


Mikrocontroller spielen eine wachsende Rolle in der Edge-KI
Noch vor wenigen Jahren ging man davon aus, dass Machine Learning (ML) – und sogar Deep Learning (DL) – nur auf High-End-Hardware durchgeführt werden kann, wobei Training und Inferenz am Edge von Gateways, Edge-Servern oder Daten ausgeführt werden Zentren. Dies war damals eine gültige Annahme, da der Trend zur Verteilung von Rechenressourcen zwischen Cloud und Edge noch am Anfang stand. Aber dieses Szenario hat sich dank intensiver Forschungs- und Entwicklungsanstrengungen von Industrie und Wissenschaft dramatisch verändert.
Das Ergebnis ist, dass heute Prozessoren, die viele Billionen von Operationen pro Sekunde (TOPS) liefern können, nicht erforderlich sind, um ML auszuführen. In immer mehr Fällen können die neuesten Mikrocontroller, einige mit eingebetteten ML-Beschleunigern, ML auf Edge-Geräte bringen.
Diese Geräte können nicht nur ML ausführen, sondern auch zu geringen Kosten, mit sehr geringem Stromverbrauch und nur dann, wenn es unbedingt erforderlich ist, eine Verbindung zur Cloud herstellen. Kurz gesagt, Mikrocontroller mit integrierten ML-Beschleunigern stellen den nächsten Schritt dar, um Datenverarbeitung auf Sensoren wie Mikrofone, Kameras und solche zur Überwachung von Umgebungsbedingungen zu übertragen, die die Daten generieren, auf denen alle Vorteile des IoT realisiert werden.
Wie tief ist die Kante?
Obwohl der Edge allgemein als der am weitesten entfernte Punkt in einem IoT-Netzwerk angesehen wird, wird er im Allgemeinen als fortschrittliches Gateway oder Edge-Server angesehen. Hier endet die Kante jedoch nicht. Es endet an den Sensoren in der Nähe des Benutzers. Es ist logisch, möglichst viel analytische Kraft in der Nähe des Benutzers zu platzieren, eine Aufgabe, für die Mikrocontroller ideal geeignet sind.
