


KI-fähige SoCs verarbeiten mehrere Videostreams
Ambarella bringt zwei Geräte für Computer Vision und KI-Verarbeitung von mehreren oder einzelne Eingänge in Sicherheitskameras und Smart City-Systemen.
Der Bildverarbeitungsspezialist Ambarella hat zwei neue SoCs für Einzel- und Mehrfachsensor-Sicherheitskameras auf den Markt gebracht, die jeweils über neue KI-Funktionen verfügen, die durch die CVflow-KI-Beschleuniger-Engine des Unternehmens ermöglicht werden. Beide unterstützen 4K-Videokodierung und fortschrittliche KI-Verarbeitung wie Gesichtserkennung oder Nummernschilderkennung.
Der CV5S SoC zielt auf Multisensor-Kamerasysteme ab und codiert vier Imager-Kanäle mit einer Auflösung von bis zu 8 MP/4K mit jeweils 30 Bildern pro Sekunde (fps) und führt gleichzeitig fortschrittliche KI für jeden 4K-Bildstream durch. Es kann bis zu 14 Eingänge verarbeiten. Die SoC-Familie verdoppelt die Codierungsauflösung und Speicherbandbreite der vorherigen Produktgeneration von Ambarella und verbraucht dabei 30 Prozent weniger Strom. Es verbraucht <5 W und bietet 12 eTOPS (GPU-äquivalente TOPS, Ambarellas Maß für die Menge an GPU-Leistung, die erforderlich ist, um dieselben KI-Verarbeitungsaufgaben auszuführen).
Der andere neue SoC, CV52S, zielt auf Single-Sensor-Kameras ab und unterstützt 4K-Auflösung bei 60 fps. Im Vergleich zu früheren Generationen von Ambarella SoCs vervierfacht dieses neue Gerät die KI-Leistung, verdoppelt den CPU-Durchsatz und bietet 50 Prozent mehr Speicherbandbreite. Es verbraucht <3 W und bietet 6 eTOPS.
Die Leistungssteigerung ergibt sich aus der Migration zum 5-nm-Prozessknoten zusammen mit Verbesserungen und Erweiterungen des hauseigenen CVflow-KI-Beschleunigerblocks von Ambarella.
„Sie sehen all diese Startups, die von überall her kommen und sagen, dass sie die beste KI-Leistung pro Watt haben, und sie haben möglicherweise Recht“, sagte Jerome Gigot, Senior Director of Marketing bei Ambarella. „Aber das macht keine Kamera, das macht kein Produkt. Wenn Sie nur einen KI-Beschleuniger haben, haben Sie nur einen KI-Beschleuniger.“
