


Arduino Amiga Diskettenleser (V1)
Komponenten und Verbrauchsmaterialien
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 | |||
 |
| × | 1 |
Apps und Onlinedienste
 |
|
Über dieses Projekt
- Mein Ziel: Um eine einfache, kostengünstige und Open Source-Methode zur Wiederherstellung von Daten von Amiga DD-Disketten innerhalb von Windows 10 und anderen Betriebssystemen zu schaffen.
- Meine Lösung: Ein Arduino + eine Windows-Anwendung
- Warum: Um Daten von diesen Datenträgern für die Zukunft zu bewahren. Außerdem kann ein normaler PC aufgrund der Schreibweise keine Amiga-Disketten lesen.
Projekt-Website:http://amiga.robsmithdev.co.uk/
Dies ist V1 des Projekts. V2 enthält verbessertes Lesen und Schreiben!
Amiga-Erfahrungen
Meine Karriere verdanke ich dem Amiga, genauer gesagt dem A500+, den mir meine Eltern im Alter von 10 Jahren zu Weihnachten gekauft haben. Zuerst habe ich die Spiele gespielt, aber nach einer Weile wurde ich neugierig, was er sonst noch alles kann. Ich spielte mit Deluxe Paint III und lernte Workbench kennen.
Der Amiga 500 Plus:

Jeden Monat kaufte ich das beliebte Magazin im Amiga-Format. Ein Monat hatte eine kostenlose Kopie von AMOS. Ich habe das Amiga-Format eingegeben Spiel in AMOS schreiben Wettbewerb, als AMOS Professional später auf eine Coverdisk gelegt wurde, und war einer der 12 (glaube ich) Gewinner mit In The Pipe Line . Du musstest sie jedoch wirklich um Preise jagen!
AMOS - Der Schöpfer:

Hintergrund
Später habe ich es als Teil meiner GCSEs und A-Level-Projekte verwendet (dank Highspeed Pascal, das mit Turbo Pascal auf dem PC kompatibel war)
Wie auch immer, das ist lange her, und ich habe Kartons mit Festplatten und einen A500+, der nicht mehr funktioniert, also dachte ich darüber nach, diese Festplatten auf meinem Computer zu sichern, sowohl zur Erhaltung als auch zur Nostalgie.
Die Amiga Forever-Website bietet eine ausgezeichnete Liste von Optionen, die Hardware und den Missbrauch von zwei Diskettenlaufwerken in einem PC umfassen - Leider war keine davon mit moderner Hardware eine Option, und die KryoFlux/Catweasel-Controller sind zu teuer. Ich war wirklich überrascht, dass das meiste davon Closed Source war.
Massiv in Elektronik und mit Atmel-Geräten gespielt (AT89C4051 ) während meines Studiums beschloss ich, mir den Arduino anzuschauen (Verdankung an GreatScott für die Inspiration, die zeigt, wie einfach es ist, anzufangen) Ich habe mich gefragt, ob dies möglich ist.
Also habe ich nach Arduino-Diskettenlaufwerk-Lesen gegoogelt Code, und nachdem Sie alle Projekte übersprungen haben, die missbraucht den Drang, Musik abzuspielen, habe ich keine wirklichen Lösungen gefunden. Ich habe einige Diskussionen in einigen Gruppen gefunden, die darauf hindeuteten, dass dies nicht möglich wäre. Ich habe ein Projekt gefunden, das auf einem FPGA basiert, was sehr interessant war, aber nicht die Richtung, in die ich gehen wollte, also bestand die einzige Möglichkeit darin, selbst eine Lösung zu entwickeln.
Forschung
Als ich mit diesem Projekt begann, hatte ich keine Ahnung, wie das Diskettenlaufwerk funktionierte und noch weniger, wie die Daten darauf kodiert wurden. Die folgenden Websites waren für mein Verständnis davon, was passiert und wie sie funktionieren, von unschätzbarem Wert:
- techtravels.org (und diese Seite)
- FAQ zum Format .ADF (Amiga Disk File) von Laurent Clévy
- Für immer Amiga
- Wikipedia - Amiga-Festplattendatei
- Englisches Amiga-Board
- QEEWiki - Zähler auf dem ATmega168/328
- Pinbelegung des Diskettenlaufwerks
- Liste der Diskettenformate
Annahmen
Aufgrund der Recherchen wusste ich nun theoretisch, wie die Daten auf die Platte geschrieben wurden und wie sich die Platte drehte.
Ich fing an, ein paar Zahlen zu berechnen. Basierend auf der Geschwindigkeit der Double Density Disk (300 U/min) und der Art und Weise, wie die Daten gespeichert werden (80 Spuren, 11 Sektoren pro Spur und 512 Byte pro Sektor, mit MFM codiert), musste ich die Daten genau lesen können Abtasten der Daten bei 500 kHz; das ist ziemlich schnell, wenn man bedenkt, dass das Arduino nur mit 16Mhz läuft.
In den folgenden Versuchen spreche ich nur von der Arduino-Seite. Zur Dekodierung springen.
