


Bekämpfung von Trainingsverzerrungen beim maschinellen Lernen
Jedermann über „Fairness“ beizubringen, ist ein lobenswertes Ziel.
Als Menschen sind wir uns möglicherweise nicht unbedingt einig, was fair ist. Es hängt manchmal vom Kontext ab. Kindern beizubringen, fair zu sein – sowohl zu Hause als auch in der Schule – ist grundlegend, aber leichter gesagt als getan. Wie können wir vor diesem Hintergrund als Gesellschaft die Nuancen der „Fairness“ gegenüber Systemen der künstlichen Intelligenz (KI) kommunizieren?
Ein Forscherteam von IBM Research geht dieses Rätsel zum ersten Mal an. IBM führt ein Toolkit für Entwickler namens „AI Fairness 360“ ein. Als Teil dieser Bemühungen bietet IBM Unternehmen einen neuen „Cloud-basierten Service zur Erkennung von Verzerrungen und zur Risikominderung“ an, mit dem Unternehmen das Verhalten KI-gesteuerter Systeme testen und überprüfen können.
In einem Telefoninterview mit der EE Times sagte uns Saska Mojsilovic, Fellow bei IBM Research, dass sich Wissenschaftler und KI-Praktiker viel zu sehr auf die Genauigkeit von KI konzentriert haben. Normalerweise ist die erste Frage, die Menschen zu KI stellen, „Können Maschinen Menschen besiegen?“
Aber wie sieht es mit Fairness aus? Die Gerechtigkeitslücke in der KI kann katastrophale Folgen haben, beispielsweise im Gesundheitswesen oder bei autonomen Fahrzeugen, sagte sie.
Was ist, wenn ein Datensatz, der zum Trainieren einer Maschine verwendet wird, verzerrt ist? Wenn KI nicht erklären kann, wie es zu einer Entscheidung kam, wie könnten wir dann ihre „Richtigkeit“ überprüfen? Kann KI aufdecken, ob Daten während der KI-Verarbeitung irgendwie manipuliert wurden? Könnte KI uns versichern, dass ihre Daten niemals angegriffen oder kompromittiert wurden, auch während der Vor- und Nachbearbeitung?
Kurz gesagt, gibt es so etwas wie introspektive KI? Die einfache Antwort:Nein.
Ohne Transparenz für KI-Benutzer, Entwickler und Praktiker können KI-Systeme kein Vertrauen der Gesellschaft gewinnen, sagte Mojsilovic.
Zersetzung von Fairness
Eine größere Frage ist, wie man der Maschine beibringt, was Fairness ist. Mojsilovic bemerkte:„Da wir Wissenschaftler sind, haben wir als erstes die ‚Fairness‘ zerlegt. Wir mussten uns darum kümmern.“ Sie haben die Fairness in Bezug auf Metriken, Algorithmen und Voreingenommenheit, die bei der KI-Implementierung praktiziert werden, aufgebrochen.
Kush Varshney, Research Scientist bei IBM, erklärte, dass das Team Voreingenommenheit und Fairness bei KI-Algorithmen und KI-Entscheidungsfindungen untersucht habe. „Es gibt Fairness gegenüber Einzelpersonen und Fairness gegenüber Gruppen. Wir haben uns verschiedene Attribute von Gruppen angesehen – von Geschlecht bis Rasse. Auch rechtliche und regulatorische Fragen werden berücksichtigt.“ Am Ende hat das Team 30 verschiedene Metriken gemessen, um nach Verzerrungen in Datensätzen, KI-Modellen und Algorithmen zu suchen.
