


Designüberlegungen für stromsparende, immer aktive Sprachbefehlssysteme
Sprachassistenten und Integration werden in die meisten auf dem Markt eingeführten Produkte, Geräte und Technologien implementiert. Davon abgesehen ist es kein Geheimnis, dass diese nützlichen Sprachassistenten immer auf Aktivierungs-/Weckwörter (wie „okay Google“ oder „Alexa“) lauschen, die oft viel Strom verbrauchen. In einer Welt, in der sich die Technologie rasant weiterentwickelt, ist es unerlässlich, die Auswirkungen auf den Energieverbrauch zu berücksichtigen.
Dieser Artikel enthält Designüberlegungen für stromsparende, immer aktive Sprachbefehlssysteme mit Sprachaktivitätserkennung (VAD). Es untersucht Kompromisse und Überlegungen bei der Auswahl der Komponenten, die für die Erstellung einer benutzerfreundlichen, energieeffizienten Sprachbenutzeroberfläche (VUI) erforderlich sind.
Die VAD-Funktion erkennt die menschliche Stimme in der Umgebung, bevor sie auf ein Weckwort hört. Das bedeutet, dass Ihr Sprachassistent keine unnötige Energie verschwendet, wenn niemand zu Hause ist. Es wird geschätzt, dass weltweit 4,2 Milliarden digitale Sprachassistenten verwendet werden, und diese Zahl wird sich bis 2024 voraussichtlich verdoppeln. Die Implementierung dieser Technologie in Sprachassistenten-Software und andere Produkte, die auf Sprachintegration angewiesen sind, würde den Energieverbrauch dieser Geräte drastisch senken die Sprachassistenten verwenden.
Es gibt mehrere Hardwarearchitekturen zum Implementieren eines VUI-Systems. Im Allgemeinen besteht eine typische Implementierung einer Sprachbenutzeroberfläche aus Mikrofonen, entweder einem einzelnen Mikrofon oder einem Mikrofonarray, das mit einem Audioprozessor zum Erfassen und Verarbeiten von Sprache verbunden ist.
Der eingehende Audiostream kann auf einem Edge-Audio-Edge-Prozessor, einem intelligenten Mikrofon mit integriertem Audio-Edge-Prozessor oder auf einem Standardanwendungsprozessor (AP) verarbeitet werden. Edge-Audioprozessoren sind für die Verarbeitung von Audiosignalen mit geringem Stromverbrauch und geringer Latenz optimiert. Neben der speziellen Verarbeitung des Eingangsaudios kann ein Edge-Audioprozessor auch zur Nachbearbeitung von Audioausgangssignalen verwendet werden. Wenn das VUI-System mit der Cloud verbunden ist, kann der Audio-Edge-Prozessor auch über das Hauptsystem-on-a-Chip (SoC) mit drahtloser Konnektivität mit der Cloud-VUI-Schnittstelle kommunizieren. In diesem Whitepaper werden zwei verschiedene Implementierungen für VUI-Systeme mit ihren jeweiligen Kompromissen vorgestellt.
Ultra-low-power VAD (Sprachaktivitätserkennung)
Die in Abbildung 1 gezeigte Architektur unterstützt VUI mit extrem geringem Stromverbrauch, die einen analogen Signalpfad verwendet, einschließlich eines analogen Mikrofons und eines analogen Komparators, um einen Wake-Trigger bereitzustellen. Wenn eine akustische Aktivität erkannt wird, generiert die analoge Signalkette einen Interrupt, um den Audioprozessor für die Sprachaufnahme aufzuwecken. Das Gerät könnte auch eine „Push-to-Talk“-Funktion beinhalten, bei der der Benutzer einen Knopf drückt, um den Audioprozessor aufzuwecken.
