


Hardware-Inferenzchip für Automobilanwendungen
Das in Ungarn ansässige Unternehmen AImotive, ein Entwickler von software- und hardwarebasierten automatisierten Fahrtechnologien, hat mit der Auslieferung seines geistigen Eigentums (IP) der Hardware-Inferenz-Engine aiWare3 Neuronal Network (NN) an seine Hauptkunden begonnen.
Sein im letzten Jahr angekündigter aiWare3P IP-Core bietet einen Hardware-NN-Beschleuniger für hochauflösende Automotive-Vision-Anwendungen und als Komponente innerhalb von ISO26262 ASIL A, B und höher zertifizierten Subsystemen. Der Kern, der in einem System-on-Chip (SoC) oder als eigenständiger NN-Beschleuniger bereitgestellt werden kann, wird als vollständig synthetisierbares RTL bereitgestellt; Seine Low-Level-Mikroarchitektur ist darauf ausgelegt, weit weniger Host-CPU- oder Shared-Memory-Ressourcen zu verwenden als andere Hardware-NN-Beschleuniger.
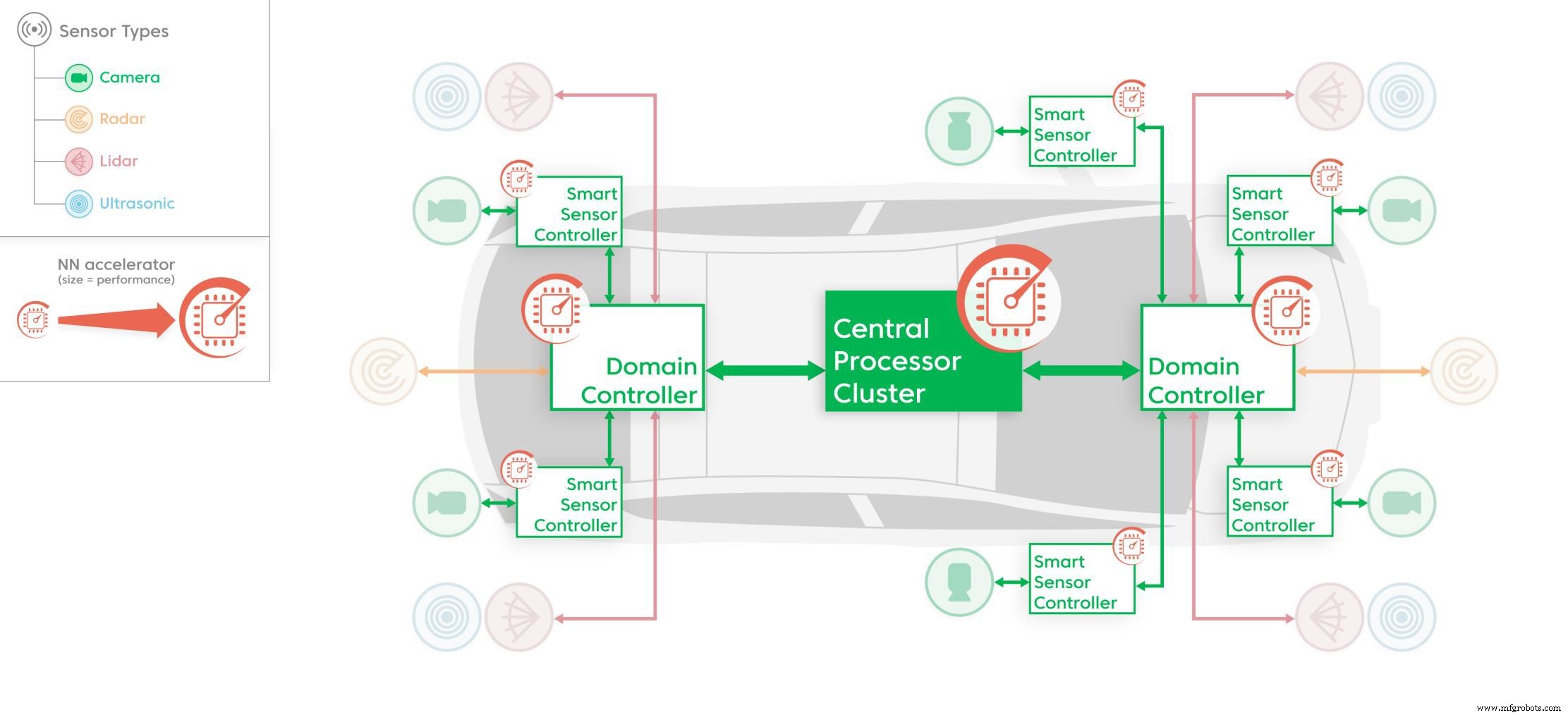 Dedizierte NN-Beschleuniger wie die aiWare3P IP, die in verschiedenen Teilen der Fahrzeugelektronikplattform verwendet werden (Quelle:AImotive)
Dedizierte NN-Beschleuniger wie die aiWare3P IP, die in verschiedenen Teilen der Fahrzeugelektronikplattform verwendet werden (Quelle:AImotive)
Im Gespräch mit EE Times Europe über den Unterschied zwischen dem AIMotive-Angebot und anderen Lösungen, sagte Tony-King Smith, Executive Advisor des Unternehmens, dass die meisten Chipspieler in akademischen Begriffen über Beschleuniger auf der Grundlage von GPUs und SoCs sprechen, die in einer Laborumgebung getestet wurden, was nicht wirklich gut übersetzt werden kann zur realen Welt. „Der entscheidende Unterschied besteht darin, dass man nicht den Beschleuniger, sondern die Prinzipien neuronaler Netze verstehen muss. In unserer Lösung gibt es keine DSPs, keine NOCs (Network on Chip). aiWare ist nur für automobile Inferenz ausgelegt, daher können wir eine geringe Latenz von der Eingabe bis zur Ausgabe bieten.“ Er fügte hinzu, dass Verbesserungen in der RTL-Ausgabe des neuen Kerns bedeuten, dass das Haupt-CPU-Subsystem frei wird und der Kern dann an jeden Beschleuniger-SoC angeschlossen werden kann.
