


Compiler in der fremden Welt der funktionalen Sicherheit
Branchenübergreifend stellt die Welt der funktionalen Sicherheit neue Anforderungen an Entwickler. Funktional sicherer Code muss defensiven Code enthalten, um unerwartete Ereignisse abzuwehren, die aus einer Vielzahl von Ursachen resultieren können. Beispielsweise kann eine Speicherverfälschung aufgrund von Codierungsfehlern oder Cosmic-Ray-Ereignissen zur Ausführung von Codepfaden führen, die gemäß der Logik des Codes „unmöglich“ sind. Hochsprachen, insbesondere C und C++, enthalten eine überraschende Anzahl von Funktionen, deren Verhalten nicht durch die Sprachspezifikation vorgeschrieben ist, an die sich der Code hält. Dieses undefinierte Verhalten kann zu unerwarteten und potenziell katastrophalen Ergebnissen führen, die in einer funktional sicheren Anwendung nicht akzeptabel wären. Aus diesen Gründen verlangen Standards, dass defensive Codierung angewendet wird, dass Code testbar ist, dass es möglich ist, eine angemessene Codeabdeckung zu sammeln und dass Anwendungscode auf Anforderungen zurückverfolgt werden kann, um sicherzustellen, dass das System sie vollständig und eindeutig implementiert.
Code muss auch eine hohe Codeabdeckung erreichen, und in einigen Sektoren – insbesondere in der Automobilindustrie – ist es üblich, dass das Design ausgefeilte externe Diagnose-, Kalibrierungs- und Entwicklungstools erfordert. Das dabei entstehende Problem besteht darin, dass Praktiken wie defensives Codieren und externer Datenzugriff nicht Teil einer Welt sind, die Compiler erkennen. Weder C noch C++ berücksichtigen Speicherbeschädigungen. Wenn also kein Code zum Schutz davor zugänglich ist, wenn keine solche Beschädigung vorliegt, kann er bei der Optimierung des Codes einfach ignoriert werden. Folglich muss defensiver Code syntaktisch und semantisch erreichbar sein, wenn er nicht „wegoptimiert“ werden soll.
Auch Fälle von undefiniertem Verhalten können für Überraschungen sorgen. Es ist leicht vorzuschlagen, dass sie einfach vermieden werden sollten, aber es ist oft schwierig, sie zu identifizieren. Sofern vorhanden, kann nicht garantiert werden, dass das Verhalten des kompilierten ausführbaren Codes den Absichten der Entwickler entspricht. Der „Hintertür“-Zugriff auf Daten, der von Debugging-Tools verwendet wird, stellt eine weitere Situation dar, die die Sprache nicht berücksichtigt und die unerwartete Folgen haben kann.
Die Compiler-Optimierung kann auf all diese Bereiche einen großen Einfluss haben, da keiner von ihnen zum Aufgabenbereich von Compiler-Herstellern gehört. Optimierung kann dazu führen, dass scheinbar solider defensiver Code dort eliminiert wird, wo er mit „Undurchführbarkeit“ in Verbindung gebracht wird – das heißt, wenn er auf Pfaden existiert, die nicht durch einen Satz möglicher Eingabewerte getestet und verifiziert werden können. Noch besorgniserregender ist, dass defensiver Code, der während des Unit-Tests nachweisbar ist, durchaus eliminiert werden kann, wenn die ausführbare Datei des Systems erstellt wird. Nur weil die Abdeckung des defensiven Codes während des Unit-Tests erreicht wurde, ist keine Garantie dafür, dass er im fertigen System vorhanden ist.
In diesem seltsamen Land der funktionalen Sicherheit ist der Compiler möglicherweise nicht in seinem Element. Aus diesem Grund stellt die Objektcode-Verifizierung (OCV) die beste Vorgehensweise für jedes System dar, für das ein Ausfall schwerwiegende Folgen hat – und tatsächlich für jedes System, für das nur die beste Vorgehensweise gut genug ist.
Vor und nach der Kompilierung
Verifizierungs- und Validierungspraktiken, die von funktionalen Sicherheits-, Sicherheits- und Codierungsstandards wie IEC 61508, ISO 26262, IEC 62304, MISRA C und C++ verfochten werden, legen großen Wert darauf, zu zeigen, wie viel Anwendungsquellcode während anforderungsbasierter Tests verwendet wird.