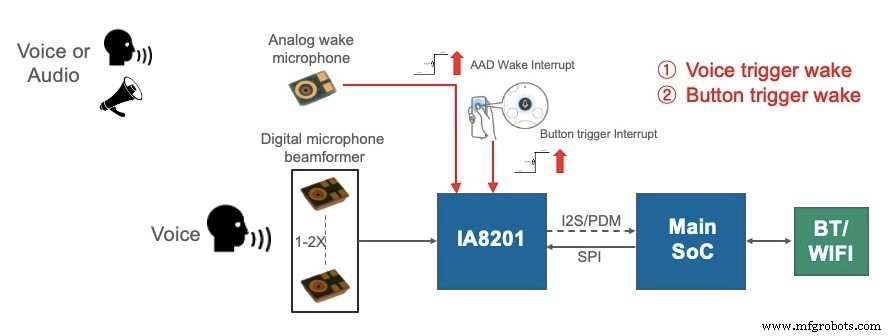
Das analoge Wake-Mikrofon muss immer auf die Umgebung hören, und daher darf dieses Mikrofon zusammen mit dem Komparator sehr wenig Strom verbrauchen. Ein Beispiel für einen effizienten Audioprozessor mit einem Stromverbrauch von weniger als 1 mW im einfachsten Wakeup-Triggermodus und 1 MB Speicher für erweiterte Audioverarbeitung ist der Knowles IA8201. Der in Abbildung 1 dargestellte Ansatz bietet zwar einen einfachen AAD-Ansatz (Acoustic Activity Detection) mit geringem Stromverbrauch für eine stets aktive VUI in Geräten wie Fernbedienungen und Wearables, weist jedoch Einschränkungen auf. Diese Implementierung weckt den Audioprozessor für jedes akustische Signal und kann in lauten Situationen zu einem hohen Gesamtstromverbrauch des Systems führen. Außerdem erfordern Sprachbenutzerschnittstellensysteme, die mit der Cloud verbunden sind, Audiodaten für einen Zeitraum kurz vor dem Erfassen des Weckworts, um die Genauigkeit der Weckworterkennung zu erhöhen. Dies wird allgemein als Pre-Roll bezeichnet und ist eine unverzichtbare Voraussetzung für Alexa-fähige Geräte und andere intelligente Lautsprechergeräte.
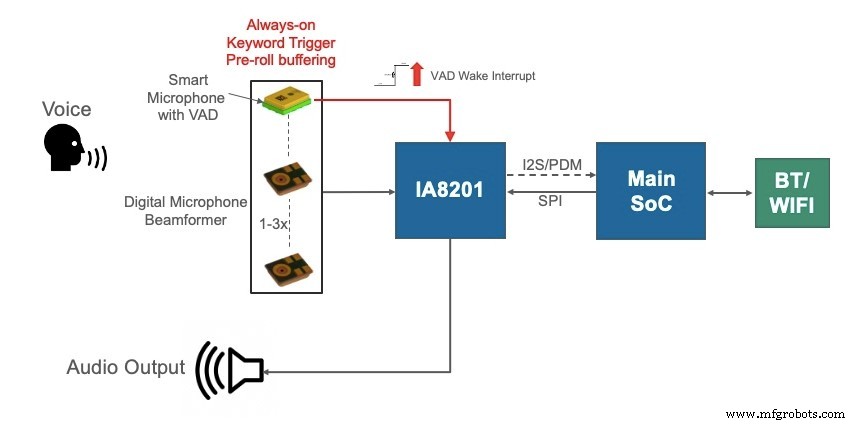
Abbildung 2 zeigt eine Architektur, die Pre-Roll-Pufferung für Geräte wie intelligente Lautsprecher unterstützt. Diese Geräte haben in der Regel größere Batterien und/oder benötigen möglicherweise nicht mehrere Monate Batterielebensdauer mit einer einzigen Ladung. Das VUI-System ist immer eingeschaltet, hört die Umgebung ab und zeichnet Pre-Roll in einem Ringpuffer auf. Die Länge des Pre-Roll liegt normalerweise in der Größenordnung von 500 ms der Audiodaten und wird verwendet, um den Umgebungsgeräuschpegel zu kalibrieren.
Es gibt verschiedene Ansätze, um die Always-on-Front-End-Architektur zu entwerfen. Die Wahl des Audioprozessors hängt von der Anzahl der verwendeten Mikrofone und davon ab, ob es sich um analoge oder digitale Mikrofone handelt.
Die oben gezeigte Architektur verwendet ein Knowles IA611 für die Sprachaktivitätserkennung, SPH0655LM4H-1 Cornell II-Digitalmikrofone für das Beamforming und das Knowles IA8201 für die Audioverarbeitung. Das Knowles IA611 ist ein intelligentes Mikrofon, das Systemdesignern Vorteile bietet, wie im folgenden Abschnitt beschrieben.