Der aiWare3P IP-Core enthält Funktionen, die zu einer verbesserten Leistung, einem geringeren Stromverbrauch, einer größeren Host-CPU-Entlastung und einem einfacheren Layout für größere Chipdesigns führen. Jeder Kern bietet bis zu 16 TMAC/s (>32 TOPS) bei 2 GHz, mit Multi-Core- und Multi-Chip-Implementierungen, die bis zu 50+ TMAC/s (>100 INT8 TOPS) liefern können – nützlich für Multi-Kamera oder heterogen sensorreiche Anwendungen. Der Kern ist für den AEC-Q100-Betrieb bei erweiterter Temperatur ausgelegt und enthält Funktionen, die es Benutzern ermöglichen, die Zertifizierung nach ASIL-B und höher zu erreichen.
Die Skalierbarkeit der Leistung des IP-Cores auf mehr als 50 TMAC/s (>100 TOPS) pro Chip und die anhaltende Inferenz mit geringer Latenz sind das Ergebnis seiner Low-Level-Mikroarchitektur. Es verwendet ein patentiertes Grunddesign für ein hochdeterministisches Datenflussmanagement mit einer hochparallelen speicherzentrierten Architektur mit bis zu 100-mal größerer Speicherbandbreite auf dem Chip als andere Hardware-NN-Beschleuniger, wodurch eine nachhaltige Effizienz von bis zu 95 % für komplexe DNNs gewährleistet wird, die mit großen Eingänge wie mehrere HD-Kameras.
Das aiWare SDK unterstützt NNEF von Khronos sowie offene Standard-ONNX-Eingänge und kompiliert Binärdateien direkt, ohne dass eine Low-Level-Programmierung von DSPs oder MCUs erforderlich ist. Es umfasst automatisierte Tools für die FP32- bis INT8-Quantisierung mit geringem oder keinem Genauigkeitsverlust sowie ein wachsendes Portfolio hochentwickelter DNN-Leistungsanalysetools. Letztere wurden entwickelt, um Software- und KI-Ingenieuren bei der Migration und Umwandlung von in einem Labor geschulten NNs in effiziente Echtzeitlösungen zu unterstützen, die auf aiWare-basierten Hardwareplattformen für die Produktion von Automobilen ausgeführt werden.
