


Erweiterung der RISC-V-Architektur mit domänenspezifischen Beschleunigern
Als der RISC-V-Markt begann, bestand der anfängliche Ansturm darin, die Kosten für Designs zu senken, die sonst proprietäre CPU-Befehlssatzarchitekturen (ISAs) in tief eingebetteten Anwendungen verwendet hätten. Als diese Systeme auf Chips (SoCs) in der FinFET-Halbleiterprozesstechnologie hergestellt wurden, stiegen die Maskenkosten so hoch, dass viele Finite-State-Maschinen durch programmierbare Mikrosequenzer basierend auf dem RISC-V-Befehlssatz ersetzt wurden. Diese sorgten für die anfängliche Begeisterung und später für die Kommerzialisierung einfacher RISC-V-Kerne von 2014 bis 2018.
Als die RISC-V-Architektur ausgereifter wurde und SoC-Designer mit der ISA vertraut wurden, fand sie Einzug in Echtzeitanwendungen, die eine hohe Leistung erforderten:insbesondere als Frontend für hochspezialisierte Beschleunigungs-Engines für Anwendungen wie künstliche Intelligenz . Ein Hauptgrund für diese Annahme ist, dass RISC-V eine offene Architektur ist, in der Benutzer Anweisungen hinzufügen können, sodass die RISC-V-Prozessoren die Beschleuniger nicht als speicherabgebildete E/A-Geräte behandeln mussten, wie dies bei herkömmlichen Architekturen der Fall war . Stattdessen können sie einen Co-Prozessor mit niedriger Latenzzeit verwenden.
Die Verfügbarkeit von RISC-V-Prozessoren mit Vektorerweiterung ermöglichte es spezialisierten Beschleunigern, die Schichten zwischen den inneren Schleifen des Kernels für Anwendungen wie künstliche Intelligenz (KI), Augmented Reality/Virtual Reality (AR/VR) und Computer Vision zu verarbeiten. Dies ist jedoch nicht möglich ohne speziell entwickelte Erweiterungen wie einen benutzerdefinierten Ladebefehl, um Daten von einem externen Beschleuniger in interne Vektorregister zu übertragen.