Die Erfahrung hat uns gezeigt, dass die Wahrscheinlichkeit eines Ausfalls im Feld erheblich geringer ist, wenn gezeigt wird, dass Code korrekt funktioniert. Da der Fokus dieses lobenswerten Unterfangens jedoch auf dem High-Level-Quellcode (egal in welcher Sprache) liegt, wird bei einem solchen Ansatz viel Vertrauen in die Fähigkeit des Compilers gesetzt, Objektcode zu erstellen, der genau das reproduziert, was die Entwickler beabsichtigt. In den kritischsten Anwendungen kann diese implizite Annahme nicht gerechtfertigt werden.
Es ist unvermeidlich, dass die Kontrolle und der Datenfluss des Objektcodes kein exaktes Spiegelbild des Quellcodes sind, aus dem er abgeleitet wurde, und der Beweis, dass alle Quellcodepfade zuverlässig ausgeübt werden können, beweist nicht dasselbe für den Objektcode . Angesichts der Tatsache, dass zwischen Objektcode und Assembler eine 1:1-Beziehung besteht, ist ein Vergleich zwischen Quell- und Assemblercode aufschlussreich. Betrachten Sie das in Abbildung 1 gezeigte Beispiel, in dem der Assemblercode rechts aus dem Quellcode links generiert wurde (unter Verwendung eines TI-Compilers mit deaktivierter Optimierung).

Abbildung 1:Der rechte Assembler-Code wurde aus dem linken Quellcode generiert und zeigt den aussagekräftigen Vergleich zwischen Quell- und Assemblercode. (Quelle:LDRA)
Wie später gezeigt wird, unterscheidet sich der Flussgraph für den resultierenden Assemblercode beim Kompilieren dieses Quellcodes stark von dem für den Quellcode, da die von C- oder C++-Compilern befolgten Regeln es ihnen erlauben, den Code nach Belieben zu ändern, vorausgesetzt, die Binärdatei ist vorhanden verhält sich „als ob es dasselbe wäre.“
In den meisten Fällen ist dieses Prinzip völlig akzeptabel – aber es gibt Anomalien. Compileroptimierungen sind im Grunde mathematische Transformationen, die auf eine interne Repräsentation des Codes angewendet werden. Diese Transformationen gehen „schief“, wenn Annahmen nicht zutreffen – wie es oft der Fall ist, wenn die Codebasis beispielsweise Instanzen von undefiniertem Verhalten enthält.
Nur DO-178C, das in der Luft- und Raumfahrtindustrie verwendet wird, konzentriert sich auf das Potenzial gefährlicher Inkonsistenzen zwischen Entwicklerabsichten und ausführbarem Verhalten – und selbst dann ist es nicht schwer, Befürworter von Workarounds mit eindeutigem Potenzial zu finden, diese Inkonsistenzen unentdeckt zu lassen. Wie auch immer solche Ansätze entschuldigt werden, es bleibt die Tatsache, dass die Unterschiede zwischen Quell- und Objektcode in jeder kritischen Anwendung verheerende Folgen haben können.
Entwicklerabsicht versus ausführbares Verhalten
Trotz der klaren Unterschiede zwischen Quell- und Objektcodefluss sind sie nicht das Hauptanliegen. Compiler sind im Allgemeinen sehr zuverlässige Anwendungen, und obwohl es wie bei jeder anderen Software Fehler geben kann, wird die Implementierung eines Compilers im Allgemeinen seine Designanforderungen erfüllen. Das Problem ist, dass diese Designanforderungen nicht immer die Anforderungen eines funktional sicheren Systems widerspiegeln.
Kurz gesagt kann davon ausgegangen werden, dass ein Compiler den Zielen seiner Schöpfer funktional entspricht. Dies ist jedoch möglicherweise nicht ganz das, was gewünscht oder erwartet wird, wie in Abbildung 2 unten anhand eines Beispiels dargestellt, das sich aus der Kompilierung mit dem CLANG-Compiler ergibt.

