


So implementieren Sie die Ziffernerkennung mit TensorFlow Lite unter Verwendung einer i.MX RT1060 Crossover-MCU
Dieser Artikel befasst sich mit der Ziffernerkennung und -erkennung am Beispiel von MNIST eIQ, das aus mehreren Teilen besteht – die Ziffernerkennung wird von einem TensorFlow Lite-Modell durchgeführt , und eine GUI wird verwendet, um die Benutzerfreundlichkeit des i.MX RT1060-Geräts zu erhöhen.
Die Crossover-MCU i.MX RT1060 eignet sich gleichermaßen für kostengünstige Industrieanwendungen und leistungsstarke und datenintensive Consumer-Produkte, die Display-Funktionalitäten benötigen. In diesem Artikel werden die Fähigkeiten dieser Arm® Cortex®-M7-basierten MCU demonstriert, indem erklärt wird, wie eine eingebettete Anwendung für maschinelles Lernen implementiert wird, die handschriftliche Eingaben eines Benutzers erkennen und klassifizieren kann.
Zu diesem Zweck konzentriert sich dieser Artikel auf das beliebte MNIST eIQ-Beispiel, das aus mehreren Teilen besteht – die Ziffernerkennung wird von einem TensorFlow Lite-Modell durchgeführt und eine GUI wird verwendet, um die Benutzerfreundlichkeit des i.MX RT1060-Geräts zu erhöhen.
Ein Blick auf den MNIST-Datensatz und das MNIST-Modell
Der in diesem Artikel verwendete Datensatz besteht aus 60.000 Trainings- und 10.000 Testbeispielen von zentrierten Graustufenbildern handgeschriebener Ziffern. Jedes Sample hat eine Auflösung von 28x28 Pixel:

Abbildung 1. Beispiel für einen MNIST-Datensatz
Die Proben wurden von High-School-Studenten und Mitarbeitern des Census Bureau in den USA gesammelt. Daher enthält der Datensatz hauptsächlich Beispiele für Zahlen, wie sie in Nordamerika geschrieben werden. Für Zahlen im europäischen Stil muss beispielsweise ein anderer Datensatz verwendet werden. Neuronale Faltungsnetzwerke liefern normalerweise die besten Ergebnisse, wenn sie mit diesem Datensatz verwendet werden, und selbst einfache Netzwerke können eine hohe Genauigkeit erreichen. Daher war TensorFlow Lite eine geeignete Option für diese Aufgabe.
Die für diesen Artikel ausgewählte MNIST-Modellimplementierung ist auf GitHub als eines der offiziellen TensorFlow-Modelle verfügbar und in Python geschrieben. Das Skript verwendet die Keras-Bibliothek und tf.data, tf.estimator.Estimator und tf.layers API und erstellt ein neuronales Faltungsnetzwerk, das eine hohe Genauigkeit bei den Testproben erreichen kann:
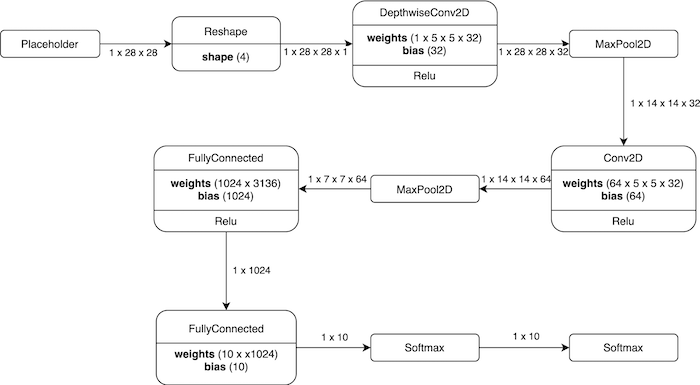
Abbildung 2. Eine Visualisierung des verwendeten Modells.
Die entsprechende Modelldefinition ist unten in Abbildung 3 dargestellt.