Treiber dieser Verschiebung ist das von diesen Anwendungen geforderte Programmiermodell. Der Spezialbeschleuniger – der eine große Reihe von Multiplikatoren darstellt – ist hocheffizient, wenn auch ziemlich unflexibel, sowohl bei den von ihm durchgeführten Operationen als auch bei der Datenbewegung. Vergleichen Sie dies mit einem Allzweckprozessor wie dem x86, der dem Programmierer die ultimative Flexibilität beim Programmieren ohne Rücksicht auf die Einschränkungen der Compute-Engine ermöglicht – wenn das Design nur 100 W Leistung zum Brennen hat, was die meisten nicht tun.
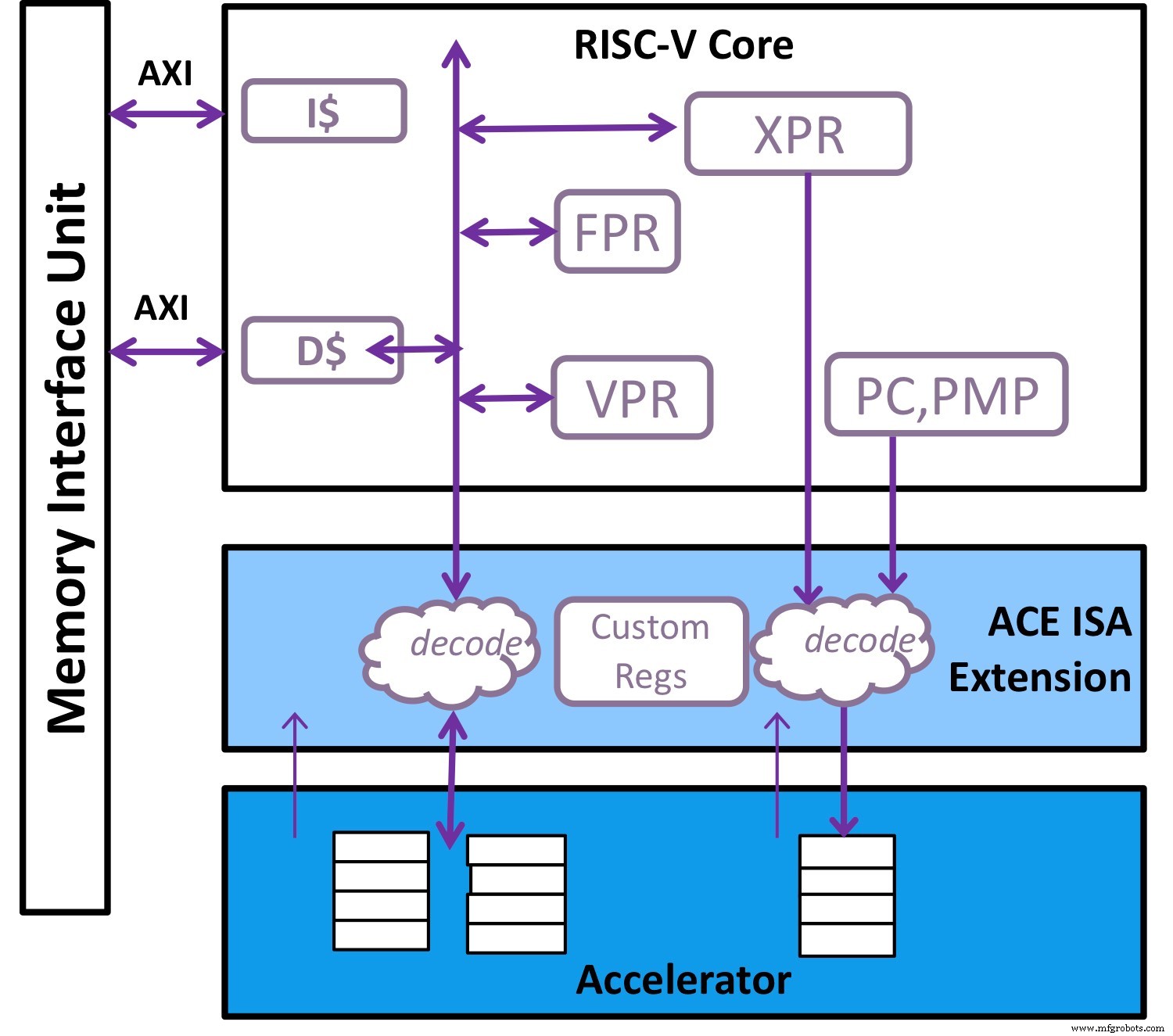
Die standardmäßige Vektorerweiterung in RISC-V, ergänzt durch spezielle benutzerdefinierte Anweisungen, ist eine ideale Ergänzung zum Beschleuniger (Bild:Andes Technology)
Die naheliegende Lösung besteht darin, die Flexibilität einer Allzweck-CPU mit einem Beschleuniger zu kombinieren, der eine ganz bestimmte Aufgabe bewältigen kann (siehe Abbildung oben). In RISC-V ist die reifende Standard-Vektorerweiterung, ergänzt durch spezielle benutzerdefinierte Anweisungen, ein idealer Begleiter für den Beschleuniger, und diese Einführung wurde in den letzten 18 Monaten deutlich, als domänenspezifische Beschleunigungslösungen (DSA) auf RISC-V-Plattformen konvergieren.
Um diese Vision zu ermöglichen, haben wir beobachtet, dass der Beschleuniger in der Lage sein muss, seinen eigenen Befehlssatz mit seinen eigenen Ressourcen einschließlich des Speichers auszuführen. Um die Ausführung des Beschleunigers zu rationalisieren, sollte RISC-V auch in der Lage sein, den Mikrocode so weit wie nötig zu glätten und alle erforderlichen Steuerinformationen in einem Befehl an den Beschleuniger zu packen. Darüber hinaus sollte dieser Beschleunigerbefehlssatz die Skalarregister und Vektorregister des RISC-V-Prozessors sowie seine eigenen Ressourcen wie Steuerregisterdateien und Speicher berücksichtigen.