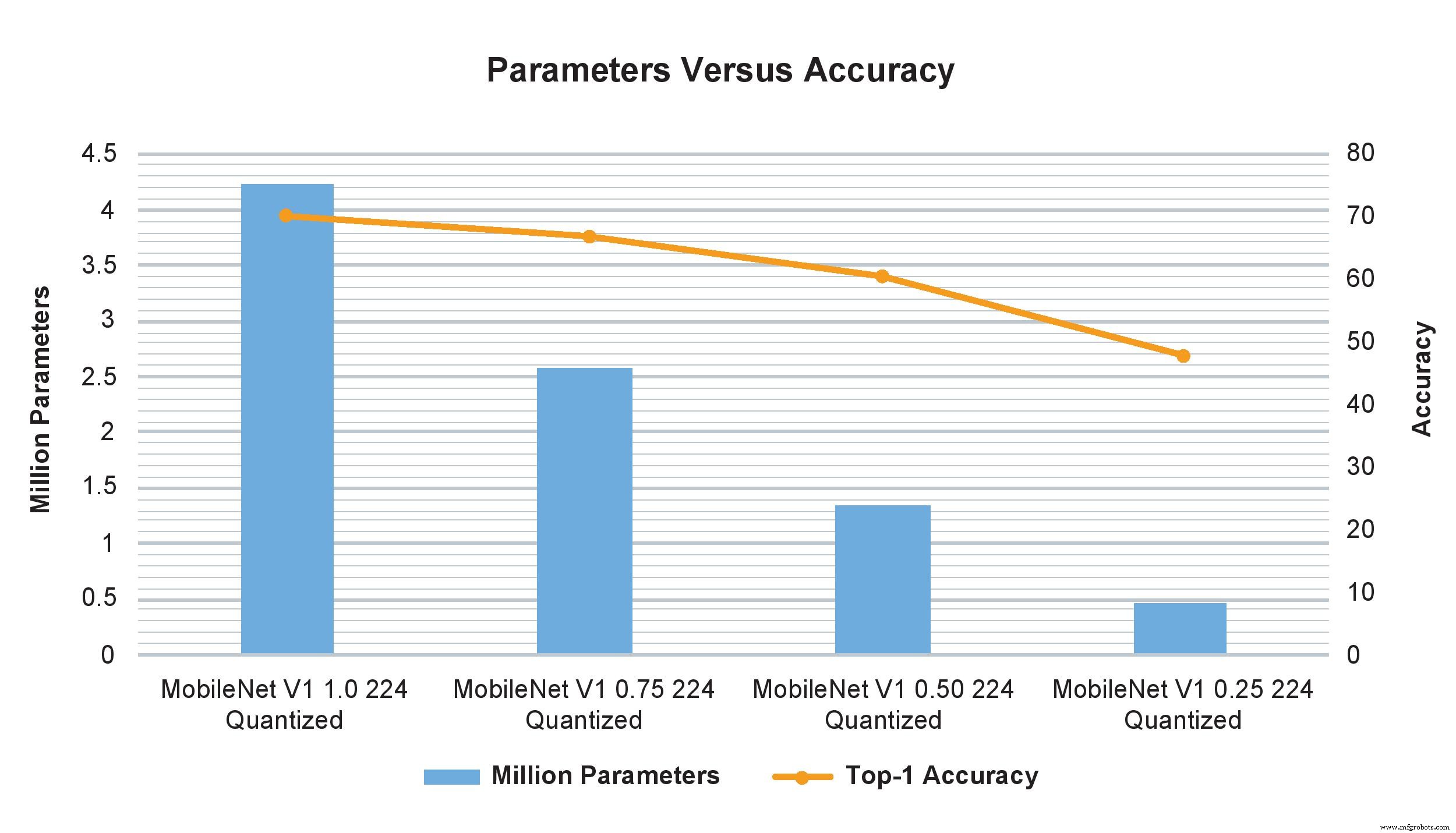
MobileNet V1-Modellbeispiele unterschiedlicher Breitenmultiplikatoren zeigen einen drastischen Einfluss auf die Anzahl der Parameter, Berechnungen und Genauigkeit. Allerdings wirkt sich die bloße Änderung des Breitenmultiplikators von 1,0 auf 0,75 nur minimal auf die TOP-1-Genauigkeit aus, wirkt sich jedoch erheblich auf die Anzahl der Parameter und Berechnungen aus (Bild:NXP)
Man könnte argumentieren, dass Einplatinencomputer auch für Edge-Processing verwendet werden können, da sie eine bemerkenswerte Leistung erbringen und in Clustern mit einem kleinen Supercomputer konkurrieren können. Aber sie sind immer noch zu groß und zu teuer, um in Hunderten oder Tausenden bereitgestellt zu werden, die in großen Anwendungen erforderlich sind. Sie benötigen auch eine externe Gleichstromquelle, die in einigen Fällen das verfügbare übersteigt, während eine MCU nur Milliwatt verbraucht und mit Knopfzellenbatterien oder sogar einigen Solarzellen betrieben werden kann.
Es ist daher nicht verwunderlich, dass das Interesse an Mikrocontrollern für die Durchführung von ML am Edge zu einem sehr heißen Entwicklungsgebiet geworden ist. Es hat sogar einen Namen – TinyML. Das Ziel von TinyML ist es, Inferenz und letztendlich Training auf kleinen, ressourcenbeschränkten Low-Power-Geräten und insbesondere Mikrocontrollern statt auf größeren Plattformen oder in der Cloud auszuführen. Dies erfordert, dass neuronale Netzwerkmodelle in der Größe reduziert werden, um die vergleichsweise bescheidenen Verarbeitungs-, Speicher- und Bandbreitenressourcen dieser Geräte zu bewältigen, ohne die Funktionalität und Genauigkeit signifikant zu reduzieren.
