


Grundlegende Anmerkung zum maschinellen Lernen und seinen vier Haupttypen für Anfänger
Kein Zweifel, dass Big Data ist ein wesentlicher Bestandteil der zukünftigen technologischen Entwicklung. Allerdings spielen maschinelles Lernen (ML) und künstliche Intelligenz (KI) beide eine wichtige Rolle in dieser Entwicklung. Die Beziehung zwischen diesen dreien wird kurz erklärt:Big Data ist für Materialien, maschinelles Lernen ist für Methoden und künstliche Intelligenz ist für Ergebnisse.
Was ist maschinelles Lernen?
Maschinelles Lernen (ML) ist eine der Arten von künstlicher Intelligenz (KI), bei der Algorithmen so geschrieben sind, dass das System die Fähigkeit erhält, durch die Erfahrung automatisch zu lernen, sich anzupassen und automatisch zu verbessern, ohne explizit programmiert zu werden .
Die Algorithmen für maschinelles Lernen erstellen ein beispielhaftes Modell, das auf der Art von Daten basiert, die es lernen soll. Diese Art von Daten wird als „Trainingsdaten“ bezeichnet.
Arten des maschinellen Lernens?
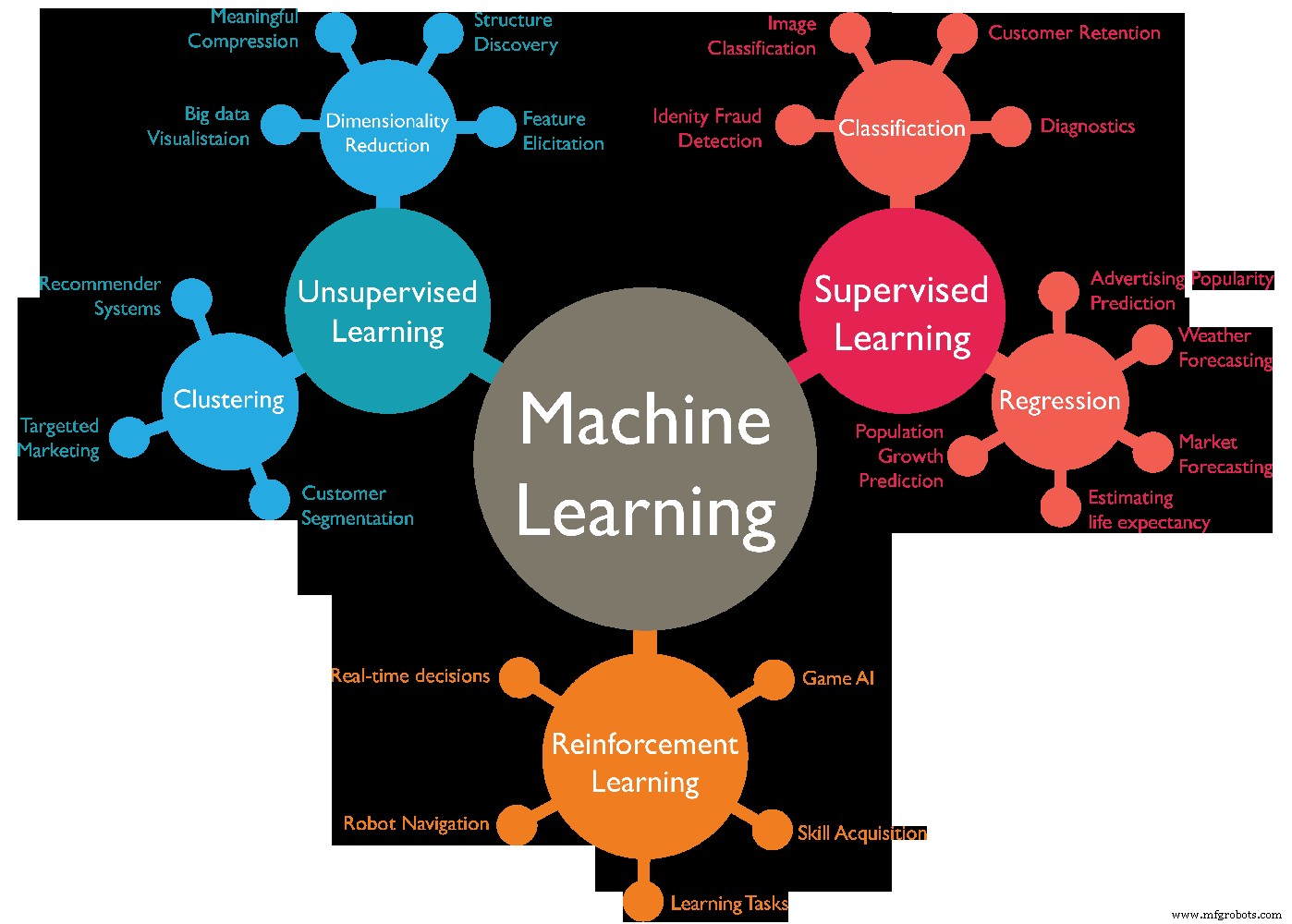
Es gibt verschiedene Arten von maschinellen Lernalgorithmen, die üblicherweise in 4 Kategorien unterteilt werden können. Verschiedene Arten des maschinellen Lernens sind wie folgt:-
- Überwachtes Lernen.
- Unbeaufsichtigtes Lernen.
- Halbüberwachtes Lernen.
- Verstärkendes Lernen.
Überwachtes Lernen