Mikrofonauswahl
Für die in Abbildung 1 gezeigte Architektur wird ein einzelnes analoges Mikrofon und ein Komparator als Triggereingang verwendet, um den Audioprozessor aufzuwecken, wenn eine akustische Aktivität erkannt wird. Das Wake-Mikrofon sollte ein analoges Mikrofon mit geringer Leistung und einem Signal-Rausch-Verhältnis (SNR) von vorzugsweise mehr als 62 dB sein. Das Knowles SiSonic MEMS-Mikrofonportfolio bietet mehrere Auswahlmöglichkeiten für das Wake-Mikrofon. Zum Beispiel ist das analoge Mikrofon SPV1840LR5H-B Kaskade eine gute Wahl, das im eingeschalteten Zustand nur 45 µA verbraucht. Der ständig eingeschaltete analoge Pfad, einschließlich Mikrofon, Verstärker und Komparator, verbraucht weniger als 67 µA. Auf dem Markt sind piezoelektrische Mikrofone mit sehr geringer Dauerleistung (10 µA) erhältlich, die jedoch normalerweise ein niedriges SNR haben, was die Systemleistung beeinträchtigen kann.
Für die in Abbildung 2 gezeigte Pre-Roll-Puffering-fähige Architektur sind Mikrofone mit einem eingebetteten Audioprozessor und ausreichend Speicher für die kontinuierliche Erfassung von Sprachdaten in einem Ringpuffer von 2 Sekunden, wie das Knowles IA611, praktikable Optionen für ständige Sprachaktivitäten Erkennung. Es kommt auch mit einem Ökosystem portierter Sprachauslöser und -befehle, wie zum Beispiel Amazons Alexa. Wenn ein Schlüsselwort erkannt wird, werden sowohl der Pre-Roll-Puffer als auch das gesprochene Sprachaudio an die Cloud-Engine für die automatische Spracherkennung (ASR) gesendet. Die ständig eingeschaltete Voice-Wake-Leistung des IA611 beträgt 0,39 mA bei 1,8 V Batterie und 90 Prozent Effizienz, was ihn zu einer guten Wahl für die Sprachbenutzeroberfläche in batteriebetriebenen Geräten wie Bluetooth-Lautsprechern macht. Das Gerät akzeptiert auch PDM-Eingaben von einem digitalen Mikrofon und kann verwendet werden, um Beamforming auf dem Host-BT-SoC-Prozessor zu unterstützen, indem es Audio durchläuft, sobald das System aufwacht.
Während diese immer eingeschaltete Stromversorgung für Pre-Roll-Anwendungen akzeptabel ist, ist sie auch für eine Architektur ohne Pre-Roll in Betracht zu ziehen, wie in Abbildung 1 dargestellt Audio-Prozessor. Dies kann in einer lauten Umgebung problematisch sein, z. B. wenn der Fernseher eingeschaltet ist, in der es zu vielen Störsignalen kommt, die zu erheblicher Energieverschwendung führen. Wenn die Sprachaktivitätserkennung anstelle des analogen Weckmikrofons mit geringem Stromverbrauch verwendet wird, schaltet sich das System nur ein, wenn ein Schlüsselwort erkannt wird. Es ist logisch zu verstehen, warum die Verwendung eines Mikrofons zur Erkennung von Sprachaktivitäten in einer lauten Umgebung möglicherweise effizienter ist als ein einfaches analoges Weckmikrofon.
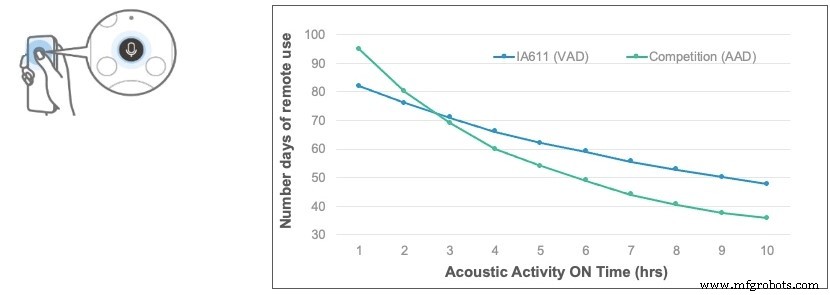
Abbildung 3 zeigt Simulationsdaten, die die Anzahl der Tage der Batterielebensdauer einer typischen TV-Fernbedienung mit VAD auf dem IA611 mit der eines konkurrierenden piezoelektrischen AAD-Mikrofons mit geringer Leistung und einem Audioprozessor für unterschiedliche Dauer der Einschaltzeit akustischer Aktivität vergleichen. Akustische Aktivität kann vorhanden sein, wenn der Fernseher oder andere Haushaltsgeräte eingeschaltet sind, oder in anderen Situationen, in denen Gebrabbel usw auf dem Mikrofon eines Mitbewerbers vs. die Sprachaktivitätserkennung auf dem IA611 verschwindet.