Abbildung 2 zeigt eine Kompilierung mit dem CLANG-Compiler (Quelle:LDRA)
Es ist klar, dass der defensive Aufruf der Funktion ‚error‘ nicht im Assembler-Code ausgedrückt wurde.
Das 'state'-Objekt wird nur modifiziert, wenn es initialisiert wird und in den Fällen 'S0' und 'S1', sodass der Compiler folgern kann, dass 'state' nur die Werte 'S0' und 'S1' erhält kommt zu dem Schluss, dass 'default' nicht benötigt wird, da 'state' niemals andere Werte halten wird, vorausgesetzt, es liegt keine Beschädigung vor – und tatsächlich macht der Compiler genau diese Annahme.
Da die Werte der tatsächlichen Objekte (13 und 23) nicht in einem numerischen Kontext verwendet werden, hat der Compiler auch entschieden, dass er einfach die Werte 0 und 1 verwendet, um zwischen den Zuständen umzuschalten, und dann ein exklusives „oder“ zum Aktualisieren verwendet der Staatswert. Die Binärdatei hält sich an die „Als ob“-Verpflichtung und der Code ist schnell und kompakt. Innerhalb seiner Leistungsbeschreibung hat der Compiler gute Arbeit geleistet.
Dieses Verhalten hat Auswirkungen auf „Kalibrierungs“-Tools, die die Linker-Speicherzuordnungsdatei verwenden, um indirekt auf Objekte zuzugreifen, und auf den direkten Speicherzugriff über einen Debugger. Auch diese Überlegungen gehören nicht zum Aufgabenbereich des Compilers und werden daher bei der Optimierung und/oder Codegenerierung nicht berücksichtigt.
Nehmen wir nun an, der Code bleibt unverändert, aber sein Kontext im Code, der dem Compiler präsentiert wird, ändert sich leicht, wie in Abbildung 3.
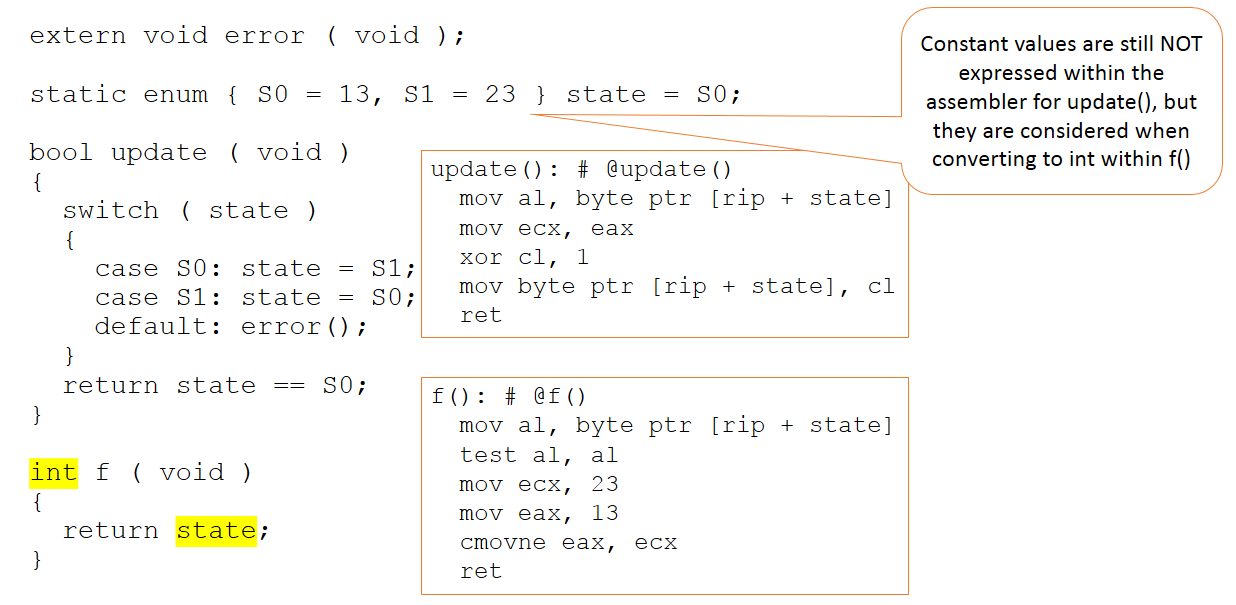
Abbildung 3:Der Code bleibt unverändert, aber sein Kontext im Code, der dem Compiler präsentiert wird, ändert sich geringfügig. (Quelle:LDRA)
Es gibt jetzt eine zusätzliche Funktion, die den Wert der Zustandsvariablen als Integer zurückgibt. Diesmal sind die absoluten Werte 13 und 23 im Code, der dem Compiler übergeben wird, von Bedeutung. Trotzdem werden diese Werte innerhalb der Update-Funktion (die unverändert bleibt) nicht manipuliert und sind nur in unserer neuen „f“-Funktion sichtbar.
