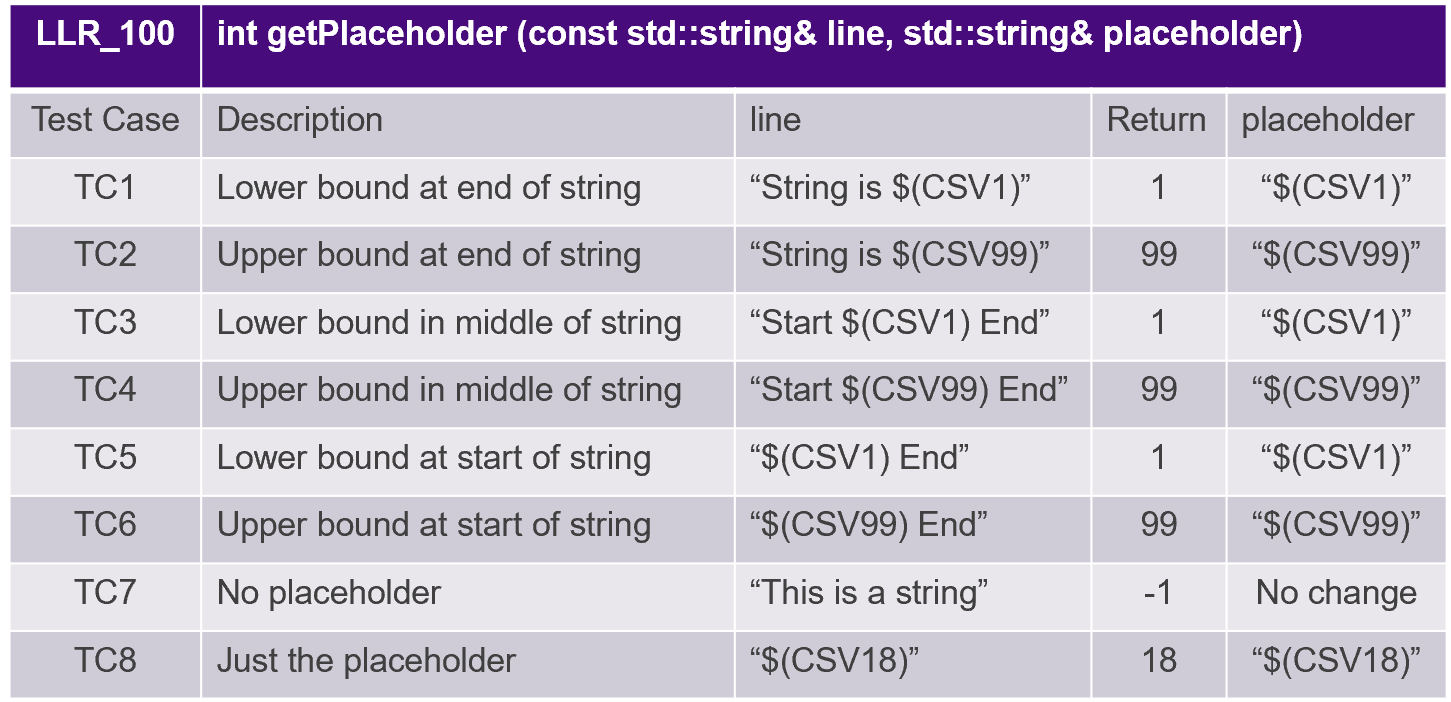
Abbildung 8. Testfälle werden aus Low-Level-Anforderungen abgeleitet. Quelle:LDRA
Mit einem Unit-Test-Tool können diese Testfälle dann auf dem Host oder dem Ziel ausgeführt werden, um sicherzustellen, dass sich der Code so verhält, wie es die Anforderung vorgibt. Abbildung 9 zeigt, dass alle Testfälle regressiert und bestanden wurden.
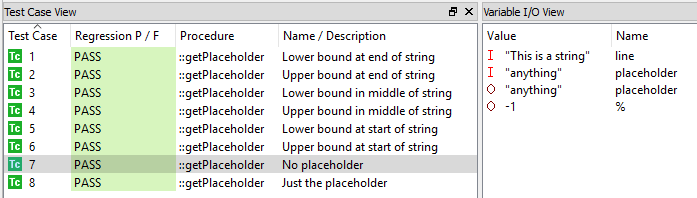
Abbildung 9. So führt ein Tool Komponententests durch. Quelle:LDRA
Nachdem Testfälle ausgeführt wurden, sollte die strukturelle Abdeckung gemessen werden, um sicherzustellen, dass der gesamte Code ausgeführt wurde. Wenn die Abdeckung nicht 100 % beträgt, sind möglicherweise entweder mehr Testfälle erforderlich oder überflüssiger Code sollte entfernt werden.
Neue Gewohnheiten beim Programmieren
Keine Frage, die Softwarekomplexität – und ihre Fehler – sind mit Konnektivität, schnellerem Speicher, umfangreichen Hardwareplattformen und spezifischen Kundenanforderungen wie Pilze aus dem Boden geschossen. Die Einführung eines hochmodernen Codierungsstandards, das Messen von Codemetriken, das Nachverfolgen von Anforderungen und die Implementierung anforderungsbasierter Tests bieten Entwicklungsteams die Möglichkeit, qualitativ hochwertigen Code zu erstellen und die Haftung zu reduzieren.
Das Ausmaß, in dem ein Team diese neuen Gewohnheiten annimmt, wenn keine Standards Compliance erfordern, hängt davon ab, ob das Unternehmen die damit verbundenen Veränderungen anerkennt. Unabhängig davon, ob ein Produkt sicherheits- oder sicherheitskritisch ist, kann die Anwendung dieser Praktiken Tag und Nacht einen Unterschied in der Wartbarkeit und Robustheit des Codes machen. Sauberer Code vereinfacht das Hinzufügen neuer Funktionen, erleichtert die Produktwartung und hält Kosten und Zeitpläne auf ein Minimum – alles Eigenschaften, die den ROI Ihres Unternehmens verbessern.
Unabhängig davon, ob ein Produkt sicherheitskritisch ist oder nicht, dies ist sicherlich ein Ergebnis, das nur für das Entwicklungsteam von Vorteil sein kann.
>> Dieser Artikel wurde ursprünglich veröffentlicht am unsere Schwesterseite EDN.
Eingebettet
- Sind Textzeichenfolgen eine Schwachstelle in eingebetteter Software?
- SOAFEE-Architektur für Embedded Edge ermöglicht softwaredefinierte Autos
- Pixus:neue dicke und robuste Frontplatten für eingebettete Boards
- Kontron:neuer Embedded Computing Standard COM HPC
- GE Digital führt neue Asset-Management-Software ein
- Wie man beim Lehren neuer Software nicht scheitert
- Softwarerisiken:Sicherung von Open Source im IoT
- Drei Schritte zur Sicherung der Softwarelieferketten
- Saelig veröffentlicht neuen Embedded-PC von Amplicon
- Einsatz von DevOps zur Bewältigung von Herausforderungen mit eingebetteter Software