Gigot merkte an, dass eine Imaging-Pipeline für 4K- oder 8K-Video komplex ist, eine große Datenmenge verarbeitet, große Datenmengen codiert und diese Daten an einen speziellen Block für die KI-Verarbeitung überträgt, während wahrscheinlich ein Linux-Stack darauf ausgeführt wird. Das ist bei niedrigen Energiebudgets bei gleichzeitiger Beibehaltung der Videoqualität schwer zu erreichen.
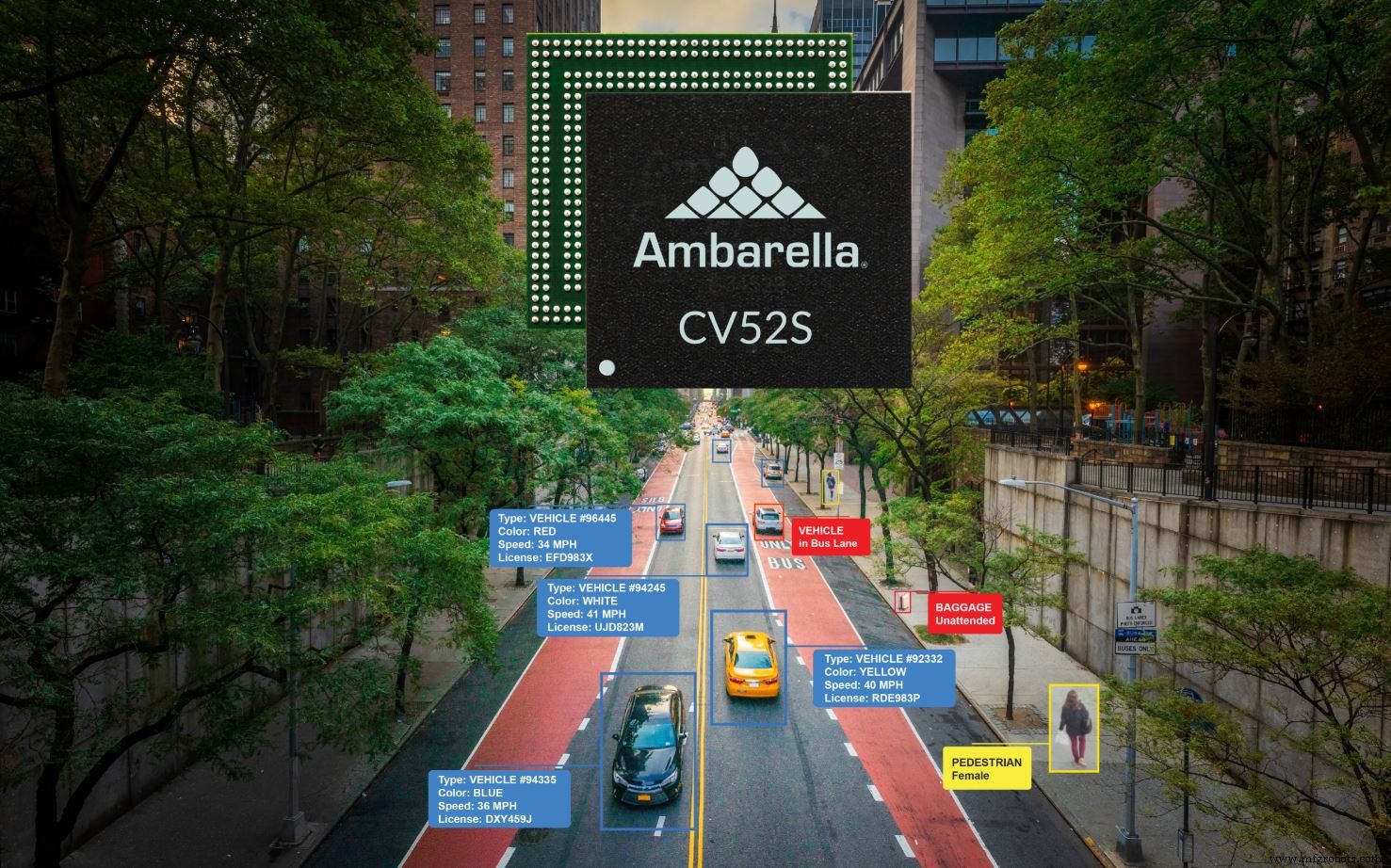
Der CV52S zielt auf Einzelsensor-Designs ab, wie sie in der Verkehrsüberwachung und anderen Smart-City-Anwendungen zu finden sind (Quelle:Ambarella)
Neben dem CVflow AI-Beschleuniger enthalten beide neuen SoCs den Bildsignalprozessor (ISP) von Ambarella, der Funktionen wie Farbverarbeitung, automatische Belichtung, automatischer Weißabgleich und Rauschfilterung handhabt.
„Diesen Block entwickeln wir seit 16 Jahren“, sagt Gigot. „Deshalb denken wir, dass Startups noch einen langen Weg vor sich haben. Sie könnten [einen ISP-Block von woanders] lizenzieren, aber dann ist er in Bezug auf den Speicherzugriff und alles andere nicht wirklich in den Rest des Systems integriert.“
Das Speichersystem gehört zu den wichtigsten IP-Elementen des Unternehmens.
„Wir haben einen Speichercontroller und orchestrieren das Ganze so, dass wir Daten auf dem Chip erhalten. Wir versuchen, keine Kopien zu machen“, sagte Gigot. „Wir verschieben Zeiger, wir verschieben keine Daten. Das ist nur möglich, wenn Sie die gesamte Architektur von Grund auf neu entwerfen und genau wissen, was der Chip tun wird.“
Beschleuniger-Motor
Der KI-Beschleuniger ist ein Vektorprozessor, der die Faltung und andere gängige KI-Funktionen beschleunigen oder für klassische Computer-Vision-Workloads verwendet werden kann. Benutzer können auch wählen, ob sie Teile eines neuronalen Netzwerks (wie Sortieralgorithmen in einem Single-Shot-Detektor-Netzwerk) oder über eine auf dem Chip integrierte Dual-Core-Arm-Cortex-A76-CPU ausführen möchten.