Versuch 1:
Zuerst musste ich die Hardware und die Schnittstelle zum Diskettenlaufwerk zusammenstellen. Das Diskettenlaufwerk habe ich bei der Arbeit von einem alten PC genommen und gleichzeitig das IDE-Kabel gegriffen.
Unten ist ein Foto von befreit Diskettenlaufwerk von einem alten PC:

Beim Studium der Pinbelegung des Laufwerks stellte ich fest, dass ich nur einige der Drähte davon benötigte, und nachdem ich mir das Laufwerk angesehen hatte, stellte ich fest, dass es auch nicht den 12-V-Eingang verwendet.
Das Drehen des Laufwerks wurde erreicht, indem das Laufwerk ausgewählt und der Motor aktiviert wurde. Das Bewegen des Kopfes war einfach. Sie legen /DIR . fest Pin hoch oder niedrig und dann gepulst die /STEP Stift. Sie können feststellen, ob der Kopf Spur 0 (die erste Spur) erreicht hat, indem Sie die /TRK00 . überwachen Stift.
Ich war neugierig auf den /INDEX Stift. Dieser pulst einmal pro Umdrehung. Da der Amiga dies nicht nutzt, um den Anfang des Tracks zu finden, brauchte ich es nicht und konnte es ignorieren. Danach müssen Sie nur noch auswählen, welche Seite der Festplatte gelesen werden soll (/SIDE1 ) und verbinden /RDATA .
Angesichts der hohen Datenratenanforderung war mein erster Gedanke, einen Weg zu finden, dies weniger problematisch zu machen, indem ich versuchte, die Anforderungen an diese Datenrate zu reduzieren.
Geplant war die Verwendung von zwei 8-Bit-Schieberegistern (SN74HC594N ), um die erforderliche Abtastfrequenz um den Faktor 8 zu reduzieren. Ich habe das von Ebay als Pro Mini atmega328 Board 5V 16M Arduino Compatible Nano bezeichnete verwendet (Ich weiß also nicht, was das offiziell ist, aber das funktioniert auf dem Uno!) um dieses Parallel zu puffern Daten und senden Sie diese über die serielle/USART-Schnittstelle an den PC. Ich wusste, dass dies schneller als 500 Kbaud laufen musste (mit dem gesamten seriellen Overhead).
sn74hc594.pdfNachdem ich die standardmäßige serielle Arduino-Bibliothek über Bord geworfen hatte, war ich wirklich erfreut, dass ich das USART auf dem Arduino mit uptp 2M Baud und mit einem dieser F2DI-Breakout-Boards (eBay nannte es Basic Breakout Board For FTDI FT232RL .) konfigurieren konnte USB-zu-Seriell-IC für Arduino - siehe unten) Ich konnte mit dieser Geschwindigkeit (62,5 Khz) glücklich Daten senden und empfangen, aber ich musste dies genau tun.
Atmel-42735-8-bit-AVR-Mikrocontroller-ATmega328-328P_Datasheet.pdfDas FTDI-Breakout-Board, das perfekt zur Schnittstelle des Arduino-Boards passt:

Zuerst habe ich das Arduino verwendet, um auf einem der 8-Bit-Schieberegister nur eines der 8 Bits hoch getaktet einzurichten. Der andere erhielt einen Feed direkt vom Diskettenlaufwerk (und ermöglichte so eine Seriell-Parallel-Konvertierung).
Das Folgende ist ein verrücktes Bild des Steckbretts, auf dem ich das damals aufgebaut habe:

Ich habe einen der Arduinos-Timer verwendet, um ein 500-kHz-Signal an einem seiner Ausgangspins zu erzeugen, und da die Hardware dies verwaltet, ist es sehr genau! - Nun, mein Multimeter hat es trotzdem mit genau 500 kHz gemessen.
Der Code funktionierte, ich taktete volle 8-Bit-Daten bei 62,5 kHz ein, wodurch die Arduino-CPU kaum genutzt wurde. Ich habe jedoch nichts Sinnvolles mitbekommen. An diesem Punkt wurde mir klar, dass ich mir die tatsächlichen Daten, die aus dem Diskettenlaufwerk kommen, genauer ansehen musste. Also kaufte ich ein billiges altes Oszilloskop von eBay (Gould OS300 20Mhz Oszilloskop), um zu sehen, was los war.
Während ich auf die Ankunft des Oszilloskops wartete, beschloss ich, etwas anderes auszuprobieren.