Kurz gesagt, der Compiler fällt weiterhin (zu Recht) Werturteile darüber, wo die Werte von 13 und 23 verwendet werden sollten – und sie werden keineswegs in allen Situationen angewendet, in denen sie sein könnten.
Wenn die neue Funktion geändert wird, um einen Zeiger auf unsere Zustandsvariable zurückzugeben, ändert sich der Assembler-Code erheblich. Da nun die Möglichkeit von Alias-Zugriffen über einen Zeiger besteht, kann der Compiler nicht mehr ableiten, was mit dem Zustandsobjekt passiert. Wie in Abbildung 4 unten gezeigt, kann daraus nicht geschlossen werden, dass die Werte von 13 und 23 unwichtig sind und werden daher jetzt explizit innerhalb des Assemblers ausgedrückt.
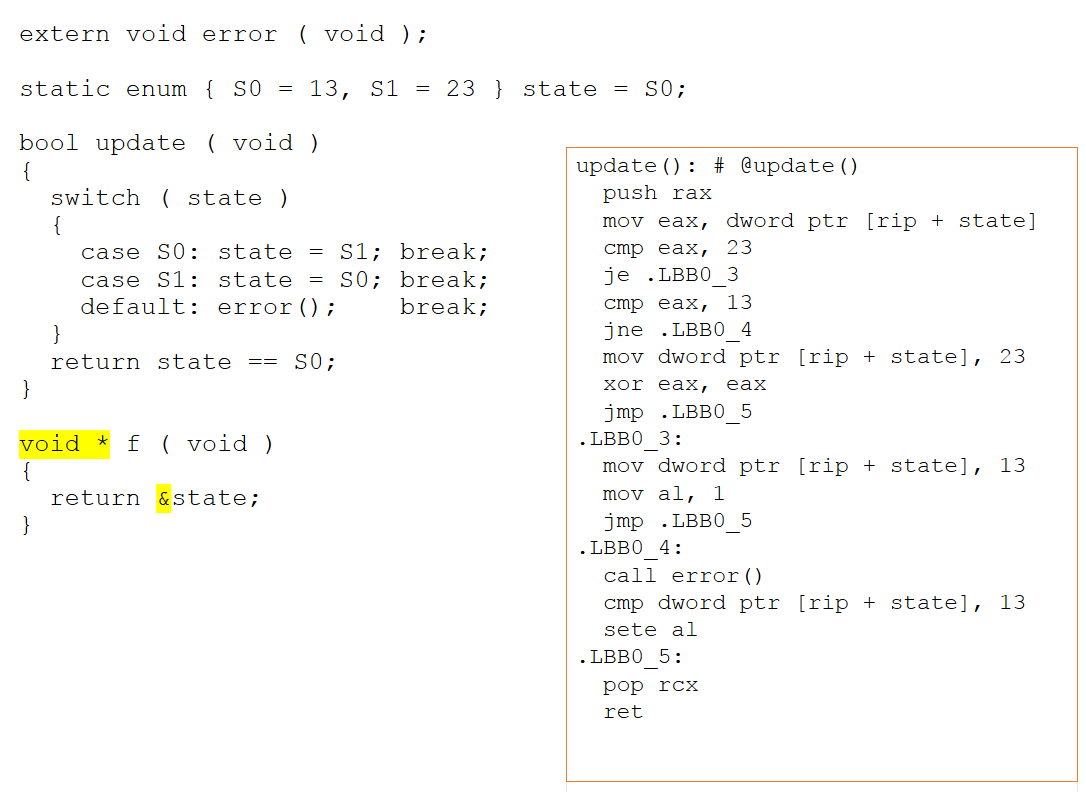
Abbildung 4:Wenn die neue Funktion geändert wird, um einen Zeiger auf unsere Zustandsvariable zurückzugeben, ändert sich der Assembler-Code erheblich. Daraus kann nicht geschlossen werden, dass die Werte von 13 und 23 unwichtig sind und werden daher jetzt explizit innerhalb des Assemblers ausgedrückt (Quelle:LDRA).