Der Software-Stack ermöglicht es Anwendungen, die Koeffizientensparsität zu nutzen, eine Technik, bei der Netzwerkkoeffizienten mit Werten nahe Null auf Null abgerundet werden. Der Ansatz kann ganze „Zweige“ von Berechnungen aus dem Algorithmus „beschneiden“, um den Rechenaufwand erheblich zu reduzieren.
Sparsifizierung "ist für uns eine wirklich effektive Technik, denn wenn es einen Nullkoeffizienten gibt, führen wir in unserer Architektur die Operation nicht durch, wir haben eine Sprungfunktion", sagte er. „Also berechnen wir das Ergebnis für diesen Koeffizienten nicht. Wir brauchen so ziemlich null Zyklen.“
Der Prozess identifiziert in der Regel 50 bis 80 Prozent der Koeffizienten als Ziele für die Sparsifizierung, sagte Gigot. Nach der Sparsifizierung ist in der Regel eine geringfügige Umschulung erforderlich, um die während des Prozesses verlorene Vorhersagegenauigkeit wiederzuerlangen. Laut Gigot kann eine Umschulung die Genauigkeit in der Regel auf bis zu 1 Prozent des Originalmodells bringen – ein akzeptabler Kompromiss für die meisten Kunden, insbesondere bei einer bis zu 5-fachen Modellverkleinerung. Ambarella arbeitet auch an Sparsifizierungs- und Quantisierungstools, die architekturbewusster sind.
Klick für Bild in voller Größe
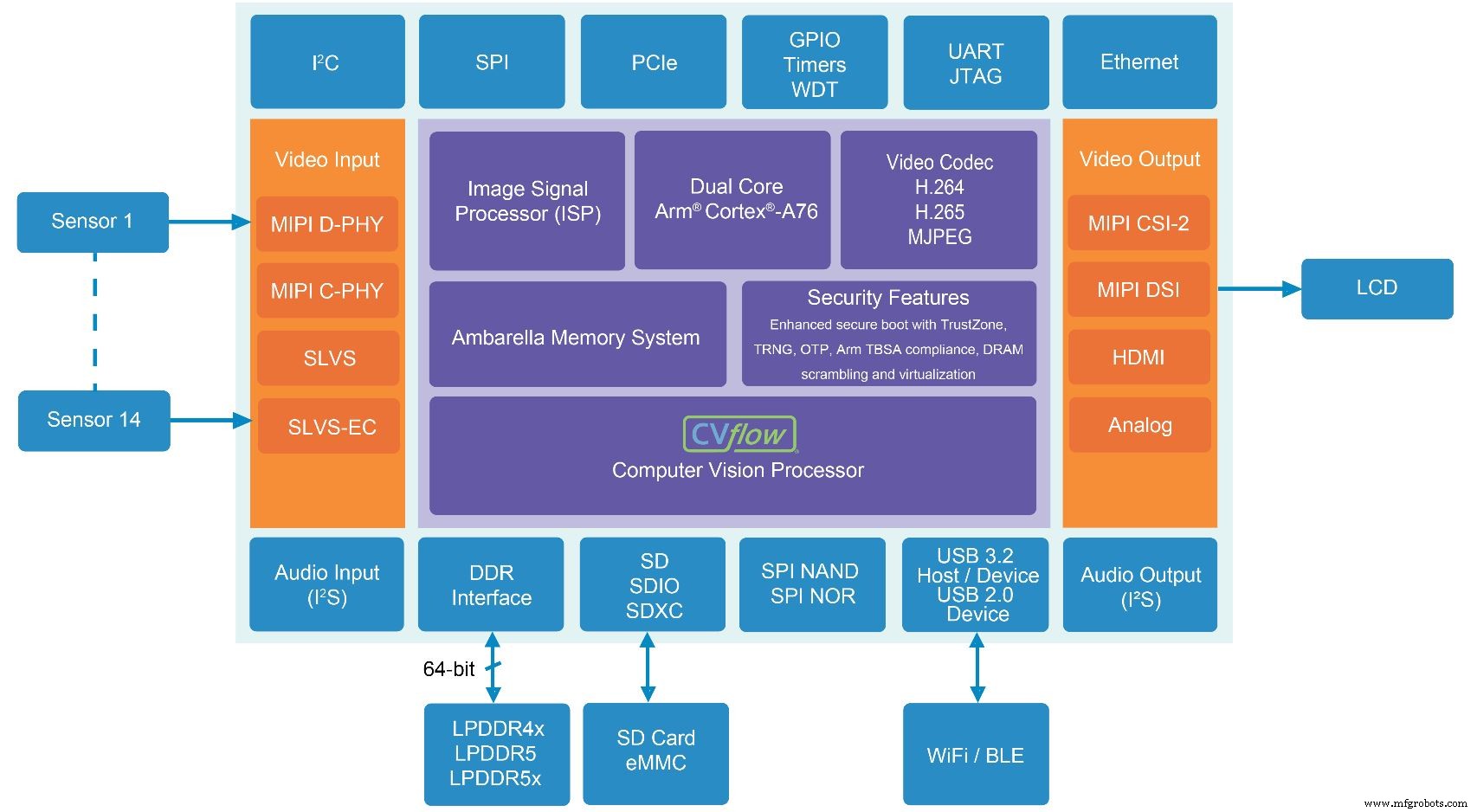
Der CV5S SoC für Multisensor-Kamerasysteme enthält die neueste Generation von Ambarellas CVflow AI und Computer Vision Accelerator (Quelle:Ambarella)
Werden Kunden mit der Möglichkeit, bis zu 14 Videostreams zu akzeptieren und dann gleichzeitig KI für diese Streams auszuführen, mehrere neuronale Netze gleichzeitig betreiben? Wird eine Art Multiplexing-Schema erforderlich sein?

