


Cloud- und Edge-Computing für das IoT:eine kurze Geschichte
Edge Computing wird im IoT-Bereich immer beliebter. Im Jahr 2018 war es einer der wichtigsten Technologietrends, der die Grundlage für die nächste Generation digitaler Unternehmen bildete. Parallel dazu sehen wir angesichts der enormen Datenmengen und der Notwendigkeit, die Rechenressourcen zu optimieren, auch eine zunehmende Tendenz, Daten in die Cloud zu senden.
Während Edge und Cloud Computing oft als sich gegenseitig ausschließende Ansätze angesehen werden, erfordern größere IoT-Projekte häufig eine Kombination aus beidem. Um die heutige Vision des IoT und die sich ergänzenden Eigenschaften von Edge- und Cloud-Computing zu verstehen, möchten wir in die Vergangenheit reisen und einen Blick auf ihre Entwicklung in den letzten Jahrzehnten werfen.
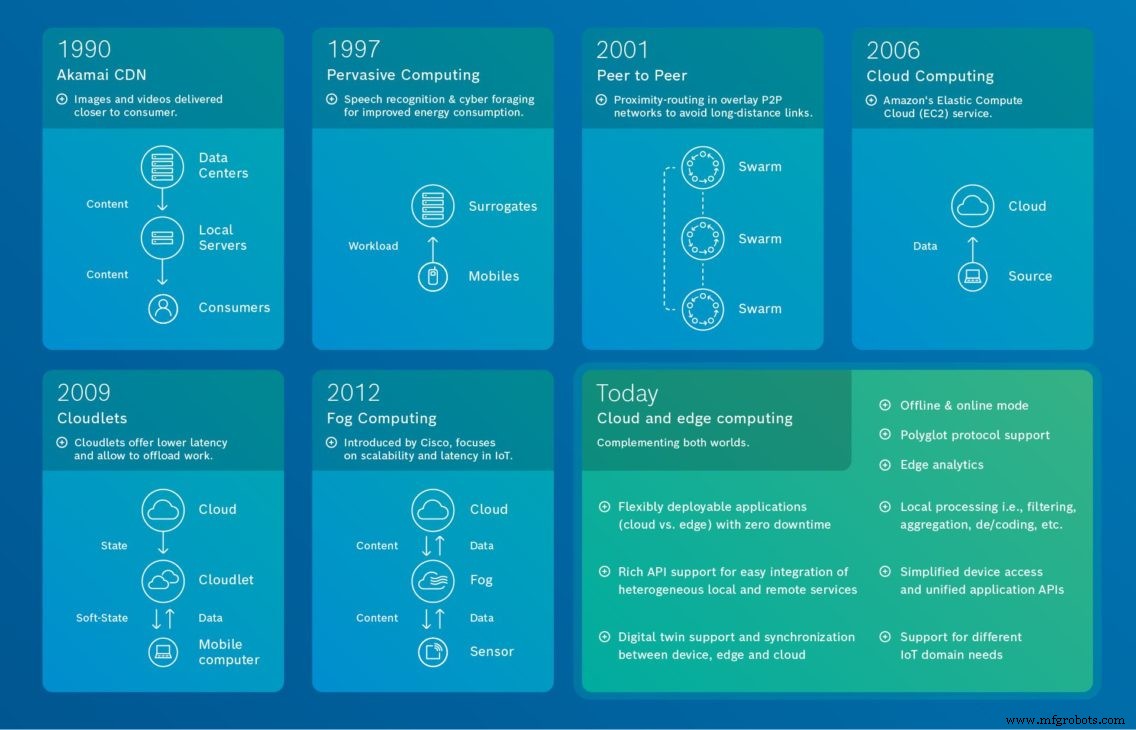 Quelle:Bosch.IO Ein Blick zurück in die Geschichte der Kommunikation und verteilter Systeme zeigt, dass Edge Computing als solches nicht neu ist. Unsere Grafik zeigt die Entwicklung des Edge Computing und endet mit unserer Vision, wie Edge und Cloud Computing kombiniert werden können, um den besten Wert zu erzielen.
Quelle:Bosch.IO Ein Blick zurück in die Geschichte der Kommunikation und verteilter Systeme zeigt, dass Edge Computing als solches nicht neu ist. Unsere Grafik zeigt die Entwicklung des Edge Computing und endet mit unserer Vision, wie Edge und Cloud Computing kombiniert werden können, um den besten Wert zu erzielen. Die Anfänge des dezentralen Computing
Der Ursprung des Edge Computing lässt sich bis in die 90er Jahre zurückverfolgen , als Akamai sein Content Delivery Network (CDN) einführte . Die Idee war damals, Knoten an Standorten einzuführen, die geografisch näher am Endnutzer liegen, um zwischengespeicherte Inhalte wie Bilder und Videos bereitzustellen.