Diese ressourcenoptimierten Schemata ermöglichen es den Geräten, genügend Sensordaten aufzunehmen, um ihren Zweck zu erfüllen, während die Genauigkeit fein abgestimmt und der Ressourcenbedarf reduziert wird. Während also Daten möglicherweise noch an die Cloud gesendet werden (oder vielleicht zuerst an ein Edge-Gateway und dann in die Cloud), werden es viel weniger davon sein, da bereits umfangreiche Analysen durchgeführt wurden.
Ein beliebtes Beispiel für TinyML in Aktion ist ein kamerabasiertes Objekterkennungssystem, das zwar in der Lage ist, hochauflösende Bilder aufzunehmen, aber nur über begrenzten Speicherplatz verfügt und eine Reduzierung der Bildauflösung erfordert. Wenn die Kamera jedoch eine On-Device-Analyse enthält, werden nur die interessierenden Objekte und nicht die gesamte Szene erfasst, und da die relevanten Bilder weniger sind, kann ihre höhere Auflösung beibehalten werden. Diese Fähigkeit wird normalerweise mit größeren, leistungsfähigeren Geräten in Verbindung gebracht, aber die winzige ML-Technologie ermöglicht dies auf Mikrocontrollern.
Klein aber fein
Obwohl TinyML ein relativ neues Paradigma ist, liefert es bereits überraschende Ergebnisse für die Inferenz (selbst mit relativ bescheidenen Mikrocontrollern) und das Training (mit leistungsstärkeren) mit minimalem Genauigkeitsverlust. Jüngste Beispiele sind Sprach- und Gesichtserkennung, Sprachbefehle und die Verarbeitung natürlicher Sprache und sogar die parallele Ausführung mehrerer komplexer Sehalgorithmen.
Praktisch bedeutet dies, dass ein Mikrocontroller, der weniger als 2 US-Dollar kostet, mit einem 500-MHz-Arm-Cortex-M7-Kern und 28 KByte bis 128 KByte Speicher die erforderliche Leistung liefern kann, um Sensoren wirklich intelligent zu machen.
Selbst bei diesem Preis- und Leistungsniveau verfügen diese Mikrocontroller über mehrere Sicherheitsfunktionen, darunter AES-128, Unterstützung für mehrere externe Speichertypen, Ethernet, USB und SPI und entweder enthalten oder unterstützen verschiedene Arten von Sensoren sowie Bluetooth, WLAN und SPDIF und I 2 C-Audio-Interfaces. Wenn Sie etwas mehr ausgeben, verfügt das Gerät normalerweise über einen 1-GHz-Arm-Cortex-M7, einen 400-MHz-Cortex-M4, 2 MB RAM und eine Grafikbeschleunigung. Der Stromverbrauch beträgt normalerweise nicht mehr als einige Milliampere bei einer 3,3-V-Gleichstromversorgung.
