


Wie umfangreiche Signalverarbeitungsketten dafür sorgen, dass Sprachassistenten „einfach funktionieren“
Intelligente Lautsprecher und sprachgesteuerte Geräte werden immer beliebter, wobei Sprachassistenten wie Amazons Alexa und Googles Assistent unsere Anfragen immer besser verstehen.
Einer der Hauptvorteile dieser Art von Benutzeroberfläche ist, dass sie „einfach funktioniert“ – es gibt keine Benutzeroberfläche, die man lernen muss, und wir können zunehmend in einer natürlichen Sprache mit einem Gerät sprechen, als ob es eine Person wäre, und erhalten eine nützliche Antwort. Aber um diese Fähigkeit zu erreichen, ist eine Menge ausgeklügelter Verarbeitung im Gange.
In diesem Artikel betrachten wir die Architektur sprachgesteuerter Lösungen und diskutieren, was unter der Haube passiert und welche Hardware und Software erforderlich ist.
Signalfluss und Architektur
Obwohl es viele Arten von sprachgesteuerten Geräten gibt, sind die Grundprinzipien und der Signalfluss ähnlich. Betrachten wir einen intelligenten Lautsprecher wie Amazons Echo und schauen wir uns die wichtigsten Subsysteme und Module zur Signalverarbeitung an.
Abbildung 1 zeigt die gesamte Signalkette in einem intelligenten Lautsprecher.
Klicken für größeres Bild
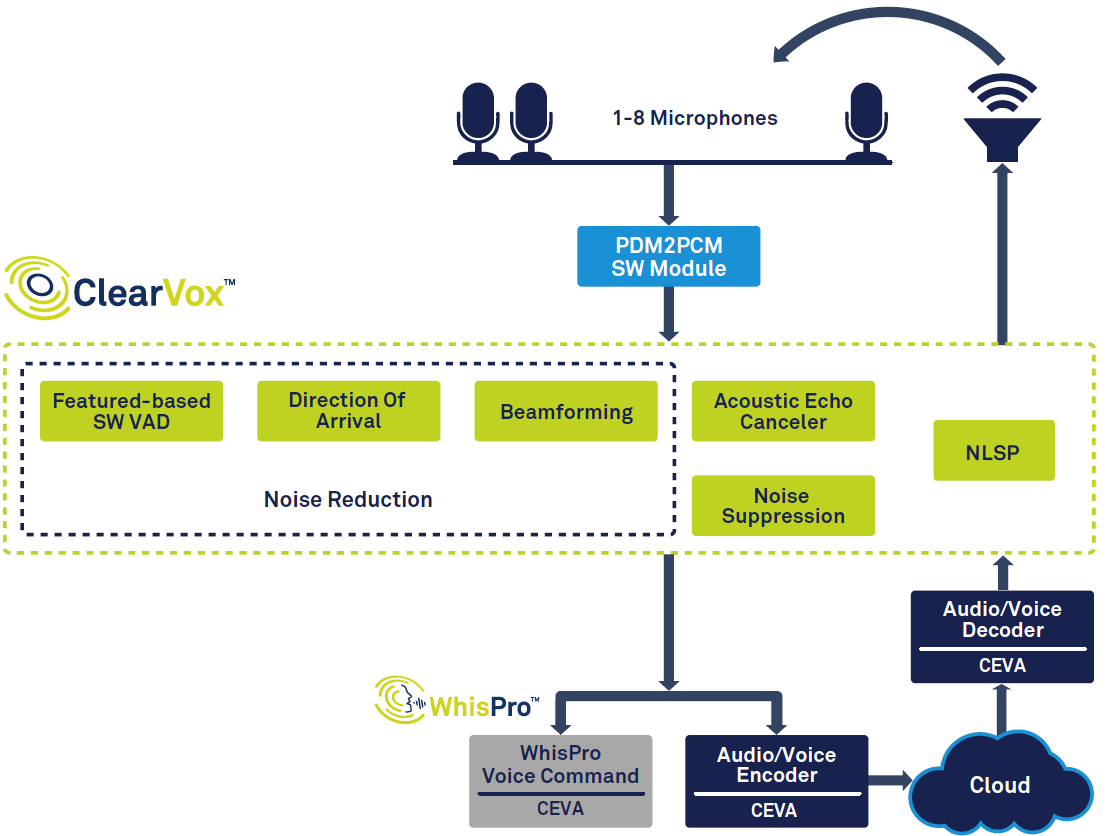
Abbildung 1:Signalkette für Sprachassistenten, basierend auf CEVAs ClearVox und WhisPro. (Quelle:CEVA)
Auf der linken Seite des Diagramms können Sie sehen, dass eine Stimme, sobald sie mit der Sprachaktivitätserkennung (VAD) erkannt wurde, digitalisiert und durch mehrere Signalverarbeitungsstufen geleitet wird, um die Klarheit der Stimme der gewünschten Hauptsprecherstimme zu verbessern Richtung ankommen. Die digitalisierten, verarbeiteten Sprachdaten werden dann an die Backend-Sprachverarbeitung übergeben, die teilweise am Edge (auf dem Gerät) und teilweise in der Cloud stattfinden kann. Schließlich wird bei Bedarf eine Antwort erstellt und vom Lautsprecher ausgegeben, was eine Dekodierung und eine Digital-Analog-Wandlung erfordert.