Implikationen für den Komponententest des Quellcodes
Betrachten Sie nun das Beispiel im Kontext eines imaginären Unit-Test-Harness. Als Folge der Notwendigkeit eines Kabelbaums, um auf den zu testenden Code zuzugreifen, wird der Wert der Zustandsvariablen manipuliert und folglich wird die Vorgabe nicht „wegoptimiert“. In einem Testtool, das keinen Kontext zum restlichen Quellcode hat und alles zugänglich machen soll, ist ein solches Vorgehen durchaus vertretbar, kann aber als Nebeneffekt das legitime Unterlassen von defensivem Code durch den Compiler verschleiern.
Der Compiler erkennt, dass über einen Pointer ein beliebiger Wert in die Zustandsvariable geschrieben wird und kann auch hier nicht auf die Bedeutung der Werte 13 und 23 schließen. Folglich werden sie jetzt explizit innerhalb des Assemblers ausgedrückt. Bei dieser Gelegenheit kann daraus nicht geschlossen werden, dass S0 und S1 die einzig möglichen Werte für die Zustandsvariable darstellen, was bedeutet, dass der Standardpfad machbar ist. Wie in Abbildung 5 gezeigt, erreicht die Manipulation der Zustandsvariablen ihr Ziel und der Aufruf der Fehlerfunktion ist nun im Assembler ersichtlich.

Abbildung 5:Die Manipulation der Zustandsvariablen erreicht ihr Ziel und der Aufruf der Fehlerfunktion ist nun im Assembler ersichtlich. (Quelle:LDRA)
Diese Manipulation wird jedoch im Code, der innerhalb eines Produkts ausgeliefert wird, nicht vorhanden sein, und daher ist der Aufruf von error() im gesamten System nicht wirklich vorhanden.
Die Bedeutung der Objektcode-Verifizierung
Um zu veranschaulichen, wie die Objektcode-Verifizierung helfen kann, dieses Rätsel zu lösen, betrachten Sie noch einmal das erste Beispiel-Code-Snippet, das in Abbildung 6 gezeigt wird:

Abbildung 6:Dies veranschaulicht, wie die Objektcode-Verifizierung helfen kann, zu beheben, dass der Aufruf zum Fehler nicht im gesamten System vorhanden ist. (Quelle:LDRA)
Es kann gezeigt werden, dass dieser C-Code mit einem einzigen Aufruf eine 100-prozentige Quellcodeabdeckung erreicht:
f_while4(0,3);
Der Code kann in eine einzelne Operation pro Zeile umformatiert und in einem Flussdiagramm als eine Sammlung von „Basisblock“-Knoten dargestellt werden, von denen jeder eine Folge von geradlinigem Code ist. Die Beziehung zwischen den Basisblöcken ist in Abbildung 7 unter Verwendung gerichteter Kanten zwischen den Knoten dargestellt.