Wenn der Beschleuniger Hilfe benötigt, um Daten auf besondere Weise neu anzuordnen oder zu manipulieren, übernimmt die Andes-Architektur dies mit einer Vektorverarbeitungseinheit (VPU), um die komplizierte Arbeit des Verschiebens, Sammelns, Komprimierens und Expandierens von Datenpermutationen zu bewältigen. Zwischen den Schichten gibt es einige Kernel, die Komplikationen beinhalten. Hier bietet die VPU die Flexibilität, diesen Bedarf zu decken. In diesen Sockeln führen sowohl der Beschleuniger als auch die VPU eine große Menge paralleler Berechnungen durch; Daher haben wir Hardware hinzugefügt, um die Bandbreite des Speichersubsystems erheblich zu erhöhen, um den Rechenbedarf zu decken, einschließlich, aber nicht beschränkt auf Prefetch- und nicht blockierende Transaktionen mit Rückgabe außerhalb der Reihenfolge.
Der erste RISC-V-Vektorprozessor von Andes Technology, der die neueste Version der V-Erweiterung 0.8 unterstützt, der NX27V, führt jede Berechnung in der Einheit von 8-Bit-, 16-Bit- und 32-Bit-Ganzzahlen in 16-Bit- und 32-Bit-Gleitkommazahlen durch. Es unterstützt auch das Bfloat16- und Int4-Format, um die Speicher- und Übertragungsbandbreite für Gewichtungswerte der Machine-Learning-Algorithmen zu reduzieren. Die RISC-V-Vektorspezifikation ist sehr flexibel, da sie es den Designern ermöglicht, die wichtigsten Designparameter wie Vektorlänge, die Anzahl der Bits in jedem Vektorregister und die SIMD-Breite, die Anzahl der Bits, die von der Vektor-Engine in jedem Zyklus verarbeitet werden, zu konfigurieren.
Der NX27V hat eine Vektorlänge von bis zu 512 Bit und ist durch Kombination von bis zu acht Vektorregistern auf 4096 Bit erweiterbar. Mit hinzugefügten multiplen Funktionseinheiten, die in parallelen Pipelines arbeiten, kann es den Rechendurchsatz aufrechterhalten, der in diversifizierten Anwendungen benötigt wird. In einer Implementierung, die mit 512-Bit-Vektorlänge und derselben SIMD-Breite konfiguriert ist, erreicht sie eine Geschwindigkeit von 1 GHz in 7 nm unter Worst-Case-Bedingungen in einem Bereich von 0,3 mm 2 . Zur Unterstützung der Softwareentwicklung hilft neben dem Compiler, dem Debugger, den Vektorbibliotheken und dem Zyklussimulator ein Visualisierungstool für die NX27V-Pipeline, Clarity, bei der Analyse und Optimierung der Leistung kritischer Schleifen. Diese Lösung wurde bereits in unserem Early-Access-Programm ausgeliefert.
In den letzten 15 Monaten haben wir eine große Nachfrage nach hoher Leistung mit der Hinzufügung einer leistungsstarken RISC-V-Vektorerweiterung, deren Anpassung an ein Speichersubsystem mit hoher Bandbreite und die Annäherung des Beschleunigers an die CPU festgestellt. Dies ist die Art von Computeranforderung, von der wir glauben, dass sie die Nachfrage nach RISC-V und Vektorverarbeitung ankurbeln wird.
>> Dieser Artikel wurde ursprünglich veröffentlicht am unsere Schwesterseite EE Times.
Eingebettet
- Einführung des IIC, jetzt mit OpenFog!
- 2. Version der Industrial Internet Reference Architecture mit Layered Databus
- Bekämpfung von Waldbränden mit dem IoT
- Mit Satelliten-IoT das Unerreichbare erreichen
- Ein Leitfaden zum Beschleunigen von Anwendungen mit genau richtigen benutzerdefinierten RISC-V-Anweisungen
- Drucken der Sicherung 1 mit der Sicherung 1
- Was mache ich mit den Daten?!
- Edge Computing:Die Architektur der Zukunft
- Absicherung des IoT-Bedrohungsvektors
- Unterwegs mit IoT