Für andere Anwendungen kann es einige Unterschiede und unterschiedliche Prioritäten geben – beispielsweise müsste eine Sprachschnittstelle im Fahrzeug optimiert werden, um typische Hintergrundgeräusche in Autos zu verarbeiten. Es gibt auch einen allgemeinen Trend zu geringerer Leistung und geringeren Kosten, angetrieben durch die Nachfrage nach kleineren Geräten wie In-Ear-Hearables und kostengünstigen Haushaltsgeräten.
Front-End-Signalverarbeitung
Sobald eine Stimme erkannt und digitalisiert wurde, sind mehrere Signalverarbeitungsaufgaben erforderlich. Neben externen Geräuschen müssen wir auch Geräusche berücksichtigen, die vom Abhörgerät erzeugt werden, beispielsweise ein intelligenter Lautsprecher, der Musik ausgibt, oder ein Gespräch mit einer Person, die am anderen Ende der Leitung spricht. Um diese Geräusche zu unterdrücken, verwendet das Gerät die akustische Echounterdrückung (AEC), sodass der Benutzer einen intelligenten Lautsprecher aufrufen und unterbrechen kann, selbst wenn dieser bereits Musik abspielt oder spricht. Sobald diese Echos entfernt sind, werden Rauschunterdrückungsalgorithmen verwendet, um externes Rauschen zu bereinigen.
Obwohl es viele verschiedene Anwendungen gibt, können wir sie für sprachgesteuerte Geräte in zwei Gruppen verallgemeinern:Nahfeld- und Fernfeld-Sprachaufnahme. Nahfeldgeräte wie Headsets, Ohrhörer, Hearables und Wearables werden in der Nähe des Mundes des Benutzers gehalten oder getragen, während Fernfeldgeräte wie intelligente Lautsprecher und Fernseher darauf ausgelegt sind, die Stimme eines Benutzers über einen Raum hinweg zu hören.
Nahfeldgeräte verwenden normalerweise ein oder zwei Mikrofone, aber Fernfeldgeräte verwenden oft zwischen drei und acht. Der Grund dafür ist, dass das Fernfeldgerät vor größeren Herausforderungen steht als das Nahfeld:Je weiter sich der Benutzer entfernt, wird seine Stimme, die die Mikrofone erreicht, immer leiser, während die Hintergrundgeräusche auf dem gleichen Niveau bleiben. Gleichzeitig muss das Gerät auch das direkte Sprachsignal von Reflexionen an Wänden und anderen Oberflächen, auch Nachhall genannt, trennen.
Um diese Probleme zu lösen, verwenden Fernfeldgeräte eine Technik namens Beamforming. Dies verwendet mehrere Mikrofone und berechnet die Richtung der Schallquelle basierend auf den Zeitunterschieden zwischen den an jedem Mikrofon ankommenden Schallsignalen. Dadurch kann das Gerät Reflexionen und andere Geräusche ignorieren und dem Benutzer einfach zuhören – sowie seine Bewegungen verfolgen und die richtige Stimme heranzoomen, wenn mehrere Personen sprechen.