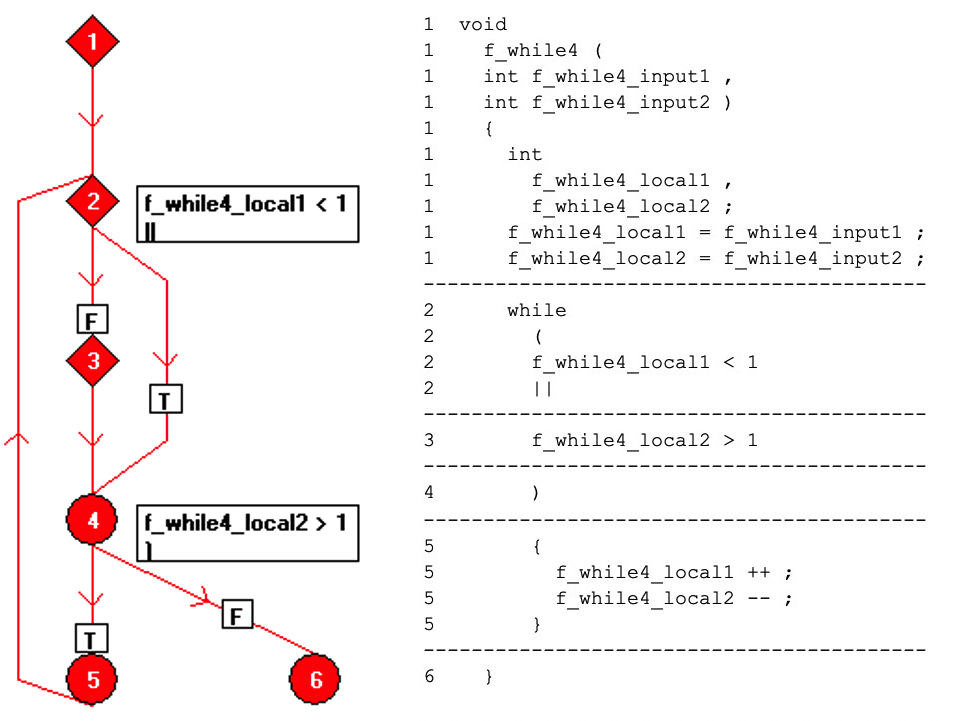
Abbildungen 7:Dies zeigt die Beziehung zwischen den Basisblöcken unter Verwendung gerichteter Kanten zwischen den Knoten. (Quelle:LDRA)
Wenn der Code kompiliert ist, sieht das Ergebnis wie unten gezeigt aus (Abbildung 8). Die blauen Elemente des Flussdiagramms stellen Code dar, der nicht durch den Aufruf f_while4(0,3) ausgeführt wurde.
Durch die Nutzung der Eins-zu-Eins-Beziehung zwischen Objektcode und Assemblercode legt dieser Mechanismus offen, welche Teile des Objektcodes nicht ausgeführt werden, und fordert den Tester auf, zusätzliche Tests zu entwickeln und eine vollständige Assemblercode-Abdeckung zu erreichen – und damit eine Objektcode-Verifizierung zu erreichen.
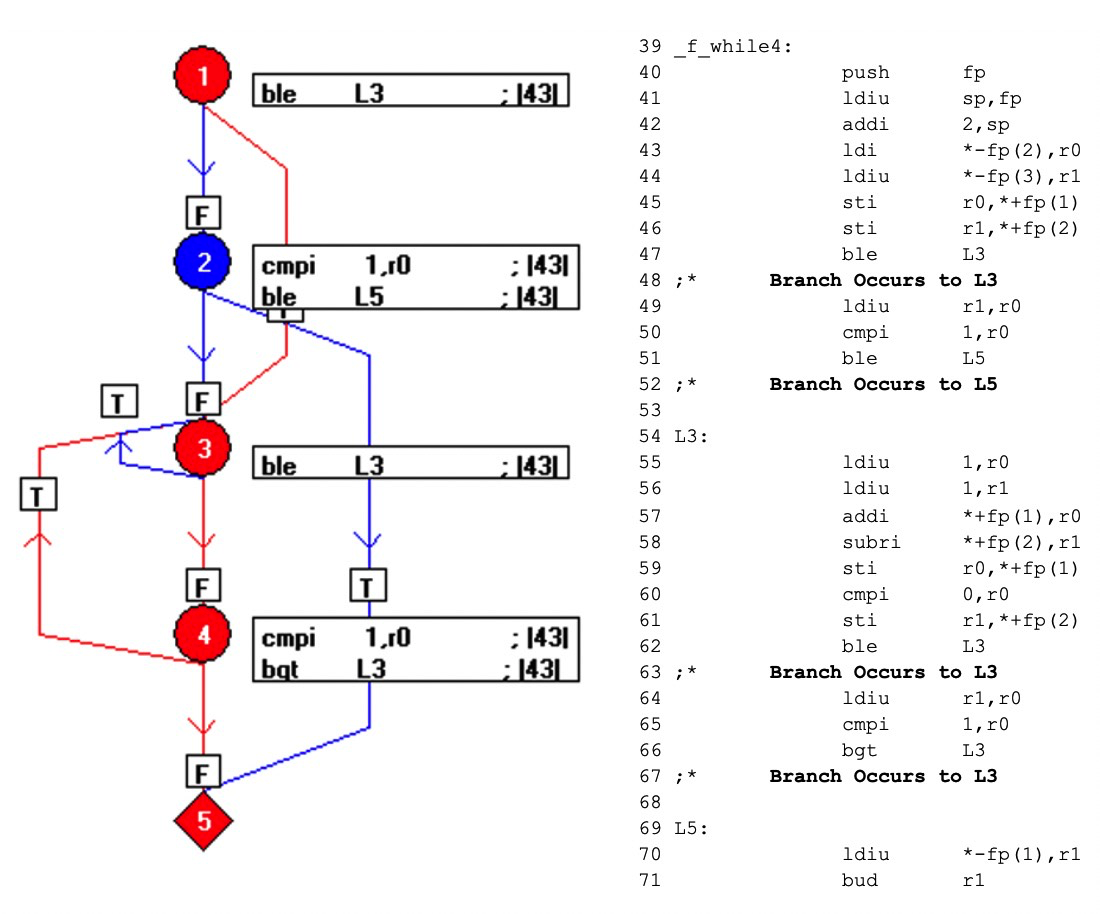
Abbildungen 8:Dies zeigt das Ergebnis beim Kompilieren des Codes. Die blauen Elemente des Flussdiagramms stellen Code dar, der nicht durch den Aufruf f_while4(0,3) ausgeführt wurde. (Quelle:LDRA)
Offensichtlich kann die Objektcode-Verifizierung nicht verhindern, dass der Compiler seinen Entwurfsregeln folgt und versehentlich die besten Absichten der Entwickler umgeht. Aber es kann Unachtsame auf solche Unstimmigkeiten aufmerksam machen und tut es auch.
Betrachten Sie dieses Prinzip nun im Kontext des früheren „Call-to-Error“-Beispiels. Der Quellcode im fertigen System wäre natürlich identisch mit dem auf Unit-Test-Niveau nachgewiesenen, ein Vergleich würde also nichts ergeben. Aber die Anwendung der Objektcode-Verifizierung auf das fertige System wäre von unschätzbarem Wert, um sicherzustellen, dass wesentliches Verhalten wie von den Entwicklern beabsichtigt zum Ausdruck kommt.