Diese Erkenntnisse fließen in die AI Fairness 360-Toolbox ein, die IBM diese Woche auf den Markt gebracht hat. Das Unternehmen beschrieb es als „ein umfassendes Open-Source-Toolkit von Metriken, um auf unerwünschte Verzerrungen in Datensätzen und Modellen für maschinelles Lernen zu prüfen.“
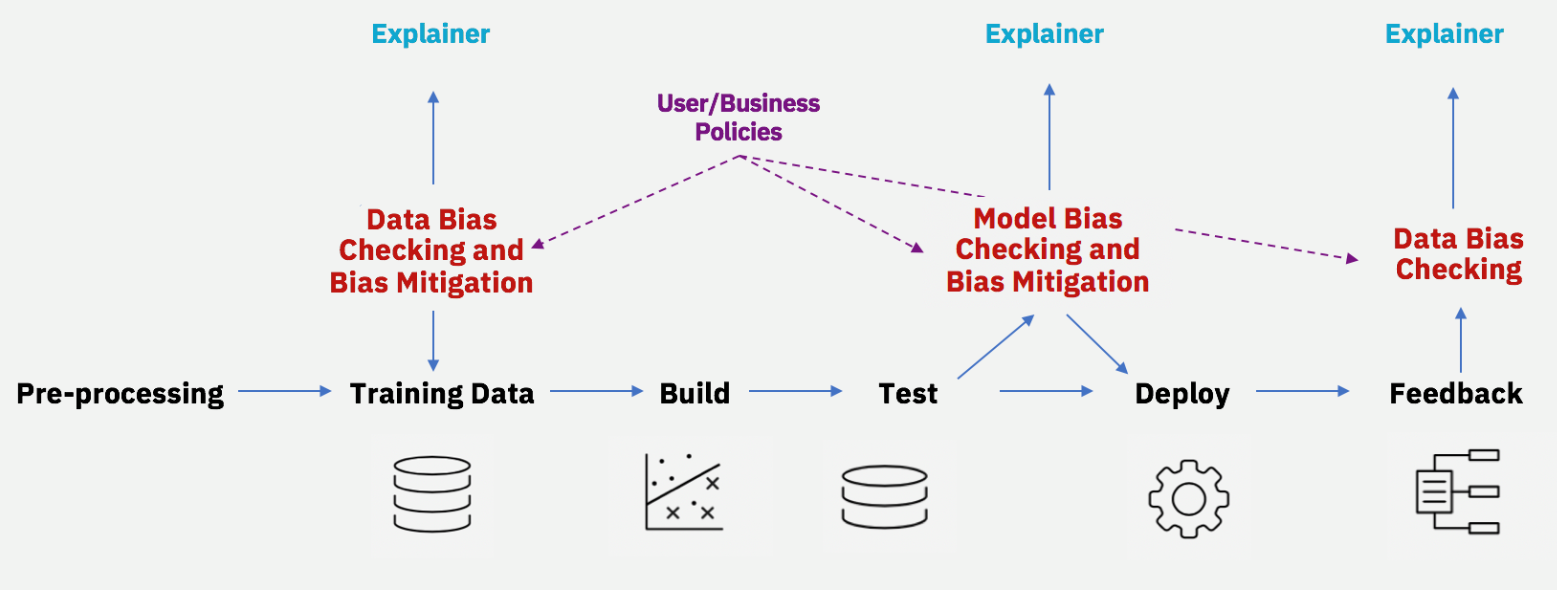
Verzerrung von Verzerrungen während des gesamten KI-Lebenszyklus (Quelle:IBM)
Obwohl viele Wissenschaftler bereits daran arbeiten, Diskriminierung in KI-Algorithmen zu erkennen, sagt Mojsilovic, dass sich der Ansatz von IBM dadurch unterscheidet, dass er Algorithmen einschließt, die nicht nur Bias finden, sondern auch ein Werkzeug zum Debiasing.
Grundsätzlich muss man sich fragen:Informatiker – Fairness definieren? Dies ist eine Aufgabe, die normalerweise Sozialwissenschaftlern zugewiesen wird? Im Bewusstsein dieser Inkongruenz stellte IBM klar, dass weder Mojsilovic noch Varshney in einem Vakuum arbeiten. Sie brachten eine Vielzahl von Gelehrten und Instituten mit. Varshney nahm an der Uehiro-Carnegie-Oxford Ethics Conference teil, die vom Carnegie Council for Ethics in International Affair gesponsert wurde. Mojsilovic nahm an einem KI-Workshop in Berkeley, Kalifornien, teil, der von der UC Berkeley Law School gesponsert wurde.
Ist ein Algorithmus neutral?
Sozialwissenschaftler weisen schon seit einiger Zeit auf das Problem der KI-Verzerrung hin.
Young Mie Kim, Professorin an der School of Journalism and Mass Communication an der University of Wisconsin-Madison, erklärte:„KI-Diskriminierung (oder KI-Bias) kann auftreten, wenn sie implizit oder explizit bestehende ungleiche soziale Ordnungen und Vorurteile (z. B. Geschlecht, Rasse, Alter, sozialer/wirtschaftlicher Status usw.).“ Die Beispiele reichen von Stichprobenfehlern (z. B. Unterrepräsentation bestimmter demografischer Merkmale aufgrund unangemessener oder schwieriger Stichprobenmethoden) bis hin zu menschlichen Verzerrungen beim maschinellen Training (Modellierung). Kim argumentierte, dass KI-Bias auch bei „strategischen Entscheidungen“ in Design oder Modellierung bestehen, wie etwa bei Algorithmen für politische Werbung.
In ihrer aktuellen Studie mit dem Titel „Algorithmic Opportunity:Digital Advertising and Inequality of Political Involvement“ zeigte Kim, wie Ungleichheit bei algorithmischen Entscheidungen verstärkt werden kann.
Die Fachwelt könnte argumentieren, dass „ein Algorithmus neutral ist“ oder „gebildet“ (trainiert) werden kann. Kim merkte an:„Damit wird nicht anerkannt, dass in irgendeiner Phase der Algorithmusentwicklung Vorurteile auftreten.“
Internet der Dinge-Technologie
- Maschinelles Lernen auf AWS; Alles wissen
- Die Lieferkette und maschinelles Lernen
- Maximierung der Effektivität des Zuverlässigkeitstrainings
- Mobius führt Trainingssoftware für den Maschinenausgleich ein
- NXP verdoppelt maschinelles Lernen am Edge
- So verwenden Sie maschinelles Lernen in der heutigen Unternehmensumgebung
- Maschinelles Lernen im Feld
- Bewältigung der PID-Lernkurve
- Maschinelles Lernen in der vorausschauenden Wartung
- Akkulebensdauer mit maschinellem Lernen vorhersagen