


Wie Fuzz-Tests die Sicherheit von IoT-Geräten stärken
Fuzz-Tests sind ein wichtiger Ort für Ingenieure, um Schwachstellen in eingebetteten . zu finden Geräte und sollte für die Härtung von IoT-Geräteschnittstellen in Betracht gezogen werden.
Mit der Verbreitung von IoT-Geräten gehen zunehmend Angriffe auf eingebettete Sicherheit einher. In der Vergangenheit haben Ingenieure für eingebettete Systeme die Sicherheit der Geräteebene ignoriert, obwohl viele Bereiche eingebetteter Geräte anfällig für Fehler sind. Serielle Ports, Funkschnittstellen und sogar Programmier-/Debugging-Schnittstellen können von Hackern ausgenutzt werden. Fuzz-Tests stellen einen wichtigen Ort für Ingenieure dar, um Schwachstellen in eingebetteten Geräten zu finden, und sollten für die Härtung von IoT-Geräteschnittstellen in Betracht gezogen werden.
Was sind Fuzz-Tests?
Fuzz-Tests sind wie die mythischen Millionen Affen, die zufällig tippen, um Shakespeare zu schreiben. In der Praxis erfordern fiktionale Werke viele zufällige Kombinationen, um einen einfachen Satz zu erzeugen, aber bei eingebetteten Systemen müssen wir nur ein paar Buchstaben aus einem bekannt guten Satz ändern.
Zur Umsetzung von Fuzz-Angriffen stehen zahlreiche kommerzielle und Open-Source-Tools zur Verfügung. Diese Tools generieren zufällige Byte-Strings, auch Fuzz-Vektoren oder Angriffsvektoren genannt, und senden sie an die zu testende Schnittstelle, um das resultierende Verhalten zu verfolgen, das auf einen Fehler hinweisen könnte.
Fuzz-Testing ist ein Zahlenspiel, aber wir können nicht unendlich viele Eingabemöglichkeiten ausprobieren. Stattdessen konzentrieren wir uns darauf, die Testzeit zu optimieren, indem wir die Rate der Einreichung von Fuzz-Vektoren, die Effektivität der Fuzz-Vektoren und die Algorithmen zur Fehlererkennung maximieren.
Fuzz-Testkonzepte
Da viele Fuzz-Testtools zum Testen von PC-Anwendungen entwickelt wurden, ist es einfacher, sie anzupassen, wenn Sie Ihren eingebetteten Code als nativ kompilierte PC-Anwendung ausführen. Das Ausführen von eingebettetem Code auf einem PC bietet einen enormen Leistungsvorteil, hat jedoch zwei Nachteile. Erstens reagieren PC-Mikroprozessoren nicht wie eingebettete Mikrocontroller. Zweitens müssen wir jeden Code neu schreiben, der Hardware berührt. In der Praxis überwiegen jedoch die Vorteile der Ausführung auf einem PC die Nachteile. Die eigentliche Barriere ist die Schwierigkeit, Code zu portieren, um ihn nativ auf dem PC zu kompilieren.
Woher wissen wir, wann ein Fuzz-Vektor einen Fehler auslöst? Ein Absturz ist leicht zu erkennen, aber es ist schwieriger, Fuzz-Vektoren zu identifizieren, die einen Reset verursachen. Speicherüberlauf-Bugs oder streunende Pointer-Schreibvorgänge – die für Hacker wertvollsten Fehler – sind von außerhalb des Systems kaum zu erkennen, da sie normalerweise nicht zu einem Absturz oder einem Reset führen.
Viele moderne Compiler wie GCC und Clang verfügen über eine Funktion namens Speicherbereinigung. Dies markiert Speicherblöcke entweder als sauber oder schmutzig, je nachdem, ob sie verwendet werden, und kennzeichnet jeden Versuch, auf schmutzigen Speicher zuzugreifen. Die Speicherbereinigung verbraucht jedoch Flash-, RAM- und CPU-Zyklen, was die Ausführung auf eingebetteten Geräten erschwert. Stattdessen testen wir möglicherweise eine Teilmenge des Codes, erstellen eine Version des Geräts mit mehr Ressourcen oder verwenden einen PC.
Die Effektivität eines Tests kann anhand der Menge des ausgeübten Codes bewertet werden. Auch hier können Compiler die Speichernutzung verfolgen, indem sie Breadcrumb-Unterroutinenaufrufe verwenden. Die Code-Coverage-Bibliothek verwaltet eine Tabelle mit Nutzungswerten für jeden Codepfad und erhöht sie, wenn der Breadcrumb ausgeführt wird.