Wenn die Maschine überwacht wird, während sie sich in der „Lernphase“ befindet, wird diese Art des Trainings als überwachtes Lernen bezeichnet. Was meinen wir wirklich, wenn wir sagen, dass eine Maschine überwacht wird? ?. Was es wirklich bedeutet, Algorithmen so anzuwenden, dass die Maschine lernt, ihre alten Daten (in der Vergangenheit bereitgestellte Daten) zu verwenden und sie zu verwenden, um Vorhersagen über zukünftige Ereignisse in Bezug auf die Art der eingegebenen Daten, d. h. alte Daten, zu treffen.
Die Analyse wird gestartet und alle Materialien im Trainingsdatensatz und gekennzeichnet korrelieren so mit der Maschine, dass sie eine Vorhersage über die korrekten Ausgabewerte treffen kann. Das bedeutet, dass wir der Maschine viele Informationen über einen bestimmten Fall liefern und sie dann ein Fallergebnis liefert. Das Ergebnis wird als beschriftete Daten bezeichnet, während der Rest der Informationen als Eingabemerkmale verwendet wird. Das System kann dann nach ausreichendem Training auch Ziele für neue Eingaben liefern. Der Algorithmus kann seine Ausgabe mit der beabsichtigten Ausgabe vergleichen und Unterschiede finden, um das Modell entsprechend zu ändern.
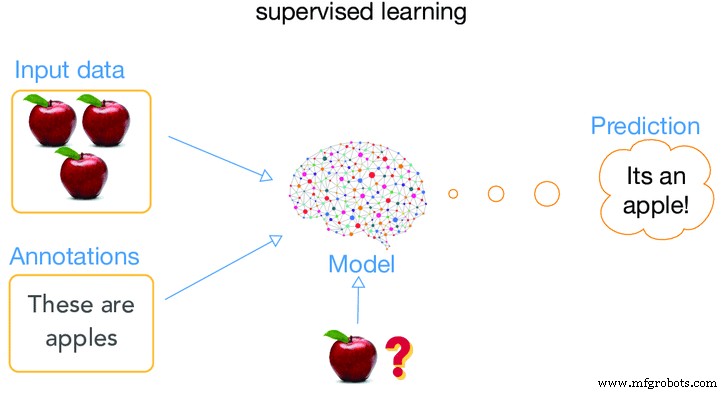
image Mit freundlicher Genehmigung von artificialintelligence.oodles.io/
Meistens handelt es sich bei dieser Methode um eine manuelle Klassifizierung, die für einen Computer am einfachsten und für Menschen am schwierigsten durchzuführen ist. Ein Beispiel für dieses Verfahren ist, der Maschine Standardantworten mitzuteilen, und wenn die Maschine getestet wird, wird die Maschine immer gemäß der Standardantwort antworten und daher wird ihre Zuverlässigkeit auch größer sein.