Ein Codefragment, das zum Lesen der Daten aus den Schieberegistern verwendet wird:
void readTrackData() { byte op; for (int a=0; a<5632; a++) { // Wir warten auf die Startmarkierung "Byte" while (digitalRead(PIN_BYTE_READ_SIGNAL)==LOW) {}; // Byte lesen op=0; if (digitalRead(DATA_LOWER_NIBBLE_PB0)==HIGH) op|=1; if (digitalRead(DATA_LOWER_NIBBLE_PB1)==HIGH) op|=2; if (digitalRead(DATA_LOWER_NIBBLE_PB2)==HIGH) op|=4; if (digitalRead(DATA_LOWER_NIBBLE_PB3)==HIGH) op|=8; if (digitalRead(DATA_UPPER_NIBBLE_A0)==HIGH) op|=16; if (digitalRead(DATA_UPPER_NIBBLE_A1)==HIGH) op|=32; if (digitalRead(DATA_UPPER_NIBBLE_A2)==HIGH) op|=64; if (digitalRead(DATA_UPPER_NIBBLE_A3)==HIGH) op|=128; writeByteToUART(op); // Warten Sie, bis das High wieder abfällt, während (digitalRead (PIN_BYTE_READ_SIGNAL) ==HIGH) {}; }}
Versuch 2:
Ich entschied, dass die Schieberegister, obwohl eine nette Idee wahrscheinlich nicht half. Ich konnte problemlos 8 Bits auf einmal lesen, aber mir fiel auf, dass ich nicht sicher sein konnte, ob alle Bits überhaupt richtig eingetaktet wurden. Beim Lesen der Dokumentation ergab sich, dass die Daten eher aus kurzen Impulsen als aus Höhen und Tiefen bestanden.
Ich entfernte die Schieberegister und fragte mich, was passieren würde, wenn ich versuchte, in einem Interrupt (ISR) mit dem zuvor eingerichteten 500-kHz-Signal nach einem Impuls vom Laufwerk zu suchen. Ich habe den Arduino neu konfiguriert, um den ISR zu generieren, und nachdem ich die Probleme mit den Arduino-Bibliotheken bestanden hatte (mit dem ISR, den ich wollte), wechselte ich zu Timer 2.
Ich habe einen kurzen ISR geschrieben, der ein globales einzelnes Byte um ein Bit nach links verschieben würde und dann, wenn der mit der Datenleitung des Diskettenlaufwerks verbundene Pin LOW wäre (die Impulse sind niedrig) Ich würde eine 1 darauf ODER. Alle 8 Mal habe ich das fertige Byte an die USART geschrieben.
Das lief nicht wie erwartet! Der Arduino begann sich sehr unberechenbar und seltsam zu verhalten. Ich stellte bald fest, dass die Ausführung des ISR mehr Zeit in Anspruch nahm als die Zeit zwischen den Aufrufen. Ich könnte alle 2µSek und basierend auf der Geschwindigkeit des Arduino einen Impuls empfangen und eine wilde Annahme machen, dass jeder C-Befehl übersetzt in 1 Takt Maschinencode-Zyklus, Mir wurde klar, dass ich höchstens 32 Anweisungen haben konnte. Leider waren die meisten mehr als eine Anweisung, und nachdem ich gegoogelt hatte, wurde mir klar, dass der Aufwand beim Starten eines ISR sowieso enorm war; ganz zu schweigen davon, dass die digitalRead-Funktionen sehr langsam sind.
Ich habe das digitalRead aufgegeben Funktion zugunsten des direkten Zugriffs auf die Port-Pins! Dies half immer noch nicht und war nicht schnell genug. Nicht bereit aufzugeben, habe ich diesen Ansatz aufgegeben und beschlossen, weiterzumachen und etwas anderes auszuprobieren.
An diesem Punkt kam das Oszilloskop, das ich gekauft hatte, an und es funktionierte! Ein verkrustetes altes Oszilloskop, das wahrscheinlich älter war als ich! Aber hat den Job trotzdem perfekt gemacht. (Wenn Sie nicht wissen, was ein Oszilloskop ist, schauen Sie sich EEVblog #926 - Introduction To The Oszilloskop an, und wenn Sie sich für Elektronik interessieren, dann schlage ich vor, ein paar mehr anzuschauen und auf der EEVBlog-Website zu stöbern.
Mein neu gekauftes krustiges altes Oszilloskop (Gould OS300 20Mhz):

Nachdem man das 500-kHz-Signal an einen Kanal und die Ausgabe vom Diskettenlaufwerk an einen anderen angeschlossen hatte, war offensichtlich, dass etwas nicht stimmte. Das 500-kHz-Signal war eine perfekte Rechteckwelle, die als Trigger verwendet wurde, die Floppy-Daten waren überall. Ich konnte die Impulse sehen, aber es war eher verschwommen. Ebenso war das 500-kHz-Rechtecksignal überall und nicht synchron damit, wenn ich vom Diskettenlaufwerkssignal auslöste.
Fotos der Spuren auf dem Oszilloskop beim Auslösen der beiden Kanäle. Man kann es nicht ganz sehen, aber auf dem Kanal nicht Ausgelöst werden Tausende von schwachen geisterhaften Linien:

Einzeln konnte ich Impulse von beiden Signalen bei 500 Khz messen, was keinen Sinn machte, als ob beide mit der gleichen Geschwindigkeit laufen würden, aber nicht auslösen würden, damit Sie beide Signale richtig sehen können, dann muss etwas nicht stimmen.
Nachdem ich viel mit den Triggerlevels gespielt hatte, gelang es mir herauszufinden, was los war. Mein Signal war ein perfektes 500Khz, aber wenn man sich das Diskettenlaufwerkssignal ansah, waren sie richtig verteilt, aber nicht die ganze Zeit. Zwischen Impulsgruppen gab es eine Fehlerdrift sowie Datenlücken, die das Signal völlig aus dem Takt brachten.