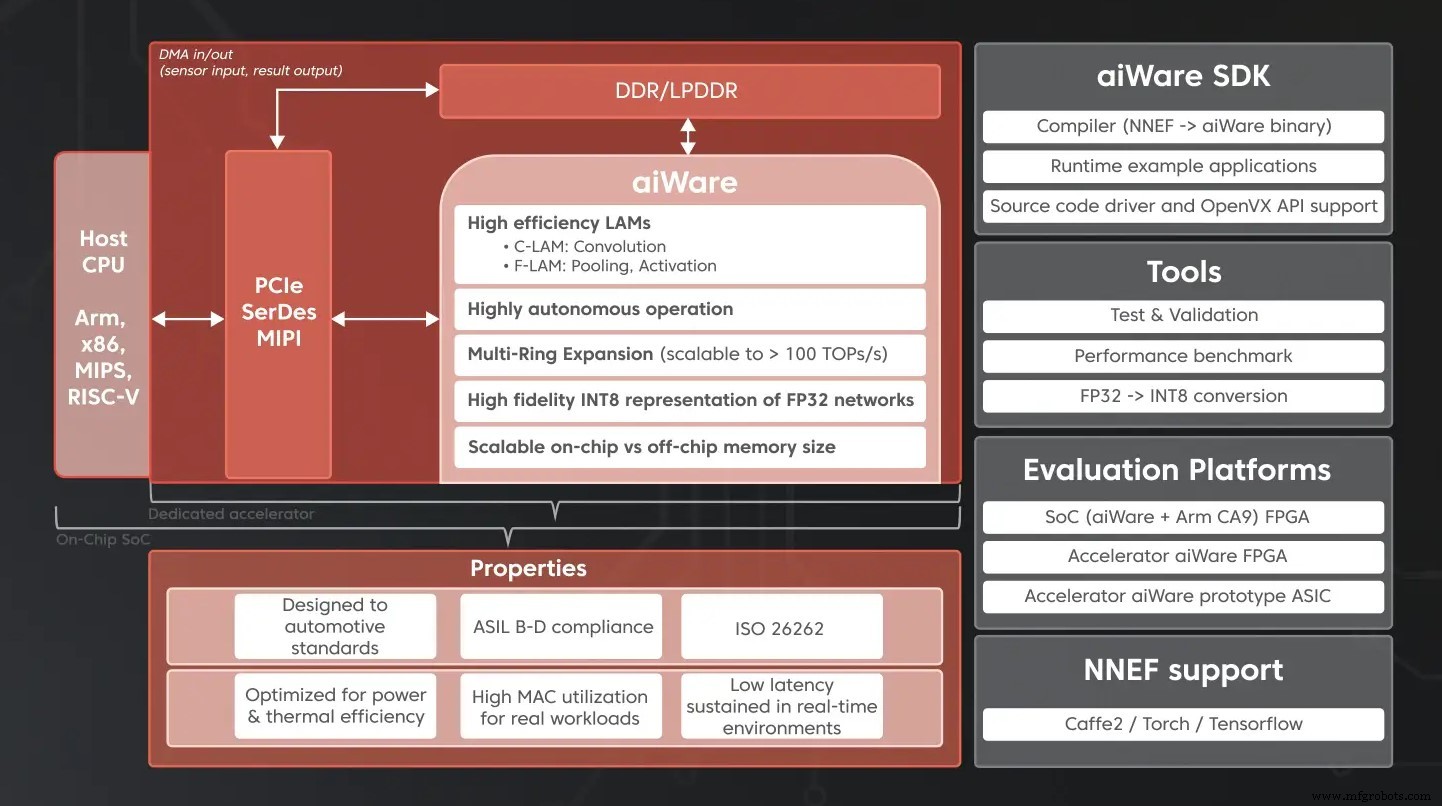 Die Bausteine eines Automotive-KI-Beschleunigers, einschließlich der aiWare-Hardware-IP (Quelle:AImotive)
Die Bausteine eines Automotive-KI-Beschleunigers, einschließlich der aiWare-Hardware-IP (Quelle:AImotive)
Marton Feher, Senior Vice President of Hardware Engineering bei AImotive, sagte:„Unsere produktionsreife aiWare3P-Version bündelt alles, was wir über die Beschleunigung neuronaler Netze für visionsbasierte Automotive-KI-Inferenzanwendungen wissen. Wir verfügen jetzt über eine der effizientesten und überzeugendsten NN-Beschleunigungslösungen der Automobilindustrie für die L2/L2+/L3-KI in der Massenproduktion.“
Die aiWare3P-Hardware-IP wird in einer Reihe von L2/L2+-Produktionslösungen eingesetzt sowie für Studien zu fortgeschritteneren heterogenen Sensoranwendungen eingesetzt. Zu den Kunden zählen Nextchip für ihren kommenden Apache5 Imaging Edge Processor und ON Semiconductor für ihr Gemeinschaftsprojekt mit AImotive, um fortschrittliche heterogene Sensorfusionsfunktionen zu demonstrieren.