Unbeaufsichtigtes Lernen
Im Gegensatz zum überwachten Lernen werden unüberwachte Lernalgorithmen verwendet, wenn die Informationen, die zum Trainieren der Maschine verwendet werden, weder klassifiziert noch gekennzeichnet sind. Wie der Name schon sagt, wird beim unüberwachten Lernen dem Computer keine Hilfe vom Benutzer angeboten, um zu helfen es lernen.
Das bereitgestellte Material hat kein Etikett, und die Maschine gleicht dann die Merkmale der Daten ab und klassifiziert die Materialien. Aufgrund des Fehlens gekennzeichneter Trainingssätze erkennt die Maschine dann Muster in den Daten, die für den Menschen nicht so offensichtlich sind.
image Mit freundlicher Genehmigung von data-flair.training/Bei dieser Methode gibt es keine manuelle Klassifizierung, die für den Menschen am einfachsten, für den Computer jedoch am schwierigsten ist und viel mehr Fehler verursachen kann. Das System findet meistens nicht die beabsichtigte Ausgabe heraus, aber es recherchiert die bereitgestellten Daten und kann Beziehungen aus Datensätzen ziehen, um verborgene Strukturen aus unbeschrifteten Daten zu beschreiben. Daher ist das Erkennen von Mustern in Daten durch unüberwachtes Lernen äußerst nützlich und hilft uns auch bei der Entscheidungsfindung.
Halbüberwachtes Lernen
Semi-überwachtes Lernen unterscheidet sich von überwachtem Lernen und unüberwachtem Lernen, bei dem entweder keine Bezeichnungen für die gesamte Beobachtung von Daten vorhanden sind oder Bezeichnungen vorhanden sind.
In Semi-supervised werden sowohl gekennzeichnete (überwachte) als auch nicht gekennzeichnete (unüberwachte) Daten für das Training verwendet. SSL ist eine Mischung aus den beiden Lerntypen, bei denen eine kleine Datenmenge gekennzeichnet und große Datenmengen nicht gekennzeichnet sind. Die Maschine muss Merkmale anhand gekennzeichneter Daten finden und dann unter Verwendung des Basismodells andere Daten entsprechend klassifizieren. SSL-Systeme können nicht nur ihre Lerngenauigkeit erheblich verbessern, sondern auch genauere Vorhersagen treffen.
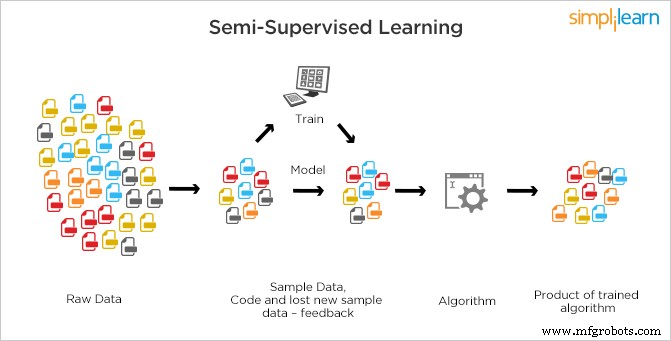
Dies ist die am häufigsten verwendete Methode, da die Kosten für die Etikettierung hoch sind, da qualifizierte menschliche Experten erforderlich sind. Es erfordert relevante Ressourcen, um es zu trainieren und daraus zu lernen, während das Erfassen von unbeschrifteten Daten im Allgemeinen keine zusätzlichen Ressourcen erfordert. Aufgrund des Fehlens von Labels in der Mehrzahl der Beobachtungen, aber des Vorhandenseins einiger weniger, werden halbüberwachte Algorithmen als beste Kandidaten zum Erstellen eines Modells bevorzugt.