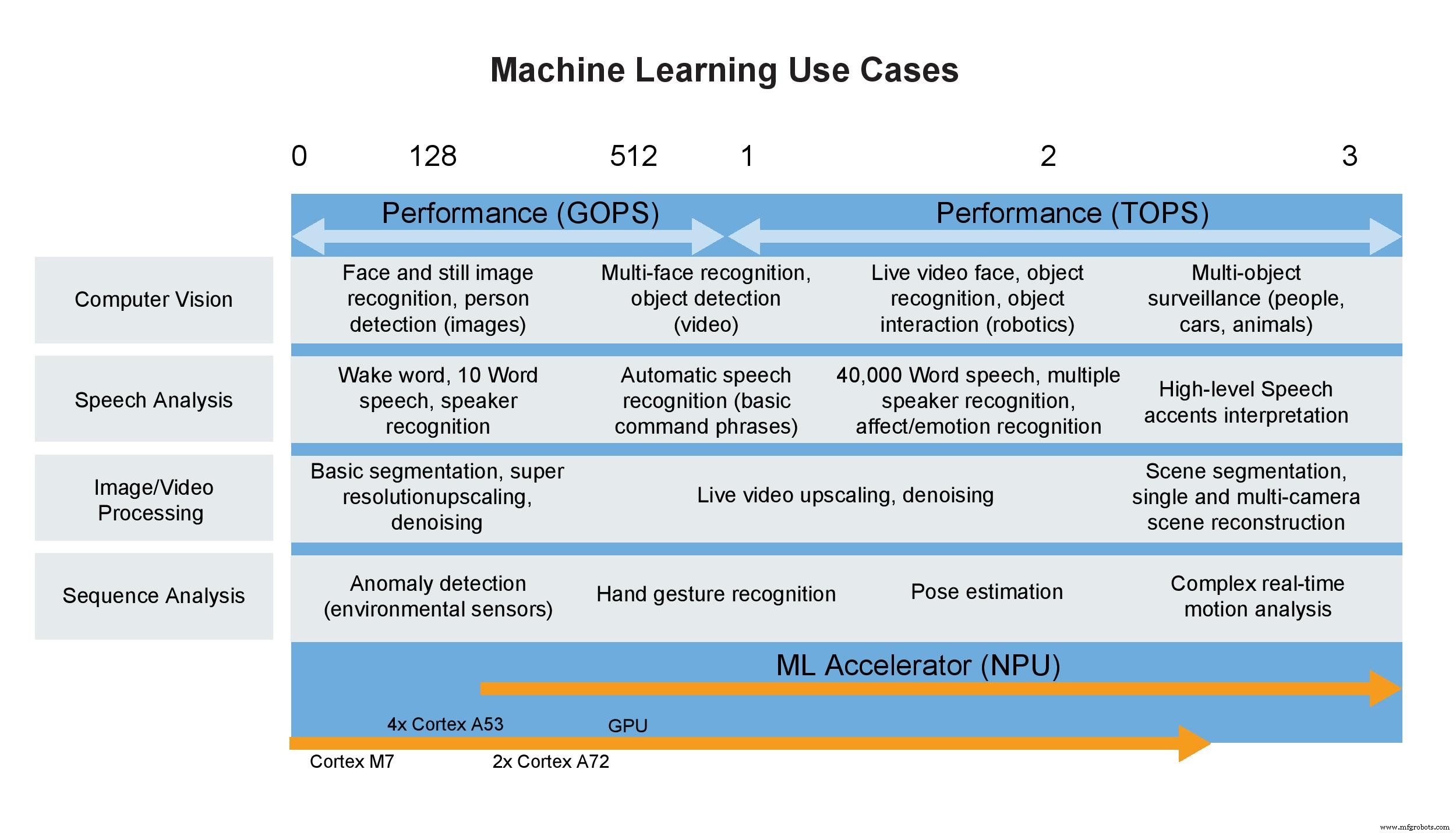
Anwendungsfälle für maschinelles Lernen (Bild:NXP)
Ein paar Worte zu TOPS
Verbraucher sind nicht allein, wenn sie eine einzelne Metrik verwenden, um die Leistung zu definieren. Designer tun es die ganze Zeit und Marketingabteilungen lieben es. Dies liegt daran, dass eine Überschriftsspezifikation die Unterscheidung zwischen Geräten einfach macht, oder so scheint es. Ein klassisches Beispiel ist die CPU, die viele Jahre über ihre Taktrate definiert wurde. Zum Glück sowohl für Designer als auch für Verbraucher ist dies nicht mehr der Fall. Die Verwendung von nur einer Metrik zum Bewerten einer CPU ist vergleichbar mit der Bewertung der Leistung eines Autos anhand der roten Linie des Motors. Es ist nicht bedeutungslos, hat aber wenig damit zu tun, wie stark der Motor ist oder wie gut das Auto fahren wird, da viele andere Faktoren zusammen diese Eigenschaften bestimmen.
Dasselbe gilt leider immer mehr für Beschleuniger für neuronale Netze, auch für solche in Hochleistungs-MPUs oder Mikrocontrollern, die mit Milliarden oder Billionen Operationen pro Sekunde spezifiziert sind, da diese Zahl wiederum leicht zu merken ist. Aber in der Praxis sind GOPS und TOPS allein relativ bedeutungslose Metriken und stellen eine Messung (zweifellos die beste) dar, die in einem Labor durchgeführt wurde, anstatt eine tatsächliche Betriebsumgebung darzustellen. TOPS berücksichtigt beispielsweise nicht die Beschränkungen der Speicherbandbreite, den erforderlichen CPU-Overhead, die Vor- und Nachbearbeitung und andere Faktoren. Wenn all dies und andere berücksichtigt werden, beispielsweise die Leistung bei Verwendung auf einem bestimmten Board im tatsächlichen Betrieb, könnte die Leistung auf Systemebene wahrscheinlich 50 % oder 60 % des TOPS-Werts auf dem Datenblatt betragen.