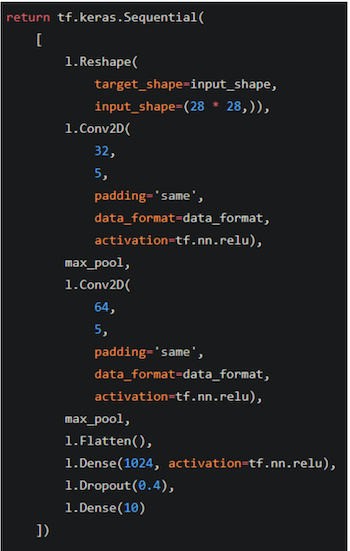
Abbildung 3. Die Modelldefinition, die der Visualisierung des Modells entspricht.
Was ist TensorFlow Lite und wie wird es in diesem Beispiel verwendet?
TensorFlow ist ein bekanntes Deep-Learning-Framework, das in der Produktion von großen Unternehmen weit verbreitet ist. Es handelt sich um eine Open-Source-, plattformübergreifende Deep-Learning-Bibliothek, die von Google entwickelt und gepflegt wird. Eine Low-Level-Python-API, die für erfahrene Entwickler nützlich ist, und High-Level-Bibliotheken, wie sie in diesem Fall verwendet werden, stehen zur Verfügung. Darüber hinaus wird TensorFlow von einer großen Community und einer hervorragenden Online-Dokumentation, Lernressourcen, Leitfäden und Beispielen von Google unterstützt.
Um rechnerisch eingeschränkten Maschinen wie mobilen Geräten und eingebetteten Lösungen die Möglichkeit zu geben, TensorFlow-Anwendungen auszuführen, hat Google das TensorFlow Lite-Framework entwickelt, das nicht alle Operationen des TensorFlow-Frameworks unterstützt. Es ermöglicht solchen Geräten, Inferenz auf vortrainierte TensorFlow-Modelle auszuführen, die in TensorFlow Lite konvertiert wurden. Als Belohnung können diese konvertierten Modelle nicht weiter trainiert werden, sondern können durch Techniken wie Quantisierung und Pruning optimiert werden.
Konvertieren des Modells in TensorFlow Lite
Das oben beschriebene trainierte TensorFlow-Modell muss in TensorFlow Lite konvertiert werden, bevor es auf der i.MX RT1060 MCU verwendet werden kann. Dazu wurde es mit tflite_convert konvertiert und aus Kompatibilitätsgründen wurde Version 1.13.2 von TensorFlow zum Trainieren und Konvertieren des Modells verwendet:
tflite_convert
--saved_model_dir=
--output_file=converted_model.tflite
--input_shape=1,28,28
--input_array=Platzhalter
--output_array=Softmax
--inference_type=FLOAT
--input_data_type=FLOAT
--post_training_quantize
--target_ops TFLITE_BUILTINS
Schließlich wurde das xdd-Dienstprogramm verwendet, um das TensorFlow Lite-Modell in ein binäres Array zu konvertieren, das von der Anwendung geladen werden soll:
xxd -i convert_model.tflite> convert_model.h
xdd ist ein Hex-Dump-Dienstprogramm, das verwendet werden kann, um die binäre Form einer Datei in die entsprechende Hex-Dump-Darstellung zu konvertieren und umgekehrt. In diesem Fall wird die TensorFlow Lite-Binärdatei in eine C/C++-Headerdatei konvertiert, die einem eIQ-Projekt hinzugefügt werden kann. Der Konvertierungsprozess und das Dienstprogramm tflite_convert werden in den eIQ-Benutzerhandbüchern ausführlicher beschrieben. Das Dienstprogramm wird auch in der offiziellen Google-Dokumentation beschrieben.
Eine kurze Einführung in Embedded Wizard Studio
Um die Grafikfähigkeiten des MIMXRT1060-EVK zu nutzen, wurde in diesem Projekt eine GUI integriert. Zu diesem Zweck wurde Embedded Wizard Studio verwendet, eine IDE zur Entwicklung von GUIs für Anwendungen, die auf eingebetteten Geräten laufen. Obwohl eine kostenlose Testversion der IDE verfügbar ist, begrenzt diese Version die maximale Komplexität der grafischen Benutzeroberfläche und fügt der GUI ein Wasserzeichen hinzu.
Einer der Vorteile von Embedded Wizard Studio ist seine Fähigkeit, MCUXpresso- und IAR-Projekte basierend auf dem SDK von XNP zu generieren, was bedeutet, dass der Entwickler nach dem Erstellen der Benutzeroberfläche in der IDE diese sofort auf seinem Gerät testen kann.