Jerome Gigot (Quelle:Ambarella)
Ja zu beiden, antwortete Gigot. „Der CVflow ist eine sehr schnelle Vektor-Engine, eine sehr schnelle Faltungs-Engine. Alles ist zeitgemultiplext. Wir haben unterschiedliche Hardwarepfade, damit wir Vorgänge parallelisieren können, aber wir binden es nicht an ein bestimmtes Netzwerk, [das] völlig anders ist als die Stapelverarbeitung auf einer GPU.“
Stapelverarbeitung, eine Technik, die häufig von großen GPUs verwendet wird, gruppiert Bilder und sendet sie zur parallelen Verarbeitung. GPUs haben bereits andere Parameter geladen. Dieser Ansatz reduziert die Rechenkosten, da nicht zwischen Operationen gewechselt werden muss.
Für kleinere Engines wie CVflow müssen größere neuronale Netze zur Verarbeitung in Stücke zerlegt werden, da der Speicher des Chips nicht alle Parameter auf einmal speichern kann. Aufeinanderfolgende Chunks können von demselben neuronalen Netzwerk oder einem anderen Netzwerk oder einer anderen Kanaleingabe stammen. Die typische Hardwareauslastung bei CVflow liegt zwischen 70 und 80 Prozent, sagte Gigot und fügte hinzu, dass das Wechseln von Netzwerken/Kanälen die Effizienz nicht beeinträchtigt.
Der CV5S und CV52S werden voraussichtlich im Oktober 2021 mit der Bemusterung beginnen.
>> Dieser Artikel wurde ursprünglich auf unserer Schwesterseite EE published veröffentlicht Zeiten.
Verwandte Inhalte:
- KI-Vision-Prozessor ermöglicht 8K-Video mit 30 fps in weniger als 2 W
- Ambarella zielt mit neuem Kamera-SoC auf intelligente Kantenerkennung ab
- FPGAs ersetzen ASICs in den Vision-basierten ADAS von Subaru Eyesight
- Arm fügt CPU, GPU und ISP für autonome und visuelle Sicherheit hinzu
- Das energiesparende KI-Vision-Board hält mit einer einzigen Batterie "Jahre"
Für mehr Embedded, abonnieren Sie den wöchentlichen E-Mail-Newsletter von Embedded.
Eingebettet
- Java fängt mehrere Ausnahmen ab
- Mikrochip:PolarFire FPGA-basierte Lösung ermöglicht 4K-Video- und Bildbearbeitung in kleinstem Formfaktor
- Rutronik:drahtlose Multiprotokoll-SoCs und -Module von Redpine Signals
- Renesas:Full-HD-LCD-Videocontroller mit MIPI-CSI2-Eingang
- Die Verwendung mehrerer Inferenzchips erfordert eine sorgfältige Planung
- Erweiterte SoCs bringen grundlegende Veränderungen in medizinische IoT-Designs
- Videoprozessor ermöglicht 4K-Videocodierung für batteriebetriebene Designs
- Abaco Systems:robuste XMC-Grafik- und Videoplatine
- Portwell:19-Zoll-System zielt auf Videowandanwendungen ab
- Kleines Modul integriert mehrere Biosensoren