Bei fünf Stunden akustischer Aktivität ON-Zeit bietet die Sprachaktivitätserkennungslösung acht zusätzliche Tage Akkulaufzeit gegenüber der konkurrierenden AAD-basierten Lösung. Um diesen Vorteil in einen Kontext zu setzen, sahen Erwachsene in den USA laut einer 2017 veröffentlichten Nielsen-Studie fast acht Stunden pro Tag fern. Mit der steigenden Nachfrage nach internetfähigen Geräten wie Smart-TVs, Spielekonsolen und anderen Multimediageräten, Auch die Stunden der akustischen Aktivität in einem typischen US-Haushalt werden voraussichtlich weiter zunehmen. Die Verwendung eines intelligenten VAD-basierten Wake-Ups wird Systemdesignern helfen, energieeffizientere VUI-Systeme zu entwickeln.
Schlussfolgerung
Von Smart Home, Hospitality, Digital Workplaces, Voice Payments, Intelligent Energy Management, Voice at the Edge und Healthcare bis hin zu industriellen IoT-Anwendungen, die den Produktionsbereich verändern – Voice verleiht neuen Technologien Flexibilität, Effizienz, Nachhaltigkeit und Akzeptanz.
Die verschiedenen Hardwarearchitekturen für das Design einer Sprachbenutzeroberfläche, zusammen mit dem Mikrofonbereich, erfüllen jeweils einen etwas anderen Bedarf, abhängig von den Anwendungen des Endgeräts und den Präferenzen des Designers; Alexa-fähige Geräte und intelligente Lautsprecher erfordern beispielsweise eine Pre-Roll-Buffering-fähige Architektur.
Es ist wichtig, dass Elektronikingenieure und -designer sorgfältig prüfen, wie das Endgerät Sprache und Funktionen nutzen wird, auf die es zugreifen möchte, und von dort aus die richtige Architektur und die entsprechenden Mikrofonkomponenten bestimmen.

Raj Senguttuvan verfügt über mehr als 15 Jahre Erfahrung in der Entwicklung neuer Technologien für Verbraucher- und Industrieanwendungen, in der frühen Geschäftsentwicklung und im Projektmanagement für Unternehmen wie Analog Devices und Texas Instruments. In seiner Funktion als Direktor für strategisches Marketing bei Knowles leitet er die Entwicklung auf Systemebene, treibt Venture-Investitionen und Partnerschaften sowie die Marketingstrategie für IoT- und Verbrauchertechnologien einschließlich Audioprozessoren, Algorithmen, Mikrofone, Sensoren und Empfänger voran. Raj hat einen MBA der Cornell University und einen Doktortitel in Elektrotechnik vom Georgia Institute of Technology.
Ähnliche Inhalte :
- Sprache auf einem Mikrocontroller hinzufügen, ohne codieren zu müssen
- Was steckt hinter der Umstellung auf benutzerdefinierte Sprachagenten?
- Sprachbiometrielösung zielt auf Authentifizierung ab
- KI findet ihre Stimme in der Audiokette
- Wie umfangreiche Signalverarbeitungsketten Sprachassistenten „einfach funktionieren“ lassen
- Entwicklungskits beschleunigen die Alexa-Integration
Sensor
- 6 wichtige Designüberlegungen für den 3D-Metalldruck
- Vorteile eingebetteter Technologien für modulares Design
- Überlegungen zum PCB-Layout
- Design für die Herstellung von Leiterplatten
- Überlegungen zum Beleuchtungsdesign für robotergestützte Chirurgie-Sichtsysteme
- Warum Rückverfolgbarkeit eine wesentliche Grundlage für IIoT-fähige Fertigungssysteme ist
- Ein von Spinnen inspiriertes Design ebnet den Weg für bessere Fotodetektoren
- Wichtige Überlegungen zur Leiterplattenbestückung
- Überlegungen zum Impedanzdesign für starrflexible PCB
- Überlegungen zum Antennendesign im IoT-Design