Code-Coverage-Nummern sind jedoch für eingebettete Fuzz-Tests schwierig zu interpretieren, da ein Großteil des Codes für die Fuzz-Vektoren nicht zugänglich ist; beispielsweise ein Gerätetreiber für ein Peripheriegerät, das unabhängig von der Schnittstelle läuft. Daher ist es schwierig, eine „vollständige Codeabdeckung“ für eingebettete Systeme zu definieren – vielleicht sind nur 20 % des eingebetteten Codes zugänglich. Die Codeabdeckung verbraucht auch große Mengen an Flash-, RAM- und CPU-Zyklen und würde für die Ausführung spezielle Hardware oder ein PC-Ziel erfordern.
Fehlermeldung
Wenn der Fuzz-Test einen Vektor findet, der ein unerwünschtes Verhalten verursacht, benötigen wir detaillierte Informationen. Wo ist der Fehler aufgetreten? Wie ist der Status der Aufrufliste? Was ist die spezielle Art von Fehler? All diese Informationen helfen bei der Triage und eventuellen Behebung des Fehlers.
Die Fehlersuche ist bei Fuzz-Tests von entscheidender Bedeutung. Neue Fuzz-Projekte finden oft viele Fehler, und wir brauchen eine automatische Methode, um deren Schweregrad zu bestimmen. Außerdem neigen Fuzz-Bugs dazu, Fehler zu blockieren, da sie oft weitere Fehler weiter unten im Codepfad maskieren. Wir brauchen eine schnelle Problemumgehung für Probleme, die während des Fuzz-Tests auftreten.
Embedded Clients sind nicht so bereit, ihre Informationen preiszugeben wie PCs. Normalerweise führt ein Absturz einfach dazu, dass das Gerät zurückgesetzt und neu gestartet wird. Dies ist zwar im Feld erwünscht, löscht jedoch den Zustand des Geräts, wodurch es schwierig wird, zu erkennen, ob ein Absturz aufgetreten ist, wo und warum er aufgetreten ist oder welcher Codepfad eingeschlagen wurde. Der Ingenieur muss einen konsistenten Reproduktionsvektor finden und dann einen Debugger verwenden, um das schlechte Verhalten zu verfolgen und den Fehler zu finden.
Bei Fuzz-Tests kann ein Test Tausende von Absturzvektoren für einige Fehler ergeben, die den falschen Eindruck eines fehlerhaften Systems erwecken. Es ist wichtig, schnell zu bestimmen, welche Vektoren mit demselben zugrunde liegenden Fehler verbunden sind. Bei eingebetteten Geräten ist der Ort des Absturzes selbst normalerweise für den Fehler eindeutig und es ist normalerweise nicht erforderlich, den vollständigen Call-Stack-Trace zu finden.
Kontinuierlicher Fuzz-Test
Aufgrund der stochastischen Natur von Fuzz-Tests erhöht eine längere Ausführung ihre Chancen, Probleme zu finden. Aber kein Projektplan konnte Verzögerungen durch einen langen Fuzz-Testzyklus am Ende der Entwicklung auffangen.
In der Praxis würden Fuzz-Tests nach dem Freigabeprozess in einem eigenen Zweig beginnen. Alle neu entdeckten Fehler würden im lokalen Zweig behoben, sodass das Testen fortgesetzt werden konnte, ohne dass die neuen Fehler die weitere Fehlersuche blockierten. Als Teil des Release-Zyklus würden Fehler, die bei Fuzz-Tests früherer Releases entdeckt wurden, für die Aufnahme in neue Releases evaluiert. Schließlich sollten Fuzz-Vektoren, die einen Fehler entdeckt haben, den normalen Qualitätssicherungsprozessen hinzugefügt werden, um die Fehlerbehebung zu überprüfen und sicherzustellen, dass diese Fehler nicht versehentlich wieder in den Code eingefügt werden.
Wir sollten Fuzz-Tests von Geräten in verschiedenen Szenarien durchführen; Beispielsweise reagiert ein Gerät anders auf Verbindungsanfragen, wenn es vernetzt ist. Es ist unpraktisch, Fuzz-Tests für jedes mögliche Szenario durchzuführen, aber wir können Fuzz-Tests für jeden Wert eines möglichen Zustands einschließen. Führen Sie beispielsweise Fuzz-Tests mit jedem unterschiedlichen Gerätetyp durch, während andere Variablen gleich bleiben. Führen Sie dann für einen Gerätetyp unterschiedliche Werte für eine andere Variable aus, z. B. den Netzwerkverbindungsstatus.