Eine weitere wichtige Aufgabe für Smart Speaker besteht darin, das „Trigger“-Wort wie „Alexa“ zu erkennen. Da der Sprecher immer zuhört, wirft diese Trigger-Erkennung Datenschutzprobleme auf – wenn das Audio des Benutzers ständig in die Cloud hochgeladen wird, auch wenn er das Triggerwort nicht sagt, fühlen sie sich dann wohl, wenn Amazon oder Google alle ihre Gespräche hören? Stattdessen kann es vorzuziehen sein, die Triggererkennung sowie viele gängige Befehle wie „Lautstärke lauter“ lokal auf dem Smart Speaker selbst zu handhaben, wobei Audio erst an die Cloud gesendet wird, nachdem der Benutzer einen komplexeren Befehl gestartet hat.
Schließlich muss die saubere Sprachprobe codiert werden, bevor sie schließlich zur weiteren Verarbeitung an das Cloud-Back-End gesendet wird.
Speziallösungen
Aus der obigen Beschreibung wird deutlich, dass die Frontend-Sprachverarbeitung viele Aufgaben bewältigen muss. Es muss dies schnell und genau tun, und bei batteriebetriebenen Geräten muss der Stromverbrauch möglichst gering gehalten werden – auch wenn das Gerät ständig auf ein Triggerwort lauscht.
Um diesen Anforderungen gerecht zu werden, sind Allzweck-Digitalsignalprozessoren (DSPs) oder Mikroprozessoren wahrscheinlich nicht ausreichend – in Bezug auf Kosten, Verarbeitungsleistung, Größe und Stromverbrauch. Stattdessen ist wahrscheinlich ein anwendungsspezifischer DSP mit dedizierten Audioverarbeitungsfunktionen und optimierter Software eine bessere Lösung. Die Wahl einer Hardware-/Softwarelösung, die bereits für die Spracheingabeaufgaben optimiert ist, reduziert außerdem die Entwicklungskosten und verkürzt die Markteinführungszeit erheblich sowie die Gesamtkosten.
ClearVox von CEVA ist beispielsweise eine Software-Suite von Spracheingabeverarbeitungsalgorithmen, die verschiedene akustische Szenarien und Mikrofonkonfigurationen bewältigen kann, einschließlich der Ankunftsrichtung der Sprecherstimme, Multi-Mic-Beamforming, Rauschunterdrückung und akustischer Echokompensation. ClearVox ist für den effizienten Betrieb auf CEVA-Sound-DSPs optimiert und bietet eine kostengünstige Lösung mit geringem Stromverbrauch.
Neben der Sprachverarbeitung benötigt das Edge-Gerät die Fähigkeit, die Triggerworterkennung zu handhaben. Eine spezialisierte Lösung wie WhisPro von CEVA ist eine hervorragende Möglichkeit, die erforderliche Genauigkeit und den geringen Stromverbrauch zu erreichen (siehe Abbildung 2). WhisPro ist ein auf einem neuronalen Netzwerk basierendes Spracherkennungs-Softwarepaket, das exklusiv für CEVAs DSPs erhältlich ist und es OEMs ermöglicht, ihre sprachaktivierten Produkte um Sprachaktivierung zu erweitern. Er kann das erforderliche Dauerhören bewältigen, während ein Hauptprozessor im Ruhezustand bleibt, bis er benötigt wird, wodurch der Gesamtstromverbrauch des Systems erheblich reduziert wird.