In Erinnerung an die vorherige Forschung sollte das Laufwerk mit 300 U / min rotieren, aber es könnte nicht genau 300 U / min sein, und das Laufwerk, das die Daten geschrieben hat, könnte auch nicht genau 300 U / min haben. Dann gibt es den Abstand zwischen Sektoren und Sektorlücken. Offensichtlich gab es ein Synchronisationsproblem und das Synchronisieren des 500-kHz-Signals mit dem Diskettenlaufwerk zu Beginn eines Lesevorgangs würde nicht funktionieren.
Ich habe auch festgestellt, dass der Impuls vom Diskettenlaufwerk extrem kurz war, obwohl Sie dies durch Ändern des Pullup-Widerstands ändern konnten, und wenn das Timing nicht genau richtig war, könnte der Arduino einen Impuls verpassen.
Als ich an der Universität (University of Leicester) war, belegte ich ein Modul namens Embedded System. Wir haben die Atmel 8051 Mikrocontroller untersucht. In einem der Projekte wurden Impulse einer simulierten Wetterstation (Drehgeber) gezählt. Damals habe ich den Pin in regelmäßigen Abständen abgetastet, aber das war nicht sehr genau.
Der Moduldozent Prof Pont schlug vor, dass ich den Hardwarezähler hätte verwenden sollen Funktionen des Geräts (ich wusste nicht einmal, dass es eines hat.)
Ich habe das Datenblatt für den ATMega328 überprüft und tatsächlich konnte jeder der drei Timer so konfiguriert werden, dass er von einem externen Eingang ausgelöste Impulse zählt. Damit war Geschwindigkeit kein Thema mehr. Alles, was ich eigentlich wissen musste, war, ob ein Puls innerhalb eines Zeitfensters von 2 µSek aufgetreten war.
Versuch 3:
Ich habe die Arduino-Skizze angepasst, um den 500-kHz-Timer zurückzusetzen, wenn der erste Impuls erkannt wurde, und als der 500-kHz-Timer übergelaufen war, überprüfte ich den Zählerwert, um zu sehen, ob ein Impuls erkannt wurde. Ich habe dann dieselbe Bitverschiebungssequenz durchgeführt und alle 8 Bits ein Byte an die USART geschrieben.
Daten kamen herein und ich begann, sie auf dem PC zu analysieren. In den Daten begann ich zu sehen, was wie gültige Daten aussahen. Das ungerade Sync-Wort würde erscheinen oder Gruppen von 0xAAAA-Sequenzen, aber nichts Verlässliches. Ich wusste, dass ich etwas auf der Spur war, aber noch fehlte etwas.
Versuch 4:
Mir wurde klar, dass die Daten vom Laufwerk beim Lesen der Daten wahrscheinlich nicht mehr synchron/phase mit meinem 500-kHz-Signal waren. Ich habe dies bestätigt, indem ich jedes Mal, wenn ich mit dem Lesen begann, nur 20 Byte gelesen habe.
Als ich mich über den Umgang mit diesem Synchronisierungsproblem informiert habe, bin ich über den Begriff Phase Locked Loop oder PLL gestolpert. In sehr einfachen Worten, für das, was wir tun, würde der Phasenregelkreis die Taktfrequenz (die 500 kHz) dynamisch anpassen, um Frequenzdrift und -varianz im Signal zu kompensieren.
Die Auflösung des Timers war nicht hoch genug, um sie um kleine Mengen zu variieren (zB 444khz, 470khz, 500khz, 533khz, 571khz usw.) und um dies richtig durchzuführen, würde ich wahrscheinlich den Code viel schneller ausführen müssen.
Die Arduino-Timer arbeiten, indem sie bis zu einer vordefinierten Zahl zählen (in diesem Fall 16 für 500 kHz ) dann setzen sie ein Überlaufregister und beginnen wieder bei 0. Der aktuelle Zählerstand kann jederzeit gelesen und geschrieben werden.
Ich habe die Skizze so angepasst, dass sie in einer Schleife wartet, bis der Timer übergelaufen ist, und wenn er übergelaufen ist, habe ich wie zuvor auf einen Impuls überprüft. Der Unterschied war diesmal, dass wenn ein Impuls innerhalb der Schleife erkannt wurde, setze ich den Timer-Zählerwert auf eine vordefinierte Phase . zurück Position, wodurch der Timer mit jedem Impuls effektiv neu synchronisiert wird.
Ich habe den Wert, den ich in den Timer-Zähler geschrieben habe, so gewählt, dass er bei 1 µSek nach dem Erkennungsimpuls (auf halbem Weg) überläuft, sodass der Impuls beim nächsten Überlauf des Timers 2 µSek auseinander gewesen wäre.
Das hat funktioniert! Ich las jetzt fast perfekte Daten von der Diskette. Ich bekam immer noch viele Prüfsummenfehler, was ärgerlich war. Ich habe die meisten davon gelöst, indem ich immer wieder dieselbe Spur auf dem Laufwerk gelesen habe, bis ich alle 11 Sektoren mit gültigen Header- und Datenprüfsummen hatte.