Diese Methoden profitieren von der Idee, dass, obwohl die Gruppenmitglieder unbekannt sind, weil unbeschriftete Daten allgemeiner sind, Informationen über die Parameter immer noch in den beschrifteten enthalten sind und damit gefunden werden können.
Verstärkendes Lernen
Bestärkendes Lernen kommt dem, wie wir Menschen lernen, am nächsten. RML-Algorithmen sind eine Lernmethode, bei der die Maschine wiederholt mit ihrer Umgebung interagiert, indem sie neue Aktionen konstruiert und Fehler oder Belohnungen entdeckt. Es verwendet ein auf positiver oder negativer Belohnung basierendes System.
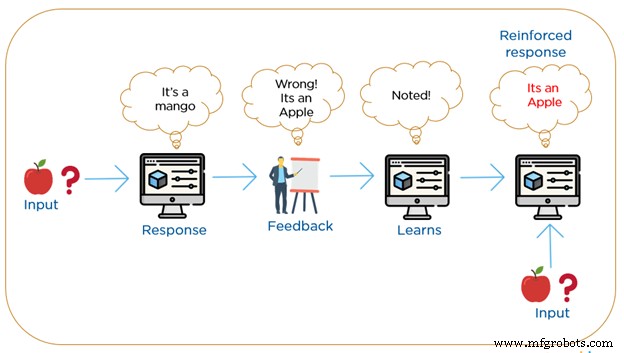
Trial-and-Error-Suche mit verzögerter Belohnung ist die relevanteste Eigenschaft des bestärkenden Lernens. Die Maschine konstruiert ein Verhalten unter Verwendung von Beobachtungen, die bei der Interaktion mit der Umgebung gesammelt wurden, und ergreift Maßnahmen, die die Belohnung maximieren oder das Risiko minimieren würden. Mit dieser Methode können die Maschinen automatisch das ideale Verhalten innerhalb eines bestimmten Kontexts ermitteln, um ihre Leistung zu steigern. Beim Reinforcement Learning gibt es keine beschrifteten Materialien, sondern es erfordert ein einfaches Feedback, welcher Schritt richtig und welcher falsch ist, dies wird als Reinforcement Signal bezeichnet.

Gemäß dem Feedback-Standard überarbeitet die Maschine schrittweise ihre Klassifizierung, bis sie schließlich das richtige Ergebnis erhält. Die Integration von Reinforcement Learning ist notwendig, um beim unüberwachten Lernen ein gewisses Maß an Präzision zu erreichen,
RML ist wahrscheinlich am schwierigsten in einer Geschäftsumgebung zu produzieren und auszuführen, aber es wird häufig für selbstfahrende Autos verwendet.
Industrietechnik
- Die Lieferkette und maschinelles Lernen
- Vier Schlüsselfragen zur Erschließung der Leistungsfähigkeit von Live-Felddaten
- Elementary Robotics sammelt 13 Millionen US-Dollar für seine Angebote für maschinelles Lernen und Computer Vision für die Industrie
- Maschinelles Lernen im Feld
- Die Rolle der Datenanalyse für Asset Owner in der Öl- und Gasindustrie
- Die vielen Arten von Polyurethan und wofür sie verwendet werden
- AWS stärkt seine Angebote für KI und maschinelles Lernen
- Was ist eine Fräsmaschine und wofür wird sie verwendet?
- Kepware vs. MachineMetrics:Was ist die bessere Lösung für die Maschinendatenerfassung?
- Die 9 maschinellen Lernanwendungen, die Sie kennen sollten