Klicken für größeres Bild
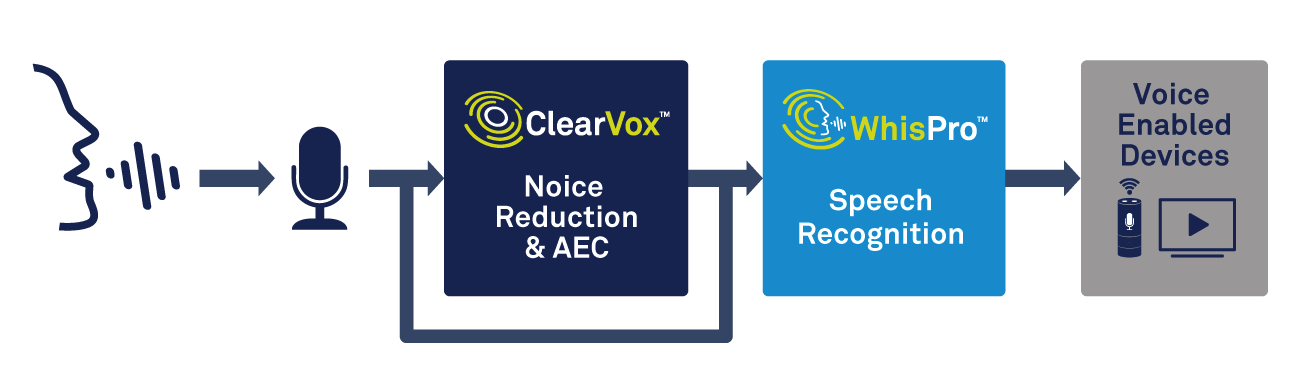
Abbildung 2:Verwendung von Sprachverarbeitung und Spracherkennung zur Sprachaktivierung. (Quelle:CEVA)
WhisPro kann eine Erkennungsrate von mehr als 95 % erreichen und kann mehrere Triggerphrasen sowie benutzerdefinierte Triggerwörter unterstützen. Wie jeder, der einen Smart Speaker verwendet hat, bezeugen kann, kann es manchmal frustrierend sein, ihn dazu zu bringen, zuverlässig auf das Weckwort zu reagieren – selbst in einer lauten Umgebung. Die richtige Einstellung dieser Funktion kann einen großen Einfluss darauf haben, wie Verbraucher die Qualität eines sprachgesteuerten Produkts wahrnehmen.
Spracherkennung:lokal oder Cloud
Sobald die Stimme digitalisiert und verarbeitet wurde, benötigen wir eine Art automatische Spracherkennung (ASR). Es gibt ein breites Spektrum an ASR-Technologien, von der einfachen Schlüsselworterkennung, bei der ein Benutzer bestimmte Schlüsselwörter sagen muss, bis hin zu ausgeklügelter natürlicher Sprachverarbeitung (NLP), bei der ein Benutzer normal sprechen kann, als würde er eine andere Person ansprechen.
Die Schlüsselworterkennung hat viele Verwendungsmöglichkeiten, auch wenn ihr Vokabular äußerst begrenzt ist. Ein einfaches Smart-Home-Gerät wie ein Lichtschalter oder ein Thermostat kann beispielsweise nur auf wenige Befehle wie „Ein“, „Aus“, „Heller“, „Dimmer“ usw. reagieren. Diese ASR-Ebene kann problemlos lokal am Edge ohne Internetverbindung gehandhabt werden – wodurch die Kosten niedrig gehalten, eine schnelle Reaktion gewährleistet und Sicherheits- und Datenschutzbedenken vermieden werden.
Ein weiteres Beispiel wäre, dass viele Android-Smartphones mit „Käse“ oder „Lächeln“ aufgefordert werden, ein Foto zu machen, wo das Senden des Befehls in die Cloud einfach zu lange dauern würde. Und das setzt voraus, dass eine Internetverbindung verfügbar ist, was bei Geräten wie einer Smartwatch oder einem Hearable nicht immer der Fall sein wird.
Andererseits erfordern viele Anwendungen NLP. Wenn Sie Ihren Echo-Lautsprecher nach dem Wetter fragen oder ein Hotel für heute Nacht suchen möchten, können Sie Ihre Frage auf viele verschiedene Arten formulieren. Das Gerät muss in der Lage sein, die möglichen Nuancen und Umgangssprachen im Befehl zu verstehen und das Gefragte zuverlässig zu verarbeiten. Einfach ausgedrückt muss es in der Lage sein, Sprache in Bedeutung umzuwandeln, anstatt nur Sprache in Text zu verwandeln.