An diesem Punkt war ich neugierig, also schloss ich alles wieder an das Oszilloskop an, um zu sehen, was jetzt vor sich ging, und wie ich vermutete, konnte ich jetzt beide Spuren sehen, da sie beide synchron blieben:

Ich würde das gerne etwas klarer sehen, wenn mir jemand ein schönes digitales Spitzenoszilloskop (z. B. eines von Keysight!) spenden möchte, würde ich mich sehr freuen!
Versuch 5:
Ich fragte mich, ob ich das verbessern könnte. Beim Betrachten des Codes, insbesondere der inneren Leseschleife (siehe unten), hatte ich eine while-Schleife, die auf den Überlauf wartete, und dann eine innere if auf der Suche nach einem Impuls zum Synchronisieren.
Ein Codefragment, das zum Lesen der Daten und zum Synchronisieren verwendet wird:
register bool done =false; // Auf 500 kHz Überlauf warten, während (!(TIFR2&_BV(TOV2))) {// fallende Flanke beim Warten auf den 500-kHz-Impuls erkannt. if ((TCNT0) &&(!done)) {// Impuls erkannt, setzen Sie den Timer-Zähler zurück, um mit dem Impuls zu synchronisieren TCNT2 =Phase; // Warten Sie, bis der Impuls wieder hoch ist, während (!(PIN_RAW_FLOPPYDATA_PORT &PIN_RAW_FLOPPYDATA_MASK)) {}; erledigt =wahr; }} // Überlaufflag zurücksetzenTIFR2|=_BV(TOV2); // Haben wir einen Impuls vom Laufwerk erkannt?if (TCNT0) { DataOutputByte|=1; TCNT0=0;}
Mir wurde klar, dass die Zeit zwischen der Impulserkennung und dem Schreiben von TCNT2=phase; . abhängig davon ist, welcher Befehl in den obigen Schleifen ausgeführt wurde kann sich durch die Zeit, die für die Ausführung einiger Anweisungen benötigt wird, ändern.
Da ich erkannte, dass dies einige Fehler / Jitter in den Daten verursachen kann und es auch bei der obigen Schleife möglich ist, dass ich den Impuls vom Laufwerk verpasse (und somit ein Re-Sync-Bit vermisse), habe ich beschlossen, einen Trick von einem meiner früheren zu nehmen Versuche, die ISR (Interrupt).
Ich habe den Datenimpuls an einen zweiten Pin des Arduino angeschlossen. Die Daten wurden nun mit dem COUNTER0 Trigger verbunden und nun auch mit dem INT0 Pin. INT0 ist eine der höchsten Interrupt-Prioritäten und sollte daher die Verzögerungen zwischen Trigger und dem Aufruf des ISR minimieren, und da dies der einzige Interrupt ist, an dem ich tatsächlich interessiert bin, sind alle anderen deaktiviert.
Alles, was Sie dafür tun mussten, war, den obigen Re-Sync-Code auszuführen. Dies änderte den Code so, dass er wie folgt aussieht:
// Auf 500-kHz-Überlauf warten, während (!(TIFR2&_BV(TOV2))) {} // Überlauf-Flag zurücksetzenTIFR2|=_BV(TOV2); // Haben wir einen Impuls vom Laufwerk erkannt?if (TCNT0) { DataOutputByte|=1; TCNT0=0;} Der ISR sah wie folgt aus:(Beachten Sie, dass ich attachInterrupt nicht verwendet habe, da dies auch den Anruf überlastet).
flüchtiges Byte targetPhase;ISR (INT0_vect) { TCNT2=targetPhase;} Das Kompilieren erzeugte viel zu viel Code, um schnell genug ausgeführt zu werden. Tatsächlich produzierte das Zerlegen des oben genannten:
push r1push r0in r0, 0x3f; 63push r0eor r1, r1push r24 lds r24, 0x0102; 0x800102 sts 0x00B2, r24; 0x8000b2 pop r24pop r0out 0x3f, r0; 63pop r0pop r1reti Durch die Analyse des Codes stellte ich fest, dass es nur wenige Anweisungen gab, die ich tatsächlich brauchte. Da der Compiler alle Register, die ich verprügelte, nachverfolgen würde, habe ich den ISR wie folgt geändert:
volatiles Byte targetPhase asm ("targetPhase");ISR (INT0_vect) { asm volatile("lds __tmp_reg__, targetPhase"); asm volatile("sts %0, __tmp_reg__" ::"M" (_SFR_MEM_ADDR(TCNT2)));} Welche zerlegt, produziert die folgenden Anweisungen:
push r1push r0in r0, 0x3f; 63push r0eor r1, r1lds r0, 0x0102; 0x800102 sts 0x00B2, r0; 0x8000b2 pop r0out 0x3f, r0; 63pop r0pop r1reti Immer noch zu viele Anleitungen. Mir ist aufgefallen, dass der Compiler viele zusätzliche Anweisungen hinzufügt, die für meine Anwendung wirklich nicht vorhanden sein mussten. Also habe ich die ISR() nachgeschlagen und stolperte über einen zweiten Parameter ISR_NAKED. Dies würde den Compiler daran hindern, speziellen Code hinzuzufügen, aber dann wäre ich dafür verantwortlich, die Register, den Stack und die korrekte Rückkehr vom Interrupt zu verwalten. Ich müsste auch das SREG-Register pflegen, aber da keiner der Befehle, die ich aufrufen musste, es veränderte, brauchte ich mich nicht darum zu kümmern.