Fuzz-Testarchitekturen
Zwei bekannte Fuzz-Testarchitekturen sind das gerichtete Fuzzing, bei dem Fuzz-Vektoren vor dem Test von einem Techniker spezifiziert werden, und das abdeckungsgesteuerte Fuzz-Testen, bei dem das Fuzz-Tool mit einem anfänglichen Satz von Testvektoren beginnt und diese basierend auf der Durchdringung der Pakete automatisch mutiert den Code.
Außerdem läuft nicht der gesamte Code auf einem PC, und die Entwicklung eines PC-Simulators für eine eingebettete Anwendung kann je nach getestetem Inhalt unpraktisch sein.
Nachfolgend finden Sie eine Zusammenfassung von vier Fuzz-Testing-Architekturen:
- Direkte Schnittstellentests auf eingebetteter Hardware – Ausführen des normalen Produktionsabbilds auf dem eingebetteten Gerät mit Fuzz-Paketen, die über die Schnittstelle injiziert werden
- Paket-(Stack-)Injektionstests – Direktes Aufrufen eingehender Paketroutinen, ohne die Schnittstelle drahtlos trainieren zu müssen
- Gezieltes Fuzzing mit einem Simulator – mit PC-basierten Simulationstechniken zum Entwickeln und Testen von eingebettetem Code
- Abdeckungsgesteuertes Fuzzing mit einem Simulator (unten als Libfuzz dargestellt)
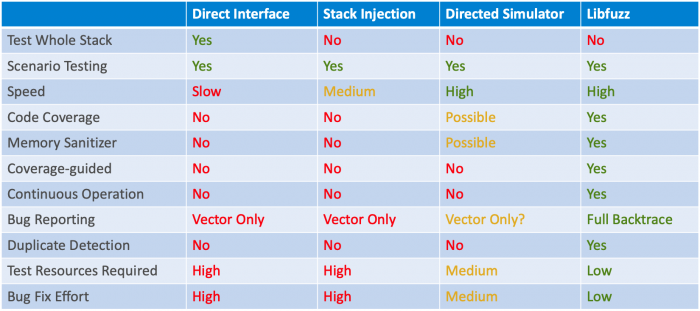
Mehrere Fuzz-Tester
Nachdem wir ein eingebettetes Gerät mit Debug-Schnittstellensperre und Secure Boot gesperrt haben, müssen wir einen Fuzz-Test der Schnittstellen des Geräts in Betracht ziehen. Viele der gleichen Tools und Konzepte, die zum Sichern von Webservern verwendet werden, können für die Verwendung mit eingebetteten Geräten angepasst werden.
Verwenden Sie das richtige Werkzeug für den Job. Abdeckungsgesteuertes Fuzzing ist für kontinuierliche Fuzz-Tests erforderlich, aber wenn Ihr Code nur auf eingebetteter Hardware ausgeführt wird, können gerichtete Fuzzer eine gute Wahl sein, um ein gewisses Maß an Fuzz-Testabdeckung bereitzustellen.
Schließlich sollten Sie in so vielen Szenarien wie möglich mehrere Fuzz-Tester einsetzen, da jeder das Gerät etwas anders testet, wodurch die Abdeckung und damit die Sicherheit Ihres eingebetteten Geräts maximiert wird.
>> Dieser Artikel wurde ursprünglich veröffentlicht am unsere Schwesterseite EDN.
Internet der Dinge-Technologie
- Wie 5G das industrielle IoT beschleunigen wird
- Wie das IoT Sicherheitsbedrohungen in Öl und Gas begegnet
- Der Weg zur industriellen IoT-Sicherheit
- Wie das IoT Arbeitsplätze verbindet
- Erleichterung der IoT-Bereitstellung in großem Maßstab
- IoT-Sicherheit – wer ist dafür verantwortlich?
- IoT-Sicherheit – Ein Hindernis für die Bereitstellung?
- Wie Optimierungen der IoT-Lieferkette Sicherheitslücken schließen können
- Internet der Warnungen:Wie intelligente Technologie die Sicherheit Ihres Unternehmens gefährden kann
- IoT-Sicherheit:Wie man die digitale Transformation vorantreibt und gleichzeitig Risiken minimiert