Im 1997 , in ihrer Arbeit „Agile anwendungsorientierte Anpassung für Mobilität“, Nobel et al. demonstrierte, wie verschiedene Arten von Anwendungen (Webbrowser, Video- und Spracherkennung), die auf mobilen Geräten mit eingeschränkten Ressourcen ausgeführt werden, bestimmte Aufgaben auf leistungsstarke Server (Surrogate) auslagern können. Ziel war es, die Rechenressourcen zu entlasten. Und, wie in einer späteren Arbeit vorgeschlagen, die Akkulaufzeit von Mobilgeräten zu verbessern. Heute funktionieren beispielsweise Spracherkennungsdienste von Google, Apple und Amazon ähnlich. In 2001 , unter Bezugnahme auf Pervasive Computing , Satyanarayanan et al. verallgemeinerten diesen Ansatz in ihrem Paper „Pervasive Computing:Vision and Challenges“.
Im 2001 skalierbare und dezentralisierte verteilte Anwendungen verwendet, wie vorgeschlagen, verschiedene Peer-to-Peer (sogenannte verteilte Hash-Tabellen) überlagern Netzwerke. Diese selbstorganisierenden Overlay-Netzwerke ermöglichen effizientes und fehlertolerantes Routing, Objektlokalisierung und Lastausgleich. Darüber hinaus ist es mit diesen Systemen auch möglich, die Netzwerknähe zugrunde liegender physischer Verbindungen im Internet auszunutzen und so Langstreckenverbindungen zwischen Peers zu vermeiden. Dadurch wird nicht nur die gesamte Netzwerklast verringert, sondern auch die Latenz von Anwendungen verbessert.
Cloud-Computing
Cloud-Computing ist ein wichtiger Einflussfaktor in der Geschichte des Edge Computing und verdient daher besondere Erwähnung. Es erregte im 2006 besondere Aufmerksamkeit. Das Jahr, in dem Amazon zum ersten Mal für seine „Elastic Compute Cloud“ Werbung machte. Dies eröffnete eine Reihe neuer Möglichkeiten in Bezug auf Berechnung, Visualisierung und Speicherkapazität.
Dennoch war Cloud Computing als solches nicht in allen Anwendungsfällen die Lösung. Mit dem Aufkommen selbstfahrender Autos und des (industriellen) IoT zum Beispiel wurde zunehmend Wert auf die lokale Verarbeitung von Informationen gelegt, um sofortige Entscheidungen zu ermöglichen.
Cloudlets und Fog-Computing
Im 2009 , Satyanarayanan et al. den Begriff Cloudlet eingeführt in ihrem Paper „The case for VM-based cloudlets in Mobile Computing“. In dieser Arbeit liegt der Schwerpunkt auf der Latenz. Konkret schlägt das Papier eine zweistufige Architektur vor. Die erste Stufe wird als Cloud (hohe Latenz) und die zweite als Cloudlets (geringere Latenz) bezeichnet. Letztere sind dezentrale und weit verstreute Komponenten der Internet-Infrastruktur. Ihre Rechenzyklen und Speicherressourcen können von nahegelegenen mobilen Computern genutzt werden. Darüber hinaus speichert ein Cloudlet nur einen weichen Zustand, wie z. B. zwischengespeicherte Kopien von Daten.
Im 2012 , hat Cisco den Begriff Fog Computing eingeführt für verteilte Cloud-Infrastrukturen. Ziel war es, die Skalierbarkeit des IoT zu fördern, d. h. eine große Anzahl von IoT-Geräten und großen Datenmengen für Echtzeitanwendungen mit geringer Latenz zu handhaben.
Cloud- und Edge-Computing für groß angelegte IoT-Anwendungen
Heute , muss eine IoT-Lösung ein viel breiteres Anforderungsspektrum abdecken. Wir sehen, dass sich Unternehmen in den meisten Fällen für eine Kombination aus Cloud- und Edge-Computing für komplexe IoT-Lösungen entscheiden. Cloud Computing kommt in der Regel dann zum Einsatz, wenn Unternehmen Speicher- und Rechenleistung benötigen, um bestimmte Anwendungen und Prozesse auszuführen und Telemetriedaten von überall aus zu visualisieren. Edge Computing hingegen ist die richtige Wahl in Fällen mit geringer Latenz, lokal autonomen Aktionen, reduziertem Backend-Traffic und wenn es um vertrauliche Daten geht.
Sie möchten mehr darüber erfahren, wie Unternehmen bei der Implementierung von IoT-Lösungen von Cloud- und Edge-Computing profitieren? Lesen Sie unseren Leitfaden „Edge Computing für das IoT“.
Whitepaper herunterladenInternet der Dinge-Technologie
- Tipps und Tricks zu Cloud Computing
- Programmiermuster und Tools für Cloud Computing
- Cloud Computing für kleine und mittlere Unternehmen
- 10 Tipps und Tricks für eine erfolgreiche Cloud-Computing-Karriere
- Wie Hybrid Cloud die Grundlage für Edge Computing bietet
- Warum Edge Computing für das IoT?
- Nutzung von IoT-Daten vom Edge in die Cloud und zurück
- Wirtschaft des IoT – Lektionen für Dienstanbieter und Unternehmen
- Sind IoT und Cloud Computing die Zukunft der Daten?
- Edge-Computing-Vorteile für die KI-Kristallisation