Dadurch wurde der ISR-Code zu:
ISR (INT0_vect, ISR_NAKED) { asm volatile("push __tmp_reg__"); // Bewahre das tmp_register asm volatile("lds __tmp_reg__, targetPhase"); // Kopiere den Phasenwert in das tmp_register asm volatile("sts %0, __tmp_reg__" ::"M" (_SFR_MEM_ADDR(TCNT2))); // Kopieren Sie das tmp_register in den Speicherort, an dem TCNT2 asm volatile("pop __tmp_reg__"); // Wiederherstellen des tmp_register asm volatile("reti"); // Und den ISR verlassen} Was der Compiler konvertiert hat in:
push r0lds r0, 0x0102; 0x800102 sts 0x00B2, r0; 0x8000b2 pop r0reti Fünf Anweisungen! Perfekt, oder zumindest so schnell, wie es sein sollte, theoretisch dauert die Ausführung 0,3125 µSek! Dies sollte nun bedeuten, dass die Neusynchronisierung zu zeitkonstanten Perioden nach dem Impuls erfolgen sollte. Unten ist ein Zeitdiagramm von dem, was vor sich geht. So stellen Sie Daten aus einem seriellen Datenfeed ohne Taktsignal wieder her:
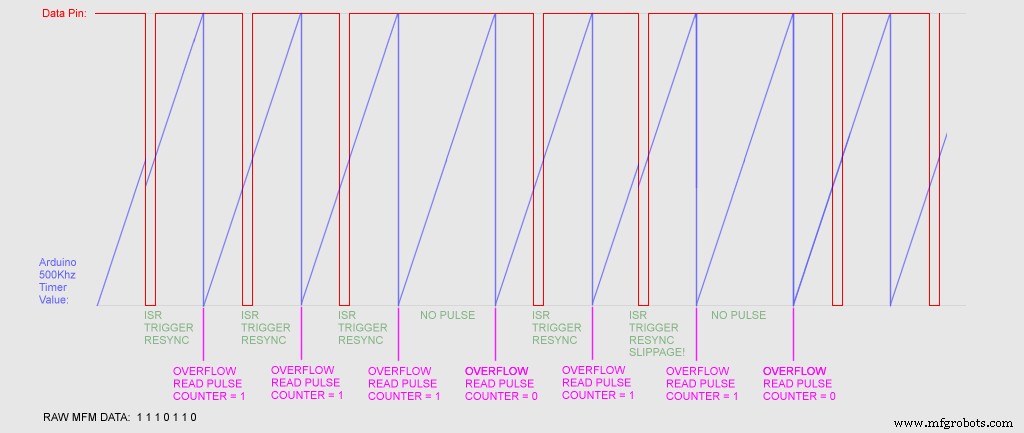
Das hat die Ergebnisse etwas verbessert. Es ist immer noch nicht perfekt. Einige Festplatten lesen jedes Mal perfekt, bei anderen dauert es ewig und muss immer wieder neu versucht werden. Ich bin mir nicht sicher, ob dies daran liegt, dass einige der Platten so lange dort lagen, dass der Magnetismus auf ein so niedriges Niveau abgefallen ist, dass die Verstärker des Laufwerks damit nicht fertig werden. Ich fragte mich, ob dies etwas mit dem PC-Diskettenlaufwerk zu tun hatte, also schloss ich es an ein externes Amiga-Diskettenlaufwerk an, das ich hatte, aber die Ergebnisse waren identisch.
Versuch 6:
Ich fragte mich, ob man noch etwas tun könnte. Vielleicht war das Signal des Laufwerks lauter, als ich dachte. Nachdem ich weitere Informationen gelesen hatte, entdeckte ich, dass ein 1KOhm Pullup-Widerstand die Norm war, der in einen Schmitt-Trigger eingespeist wurde.
Nachdem ich einen SN74HCT14N Hex Schmitt Trigger installiert und den Sketch so umkonfiguriert hatte, dass er auf steigende Flanken statt auf fallende Flanken triggert, habe ich es versucht, aber es machte keinen wirklichen Unterschied. Ich denke, da ich jedes Mal nach einem oder mehreren Impulsen suchte, wurde dies wahrscheinlich absorbiert sowieso kein Geräusch. Also bleiben wir bei Methode Versuch 5!
sn74hct14.pdfMeine endgültige Steckbrettlösung sah folgendermaßen aus:

Beachten Sie, dass sich die Verkabelung oben etwas von der Live-Skizze unterscheidet. Ich habe einige der Arduino-Pins nachbestellt, um den Schaltplan zu vereinfachen.