Um ein Beispiel für unsere Hotelanfrage zu nehmen, gibt es eine Vielzahl möglicher Faktoren, nach denen Sie fragen möchten:Preis, Lage, Bewertungen und vieles mehr. Das NLP-System muss all diese Komplexität sowie die vielen unterschiedlichen Formulierungen einer Frage und einen Mangel an Klarheit in der Anfrage interpretieren - zu sagen "Suchen Sie mir ein günstiges, zentrales Hotel" bedeutet unterschiedliche Dinge Menschen. Um genaue Ergebnisse zu erzielen, muss das Gerät auch den Kontext der Frage berücksichtigen und erkennen, wenn der Benutzer verbundene Folgefragen stellt oder mehrere Informationen innerhalb einer Abfrage abfragt.
Dies kann einen enormen Verarbeitungsaufwand erfordern, typischerweise unter Verwendung von künstlicher Intelligenz (KI) und neuronalen Netzen, was für die Verarbeitung nur am Rand meist nicht praktikabel ist. Ein kostengünstiges Gerät mit einem eingebetteten Prozessor hat nicht genug Leistung, um die erforderlichen Aufgaben zu bewältigen. In diesem Fall ist es die richtige Option, die digitalisierte Sprache zur Verarbeitung in die Cloud zu senden. Dort kann es interpretiert und eine entsprechende Antwort an das sprachgesteuerte Gerät zurückgesendet werden.
Sie sehen, dass es Kompromisse zwischen der Edge-Verarbeitung auf dem Gerät und der Remote-Verarbeitung in der Cloud gibt. Alles lokal zu handhaben kann schneller sein und ist nicht auf eine Internetverbindung angewiesen, wird aber Schwierigkeiten haben, mit einer breiteren Palette von Fragen und dem Abrufen von Informationen fertig zu werden. Dies bedeutet, dass für ein Allzweckgerät, wie beispielsweise ein intelligenter Lautsprecher zu Hause, zumindest ein Teil der Verarbeitung in die Cloud verschoben werden muss.
Um die Nachteile der Cloud-Verarbeitung zu beheben, werden die Fähigkeiten lokaler Prozessoren weiterentwickelt, und in naher Zukunft können wir große Verbesserungen bei NLP und KI in Edge-Geräten erwarten. Neue Techniken reduzieren den benötigten Speicher und Prozessoren werden immer schneller und verbrauchen weniger Strom.
CEVAs NeuPro-Familie von energiesparenden KI-Prozessoren bietet beispielsweise ausgereifte Funktionen für den Edge. Aufbauend auf der Erfahrung von CEVA mit neuronalen Netzen für Computer Vision bietet diese Familie eine flexible, skalierbare Lösung für die Sprachverarbeitung auf dem Gerät.
Schlussfolgerungen
Sprachgesteuerte Schnittstellen werden immer mehr zu einem wichtigen Bestandteil unseres Alltags und werden in naher Zukunft immer mehr Produkten hinzugefügt. Verbesserungen werden durch bessere Signalverarbeitungs- und Spracherkennungsfunktionen sowie leistungsfähigere Rechenressourcen sowohl lokal als auch in der Cloud vorangetrieben.
Um den Anforderungen der OEMs gerecht zu werden, müssen die für die Audioverarbeitung und Spracherkennung verwendeten Komponenten hohe Anforderungen an Leistung, Kosten und Leistung erfüllen. Für viele Konstrukteure können sich speziell auf die jeweilige Aufgabenstellung optimierte Lösungen als der beste Weg erweisen – die Anforderungen des Endkunden zu erfüllen und die Markteinführungszeit zu verkürzen.
Unabhängig von der Technologie, auf der sie basieren, werden Sprachschnittstellen präziser und leichter in der Alltagssprache zu sprechen, während sie durch sinkende Kosten für Hersteller attraktiver werden. Es wird eine interessante Reise zu sehen, wofür sie als nächstes verwendet werden.
Eingebettet
- Verbesserte Technologien beschleunigen die Akzeptanz von Sprachassistenten
- Wie man Glasfaser herstellt
- Wie Sie jetzt das Beste aus Ihrer Lieferkette machen
- Wie funktionieren SCADA-Systeme?
- So erstellen Sie einen Kompass mit Arduino und Processing IDE
- So erstellen Sie einen Prototyp
- Wie funktionieren Lufttrockner?
- Wie man die Elektronik von morgen mit Tintenstrahl-gedrucktem Graphen herstellt
- Funktionsweise elektrischer Bremsen
- Wie man ein umfassendes Sicherheitsprogramm zum Laufen bringt