Die IDE bietet Objekte und Werkzeuge wie Schaltflächen, berührungsempfindliche Bereiche, Formen und vieles mehr, die auf einer Leinwand platziert werden. Ihre Eigenschaften werden dann so eingestellt, dass sie den Bedürfnissen und Erwartungen des Entwicklers entsprechen. All dies funktioniert auf intuitive und benutzerfreundliche Weise und beschleunigt den GUI-Entwicklungsprozess erheblich.
Allerdings müssen mehrere Konvertierungsschritte das GUI-Projekt mit dem bestehenden eIQ-Anwendungsprojekt zusammenführen, da das generierte GUI-Projekt in C und die qIQ-Beispiele in C/C++ sind. Daher muss der Inhalt einiger Header-Dateien umgeben sein von:
#ifdef __cplusplus
extern "C" {
#endif
/* C-Code */
#ifdef __cplusplus
}
#endif
Darüber hinaus wurden die meisten Quell- und Headerdateien in einen neuen Ordner im Middleware-Ordner des SDK verschoben und neue Include-Pfade hinzugefügt, um diese Änderungen widerzuspiegeln. Zuletzt wurden einige gerätespezifische Konfigurationsdateien verglichen und richtig zusammengeführt.
Die fertige Anwendung und ihre Funktionen
Die GUI der Anwendung wird auf einem berührungsempfindlichen LCD angezeigt. Es enthält einen Eingabebereich zum Schreiben von Ziffern und einen, der das Ergebnis der Klassifizierung anzeigt. Die Schaltfläche Inferenz ausführen führt die Inferenz aus, und die Schaltfläche Löschen löscht die Eingabe- und Ausgabefelder. Die Anwendung gibt das Ergebnis und die Zuverlässigkeit der Vorhersage auf der Standardausgabe aus.

Abbildung 4. Die GUI der Beispiel-App enthält ein Eingabefeld, ein Ausgabefeld und zwei Schaltflächen. Das Ergebnis und die Konfidenz werden auch auf der Standardausgabe ausgegeben.
TensorFlow Lite-Modellgenauigkeit
Wie oben erwähnt, kann das Modell eine hohe Genauigkeit der Trainings- und Testdaten erreichen, wenn es eine handgeschriebene Nummer im US-Stil klassifiziert. Dies ist jedoch bei dieser Anwendung nicht der Fall, hauptsächlich weil Ziffern, die mit einem Finger auf ein LCD geschrieben werden, niemals dieselben Ziffern sind, die mit einem Stift auf Papier geschrieben werden. Dies unterstreicht die Bedeutung des Trainings von Produktionsmodellen auf realen Produktionsdaten.
Für bessere Ergebnisse muss ein neuer Datensatz erhoben werden. Außerdem müssten die Mittel gleich sein. In diesem Fall müssen die Proben über eine Touchscreen-Eingabe gesammelt werden, um die Zahlen zu ziehen. Es gibt weitere Techniken, um die Genauigkeit der Vorhersagen zu erhöhen. Die Website der NXP-Community enthält eine Anleitung zur Verwendung der Transfer-Lerntechnik.
Implementierungsdetails
Embedded Wizard verwendet Slots als Trigger, um auf GUI-Interaktionen zu reagieren, beispielsweise wenn ein Benutzer seinen Finger über den Eingabebereich zieht. In diesem Fall zeichnet der Schlitz kontinuierlich eine pixelbreite Linie unter dem Finger. Die Farbe dieser Linie wird durch die Hauptfarbkonstante definiert.
Der Slot der Clear-Schaltfläche setzt die Farbe jedes Pixels in beiden Feldern auf die Hintergrundfarbe, und die Run-Inference-Schaltfläche speichert Verweise auf den Eingabebereich, die darunterliegende Bitmap sowie die Breite und Höhe des Bereichs und übergibt sie dann an ein natives C-Programm, das sie verarbeitet.
Da die Bitmaps aus dem Machine-Learning-Modell nur 28x28 Pixel groß sind und der Eingabebereich als 112x112 Quadrat angelegt wurde, um die Bedienung der Anwendung komfortabler zu gestalten, ist beim Verkleinern des Bildes eine zusätzliche Vorverarbeitung erforderlich. Andernfalls würde dieser Vorgang das Bild zu stark verzerren.