AImotive sagte, dass es im ersten Quartal 2020 ein vollständiges Update seiner öffentlichen Benchmark-Ergebnisse basierend auf dem aiWare3P-IP-Core veröffentlichen wird. Dies ist Teil seines Engagements für offenes Benchmarking mit gut kontrollierten Benchmarks, die reale Anwendungen wie hochauflösende Eingänge für Kameras widerspiegeln, anstatt unrealistische öffentliche Benchmarks mit 224 × 224 Eingängen.
Kein Eingreifen der Host-CPU erforderlich
Zu den neuen Funktionen der aiWare3P-Hardware-IP gehört die Unterstützung eines viel größeren Portfolios von voroptimierten eingebetteten Aktivierungs- und Pooling-Funktionen, wodurch sichergestellt wird, dass 100 % der meisten NNs innerhalb des aiWare3P-Kerns ohne Eingriff der Host-CPU ausgeführt werden; Echtzeit-Datenkomprimierung, wodurch die Anforderungen an die externe Speicherbandbreite reduziert werden – insbesondere für größere Eingabegrößen und tiefere Netzwerke; und fortschrittliche Kreuzkopplung zwischen C-LAM-Faltungs-Engines und F-LAM-Funktions-Engines, um die Effizienz der überlappten und verschachtelten Ausführung zu erhöhen.
Die auf physischen Kacheln basierende Mikroarchitektur ermöglicht eine einfachere physische Implementierung großer aiWare-Kerne, indem schwierige Timing-Einschränkungen auf jedem Prozessknoten minimiert werden; und logisches Kachel-basiertes Datenmanagement ermöglicht eine effiziente Skalierbarkeit der Workloads bis zu maximal 16 TMAC/s pro Kern, ohne dass Caches, NOCs oder andere komplexe Multi-Core-Prozessor-basierte Ansätze erforderlich sind, die Engpässe schaffen, Determinismus reduzieren und mehr Strom verbrauchen und Siliziumbereich Die aiWare3P RTL wird ab Januar 2020 an alle Kunden ausgeliefert, und ein aktualisiertes SDK enthält einen verbesserten Compiler und neue Leistungsanalysetools für Offline-Schätzungen und feingranulare Echtzeit-Hardwareanalysen.
Eingebettet
- Infineon bringt eingebettete TLE985x-Leistungsserie für Automobilanwendungen auf den Markt
- KI-Chiparchitektur zielt auf die Grafikverarbeitung ab
- Hardwarebeschleuniger bedienen KI-Anwendungen
- Hall-Sensor zielt auf sicherheitskritische Automobilsysteme ab
- Debüts des bildgebenden Radarprozessors für die Automobilindustrie mit 30 fps
- EKF:robuste Box-Plattform für die Wandmontage für Bahn-, Automobil- und Industrieanwendungen
- Portwell:19-Zoll-System zielt auf Videowandanwendungen ab
- Kohlenstofffasern in Automobilanwendungen
- Zähe, hitzestabilisierte PPA-Compounds für anspruchsvolle Automobilanwendungen
- SGL Carbon-Technologien für Automobil- und Luft- und Raumfahrtanwendungen