Best Practice in jeder Welt
Wenn der Compiler Code im Test-Harness anders handhabt als im Komponententest, lohnt es sich dann, den Quellcode-Komponententest abzudecken? Die Antwort ist ein qualifiziertes „Ja“. Viele Systeme wurden aufgrund des Nachweises solcher Artefakte zertifiziert und haben sich im Betrieb als sicher und zuverlässig erwiesen. Aber wenn der Entwicklungsprozess für die kritischsten Systeme in allen Sektoren der genauesten Prüfung standhalten und Best Practices einhalten soll, muss die Unit-Test-Abdeckung auf Source-Ebene durch OCV ergänzt werden. Es ist vernünftig anzunehmen, dass es seine Designkriterien erfüllt, aber diese Kriterien beinhalten keine Überlegungen zur funktionalen Sicherheit. Die Objektcode-Verifizierung stellt derzeit den sichersten Ansatz für die Welt der funktionalen Sicherheit dar, in der das Compiler-Verhalten den Standards entspricht, aber dennoch erhebliche negative Auswirkungen haben kann.
Eingebettet
- Die Bedeutung der elektrischen Sicherheit
- Die Welt der Textilfarben
- Anwendung saurer Farbstoffe in der Welt der Stoffe
- Ein Blick in die Welt der Farbstoffe
- Die vielen Einsatzmöglichkeiten von Sicherheitskörben
- Die sich schnell entwickelnde Welt der Simulation
- Die Produktionshauptstädte der Welt
- 5 der wichtigsten Sicherheitstipps für Krane
- Die Bedeutung von Reibmaterialien in Sicherheitssystemen
- Sicherheit in Fabriken:eine Quelle der kontinuierlichen Verbesserung