Versuch 7:
Ich war ein wenig unzufrieden mit einigen der Disketten, die ich nicht gelesen hatte. Manchmal lagen die Disketten einfach nicht richtig im Diskettenlaufwerk. Ich schätze, die Feder am Verschluss hat nicht geholfen.
Ich begann zu untersuchen, ob Fehler in den tatsächlich empfangenen MFM-Daten von der Festplatte aufgetreten sind.
Aus den Regeln zur Funktionsweise der MFM-Codierung wurde mir klar, dass einige einfache Regeln wie folgt angewendet werden können:
- Es dürfen nicht zwei '1'-Bits nebeneinander sein
- Es dürfen nicht mehr als drei '0'-Bits nebeneinander sein
Zuerst habe ich beim Decodieren von MFM-Daten nachgesehen, ob es zwei "1"en hintereinander gibt. Wenn dies der Fall war, ging ich davon aus, dass die Daten im Laufe der Zeit ein wenig verschwommen wurden und ignorierte die zweite '1'.
Wenn diese Regel angewendet wird, gibt es buchstäblich drei Situationen von 5 Bit, in denen Fehler auftreten können. Dies wäre ein neuer Bereich, in dem ich nach Verbesserung der Daten suchen könnte.
Meistens war ich jedoch überrascht, dass nicht so viele MFM-Fehler erkannt wurden. Ich bin ein wenig verwirrt, warum einige der Festplatten nicht gelesen werden, wenn keine Fehler gefunden werden.
Dies ist ein Bereich für weitere Untersuchungen.
Dekodierung
Nachdem ich gelesen hatte, wie MFM funktioniert, war ich mir nicht ganz sicher, wie es richtig ausgerichtet war.
Zuerst dachte ich, dass der Antrieb 1s und 0s für die Ein- und Aus-Bits ausgibt. Dies war nicht der Fall. Der Antrieb gibt einen Impuls für jeden Phasenübergang aus, dh:jedes Mal, wenn die Daten von 0 auf 1 oder von 1 auf 0 gehen.
Nachdem ich dies gelesen hatte, fragte ich mich, ob ich dies zurück in Einsen und Nullen konvertieren musste, indem ich es in einen Flip-Flop-Kippschalter einspeiste, oder die Daten lesen, nach Sektoren suchen und wenn keine gefunden wurden, dann die Daten invertieren und es erneut versuchen!
Es stellt sich heraus, dass dies nicht der Fall ist und es viel einfacher ist. Die Impulse sind eigentlich die RAW-MFM-Daten und können direkt in die Decodierungsalgorithmen eingespeist werden. Nachdem ich dies verstanden hatte, begann ich, Code zu schreiben, um einen Puffer vom Laufwerk zu scannen und nach dem Sync-Wort 0x4489 zu suchen. Überraschenderweise habe ich es gefunden!
Aufgrund meiner Recherchen wurde mir klar, dass ich tatsächlich nach 0xAAAAAAAA44894489 . suchen musste (ein Hinweis aus der Recherche deutete auch darauf hin, dass es einige Fehler im frühen Amiga-Code gab, die dazu führten, dass die obige Sequenz nicht gefunden wurde. Also suchte ich stattdessen nach 0x2AAAAAAA44894489 nach UND-Verknüpfung der Daten mit 0x7FFFFFFFFFFFFFF ).
Wie erwartet fand ich bis zu 11 davon auf jedem Track entsprechend dem tatsächlichen Start der 11 Amiga-Sektoren. Dann begann ich, die folgenden Bytes zu lesen, um zu sehen, ob ich die Sektorinformationen entschlüsseln konnte.
Ich habe einen Codeausschnitt aus einer der obigen Referenzen genommen, um bei der MFM-Decodierung zu helfen. Es hat keinen Sinn, das Rad neu zu erfinden, oder?
Nachdem ich den Header und die Daten gelesen hatte, versuchte ich, sie als ADF-Datei auf die Festplatte zu schreiben. Das Standard-ADF-Dateiformat ist sehr einfach. Es sind buchstäblich nur die 512 Bytes von jedem Sektor (von beiden Seiten der Platte), die der Reihe nach geschrieben werden. Nachdem ich es geschrieben und versucht hatte, es mit ADFOpus zu öffnen und gemischte Ergebnisse erzielte, öffnete es manchmal die Datei, manchmal schlug es fehl. Es gab offensichtlich Fehler in den Daten. Ich fing an, mir die Prüfsummenfelder im Header anzusehen, Sektoren mit ungültigen Prüfsummen abzulehnen und das Lesen zu wiederholen, bis ich 11 gültige hatte.
Bei einigen Festplatten waren dies alle 11 beim ersten Lesen, einige brauchten mehrere Versuche und auch unterschiedliche Phasenwerte.
Endlich habe ich es geschafft, gültige ADF-Dateien zu schreiben. Manche Disketten würden ewig brauchen, andere buchstäblich die Geschwindigkeit, mit der der Amiga sie gelesen hätte. Da ich keinen funktionierenden Amiga mehr habe, konnte ich nicht wirklich überprüfen, ob diese Disketten normal lesen, sie wurden jahrelang in einer Kiste auf dem Dachboden gelagert und können daher stark beschädigt sein.