All diese Zahlen sagen Ihnen die Anzahl der Rechenelemente in der Hardware multipliziert mit ihrer Taktrate, und nicht, wie oft die Daten verfügbar sind, wenn sie funktionieren muss. Wenn die Daten immer sofort verfügbar wären, der Stromverbrauch kein Thema wäre, es keine Speicherbeschränkungen gäbe und der Algorithmus nahtlos auf die Hardware abgebildet würde, wären sie aussagekräftiger. Aber die reale Welt bietet keine solchen idealen Umgebungen.
Bei Anwendung auf ML-Beschleuniger in Mikrocontrollern ist die Metrik noch weniger wertvoll. Diese winzigen Geräte haben normalerweise einen Wert von 1 bis 3 TOPS, können aber dennoch die in vielen ML-Anwendungen erforderlichen Inferenzfähigkeiten liefern. Diese Geräte verlassen sich auch auf Arm Cortex-Prozessoren, die speziell für ML-Anwendungen mit geringem Stromverbrauch entwickelt wurden. Zusammen mit der Unterstützung von Integer- und Floating-Operationen und den vielen anderen Funktionen des Mikrocontrollers wird klar, dass TOPS oder jede andere einzelne Metrik weder allein noch in einem System die Leistung angemessen definieren kann.
Schlussfolgerung
Der Wunsch, Inferenz auf Mikrocontrollern direkt auf oder an Sensoren wie Stand- und Videokameras durchzuführen, entsteht jetzt, da die IoT-Domäne näher daran rückt, so viel Verarbeitung wie möglich am Edge durchzuführen. Das Tempo der Entwicklung von Anwendungsprozessoren und Beschleunigern für neuronale Netze in Mikrocontrollern ist jedoch hoch, und es tauchen häufig kompetentere Lösungen auf. Der Trend geht dahin, mehr KI-zentrierte Funktionen wie neuronale Netzwerkverarbeitung zusammen mit einem Anwendungsprozessor im Mikrocontroller zu konsolidieren, ohne den Stromverbrauch oder die Größe dramatisch zu erhöhen.
Heutzutage können Modelle auf einer leistungsstärkeren CPU oder GPU trainiert und dann mithilfe von Inferenz-Engines wie TensorFlow Lite auf einem Mikrocontroller implementiert werden, um sie zu verkleinern, um die Ressourcenanforderungen des Mikrocontrollers zu erfüllen. Die Skalierung kann leicht durchgeführt werden, um höhere ML-Anforderungen zu erfüllen. Bald sollte es möglich sein, nicht nur Inferencing, sondern auch Training durchzuführen auf diesen Geräten, was den Mikrocontroller effektiv zu einem noch ernsteren Konkurrenten für größere und teurere Computerlösungen macht.
>> Dieser Artikel wurde ursprünglich veröffentlicht am unsere Schwesterseite EE Times.
Eingebettet
- Rolle von Cloud Computing in der Intelligenz
- Rolle eingebetteter Systeme in Automobilen
- Die Dampfkammerkühlung spielt eine wachsende Rolle bei heißen Produkten
- RF Energy Harvesting findet eine wachsende Rolle in KI-gesteuerten Anwendungen
- USB-C findet eine wachsende Rolle bei Wearables und mobilen Produkten
- Kleines KI-Modul baut auf Google Edge TPU auf
- Smart Sensor Board beschleunigt die Entwicklung von Edge-KI
- Smart-Kamera bietet schlüsselfertige Edge Machine Vision Edge-KI
- Roboter spielen eine Rolle in der Industrie 4.0
- Die Rolle von Edge Computing in kommerziellen IoT-Bereitstellungen