Zunächst wird ein Array von 8-Bit-Ganzzahlen mit den Abmessungen des Eingabebereichs erstellt und mit Nullen aufgefüllt. Dann werden das Bild und das Array durchlaufen, und jedes gezeichnete Pixel im Bild wird als 0xFF im Array gespeichert. Bei der Verarbeitung der Eingabe werden Pixel der Hauptfarbe als weiß und alles andere als schwarz betrachtet. Darüber hinaus wird jedes Pixel zu einem 3x3-Quadrat erweitert, um die Linie zu verdicken, wodurch das Verkleinern des Bildes viel sicherer wird. Bevor das Bild auf die erforderliche Auflösung von 28 x 28 skaliert wird, wird die Zeichnung beschnitten und zentriert, um den MNIST-Bildern zu ähneln:

Abbildung 5. Eine Visualisierung des Arrays, das die vorverarbeiteten Eingabedaten enthält.
Das Machine-Learning-Modell wird beim Start der Anwendung zugewiesen, geladen und vorbereitet. Bei jeder Inferenzanfrage wird der Eingabetensor des Modells mit der Vorverarbeitungseingabe geladen und an das Modell übergeben. Die Eingabe muss pixelweise in den Tensor kopiert und dabei die ganzzahligen Werte in Gleitkommawerte umgewandelt werden. Diese NXP-Anwendungsnotiz enthält einen detaillierten Speicherbedarf des Codes.
TensorFlow Lite:Eine praktikable Lösung
Die handschriftliche Ziffernerkennung mit maschinellem Lernen kann für eingebettete Systeme Probleme bereiten, und TensorFlow Lite bietet eine praktikable Lösung. Mit dieser Lösung könnten komplexere Anwendungsfälle, wie beispielsweise ein Pin-Eingabefeld an einem digitalen Schloss, realisiert werden. Wie in diesem Artikel besprochen, ist das Training von Produktionsmodellen auf realen Produktionsdaten von entscheidender Bedeutung. Die in diesem Artikel verwendeten Trainingsdaten bestanden aus Zahlen, die mit einem Stift auf ein Blatt Papier geschrieben wurden. Dies verringert wiederum die Gesamtgenauigkeit des Modells, wenn es verwendet wird, um Zahlen zu erkennen, die auf einem Touchscreen gezeichnet wurden. Außerdem müssen regionale Unterschiede berücksichtigt werden.
Die i.MX RT Crossover-MCU-Serie kann in eine Vielzahl von Embedded-Anwendungen implementiert werden, wie das Beispiel in diesem Artikel. NXP bietet umfangreiche Informationen zur i.MX RT Crossover-MCU-Serie, die dazu beitragen können, die Lücke zwischen Leistung und Benutzerfreundlichkeit zu schließen.
Weitere Informationen zu i.MX RT Crossover-MCUs finden Sie auf der i.MX RT-Produktseite.
Branchenartikel sind eine Inhaltsform, die es Branchenpartnern ermöglicht, nützliche Nachrichten, Nachrichten und Technologien mit All About Circuits-Lesern auf eine Weise zu teilen, für die redaktionelle Inhalte nicht gut geeignet sind. Alle Branchenartikel unterliegen strengen redaktionellen Richtlinien, um den Lesern nützliche Neuigkeiten, technisches Know-how oder Geschichten zu bieten. Die in Branchenartikeln zum Ausdruck gebrachten Standpunkte und Meinungen sind die des Partners und nicht unbedingt die von All About Circuits oder seinen Autoren.
Industrieroboter
- Wie man Abfall mit autonomen Robotern reduziert
- KI-Ziffernerkennung mit PiCamera
- Optimierung der Energieverwaltung mit der i.MX RT500 Crossover-MCU von NXP
- Informationen zur DSP-Aktivierung mit der i.MX RT500 Crossover-MCU von NXP
- So bauen Sie einen Variations-Autoencoder mit TensorFlow
- Verwendung von Epoxidharz mit Kunstwerken
- Bestellung von CNC-Maschinen? So geht's mit einem Cobot
- Erste Schritte mit der Yaskawa-Roboterprogrammierung
- Erste Schritte mit RoboDK für Raspberry Pi
- So rufen Sie einen Funktionsblock von einem OPC UA-Client mithilfe eines Informationsmodells auf