Was kommt als nächstes?
Das nächste ist bereits passiert - V2 ist hier verfügbar und hat die Lese- und Schreibunterstützung verbessert!
Nun, erstens habe ich das gesamte Projekt frei und Open Source unter der GNU General Public License V3 gemacht. Wenn wir irgendeine Hoffnung haben wollen, den Amiga zu erhalten, dann sollten wir uns nicht gegenseitig für das Privileg austricksen, und außerdem möchte ich der besten Plattform, an der ich je gearbeitet habe, etwas zurückgeben. Ich hoffe auch, dass die Leute dies weiterentwickeln und weiterentwickeln und weiter teilen.
Als nächstes möchte ich mir andere Formate ansehen. ADF-Dateien sind gut, funktionieren aber nur für AmigaDOS-formatierte Disketten. Es gibt viele Titel mit benutzerdefiniertem Kopierschutz und nicht standardmäßigen Sektorformaten, die von diesem Format einfach nicht unterstützt werden können.
Laut Wikipedia gibt es ein weiteres Festplattendateiformat, das FDI-Format. Ein universelles Format, das gut dokumentiert ist. Der Vorteil dieses Formats besteht darin, dass es versucht, die Trackdaten so nah wie möglich am Original zu speichern, damit hoffentlich die oben genannten Probleme behoben werden!
Ich bin auch auf die Software Preservation Society gestoßen, genauer gesagt CAPS (ehemals die Classic Amiga Preservation Society ) und ihr IPF-Format. Nachdem ich ein wenig gelesen hatte, war ich sehr enttäuscht, es war alles geschlossen und es fühlte sich an, als würden sie dieses Format nur verwenden, um ihre Hardware zum Lesen von Festplatten zu verkaufen.
Mein Fokus wird also auf den FDI liegen! Format. Mir geht es hier nur um die Datenintegrität. Es wird keine Prüfsummen geben, mit denen ich überprüfen kann, ob der Lesevorgang gültig war, aber ich habe ein paar Ideen, um das zu beheben!
Und schließlich werde ich auch nach einer Option zum Schreiben von Datenträgern suchen (die möglicherweise sowohl FDI als auch ADF unterstützt), da das Hinzufügen wirklich nicht so schwierig sein sollte.
Code
GitHub-Repository
Arduino-Skizze und Windows-Quellcodehttps://github.com/RobSmithDev/ArduinoFloppyDiskReaderSchaltpläne
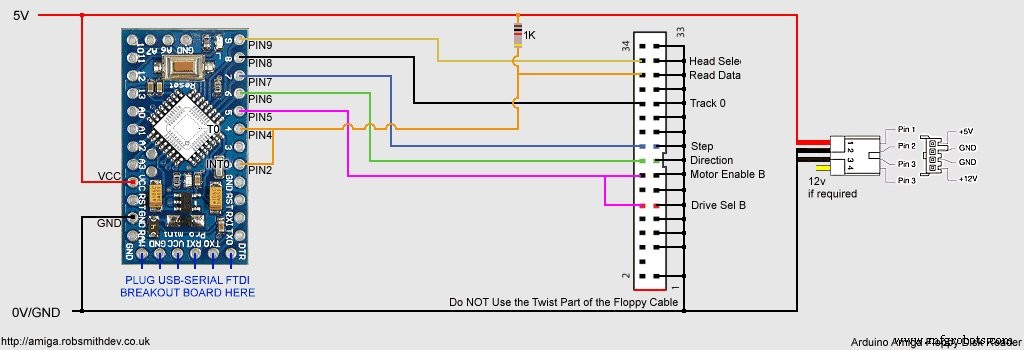
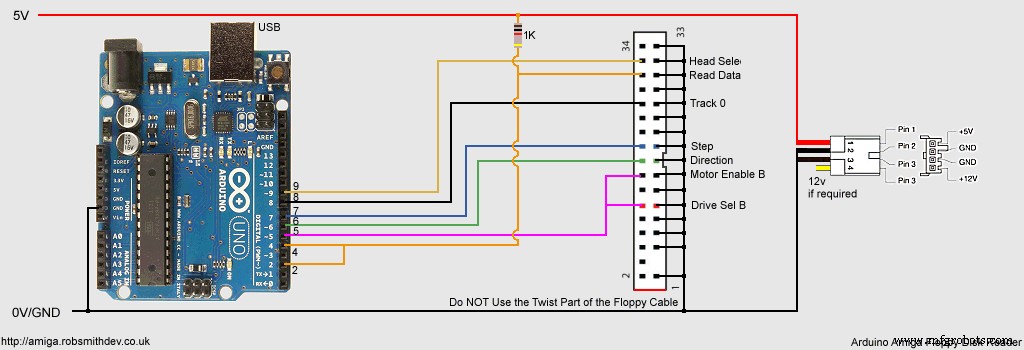
Herstellungsprozess