


Was ist Serverless Computing?
Das Infrastrukturmanagement fügt dem modernen Softwareentwicklungsworkflow eine zusätzliche Komplexitätsebene hinzu. Server am Laufen zu halten, sich um Sicherheitsupdates zu kümmern und Ressourcen zu skalieren, nimmt wertvolle Zeit von DevOps-Teams in Anspruch. Beim Serverless Computing werden alle Infrastrukturoperationen vom Dienstanbieter abgewickelt. Serverless ermöglicht es daher Entwicklungsteams, sich auf das Schreiben von Code zu konzentrieren, anstatt zu viel Zeit mit dem Infrastrukturmanagement zu verbringen.
In diesem Artikel wird erläutert, was Serverless Computing ist und wie es im Vergleich zu anderen Cloud-Bereitstellungsmodellen abschneidet. Wir werden auch die Vor- und Nachteile von Serverless untersuchen und über einige gängige Anwendungsfälle sprechen.
Was ist Serverless Computing?
Serverloses Computing ist eine Methode zum Bereitstellen und Ausführen von Code in der Cloud, ohne sich mit Serverbereitstellung und Infrastrukturverwaltung befassen zu müssen. Trotz seines Namens ist Serverless immer noch auf Cloud- oder physische Server für die Codeausführung angewiesen. Entwickler kümmern sich jedoch nicht um die zugrunde liegende Infrastruktur. Dies wird dem Serverless-Anbieter überlassen, der die erforderlichen Rechenressourcen dynamisch zuweist und im Namen des Benutzers verwaltet.
Für Entwickler bedeutet dies keinen Zeitaufwand für Serveradministration, Wartung, Ressourcenskalierung oder Kapazitätsplanung. Sie laden einfach ihren Code hoch und lassen den Anbieter die serverseitige Logik basierend auf verschiedenen Ereignissen oder Anforderungen ausführen. Im Gegensatz zu bekannten Cloud-Abrechnungsmodellen werden serverlose Dienste basierend darauf abgerechnet, wie oft der Code ausgeführt wird oder wenn ein bestimmtes Ereignis ausgelöst wird.
Wie funktioniert serverloses Computing?
In einer serverlosen Umgebung wird Code durch Ereignisse ausgelöst und als Funktion ausgeführt. Aus diesem Grund wird Serverless oft mit „Functions-as-a-Service“ oder FaaS in Verbindung gebracht, was ein ähnliches Konzept ist. FaaS ist ein ereignisgesteuertes Cloud-Modell, das die serverseitige Logik für die Codeausführung ohne Eingriff des Benutzers verarbeitet. Diese Ereignisse können alles sein, von einer einfachen HTTP-Anforderung, einem API-Aufruf bis hin zu einer Datenbankabfrage oder einem Datei-Upload.
Funktionen werden in zustandslosen Containern ausgeführt. Das bedeutet, dass Rechenressourcen zum Ausführen einer Funktion nur bereitgestellt werden, wenn sie aufgerufen wird. Es werden keine Daten im RAM gespeichert oder auf die Festplatte geschrieben. Sobald die Anfrage erfüllt wurde, wird der Zustand der App zurückgesetzt und es gibt keine Erinnerung an die Transaktion. Das Erstellen einer neuen Anforderung erfordert, dass die Ressourcen von Grund auf neu bereitgestellt werden, und der Code wird ohne Bezugnahme auf den vorherigen Aufruf ausgeführt.
Um diesen zustandslosen Zustand zu berücksichtigen, müssen Anwendungen als Funktionen konzipiert werden, die in zustandslosen Containern ausgeführt werden können. Dies wird normalerweise durch Mikrodienste erreicht. Große Monolith-Apps werden in kleinere Segmente zerlegt und über eine API miteinander verbunden. Monolith-Apps können weiterhin als einzelne Funktionen ausgeführt werden, dies ist jedoch keine gängige Praxis. Bedenkt man, dass bei jeder Anfrage ein neuer Compute-Container bereitgestellt wird, wirken sich große Funktionen negativ auf die Ausführungsgeschwindigkeit und -dauer aus.
FaaS-Funktionen laufen nicht endlos. Sie werden bei Aufruf nach einer bestimmten Zeit beendet. In den meisten Fällen kommt es nach etwa fünf Minuten zu einem Timeout der Funktionen. Das bedeutet, dass Apps, die Aufgaben mit langer Dauer ausführen, neu gestaltet werden müssen, um Beendigungslimits zu berücksichtigen.
Das Bereitstellen und Initialisieren von Containern für die Funktionsausführung nimmt ebenfalls Zeit in Anspruch. Dies wird normalerweise in Millisekunden gemessen. Die Initialisierung komplexer Funktionen kann jedoch einige Sekunden dauern, was zu einer größeren Latenz führt.
Es gibt zwei gängige Methoden zum Initialisieren einer Funktion – Warmstart und Kaltstart. Bei einem Warnstart werden Ressourcen aus einem vorherigen Ereignis wiederverwendet, während bei einem Kaltstart ein neuer Container bereitgestellt wird. Die Zeit, die zum Initialisieren und Ausführen einer Funktion benötigt wird, hängt von der Codemenge, der Programmiersprache, der Anzahl der vom Skript verwendeten Bibliotheken sowie von vielen anderen Faktoren ab. In Bezug auf die Latenz dauert ein Kaltstart länger, um eine Funktion zu starten.

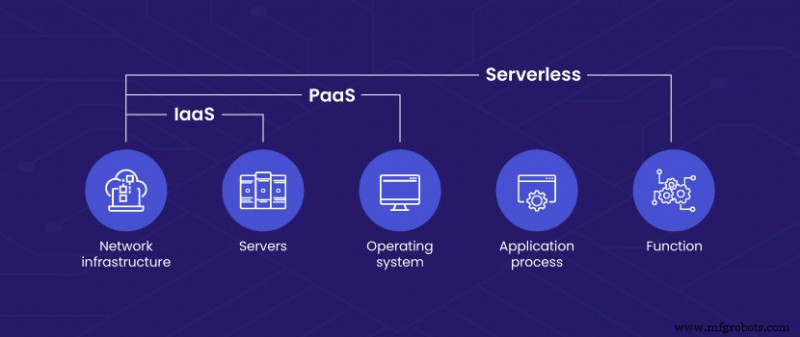
Wie Serverless Computing im Vergleich zu BaaS, PaaS und IaaS abschneidet?
Wie bei jedem Softwaretrend gibt es keine offizielle Definition, die beschreibt, was Serverless ist und was nicht. Aus diesem Grund wird Serverless Computing oft mit anderen Cloud-Diensten und Bereitstellungsmodellen verwechselt. Das Konzept des Serverless Computing dreht sich um zwei ähnliche Bereiche:
Backend-as-a-Service — BaaS ermöglicht es Entwicklern, sich auf das Schreiben von Frontend-Schnittstellen zu konzentrieren und gleichzeitig alle Backend-Operationen an einen Dienstanbieter auszulagern. Diese Aufgaben hinter den Kulissen umfassen normalerweise sofort einsatzbereite Benutzerauthentifizierung, Speicherung, Datenbankverwaltung und Hostingdienste. Außerdem müssen Entwickler keine Server verwalten, auf denen ihr Backend ausgeführt wird, was eine schnellere App-Bereitstellung ermöglicht.
Functions-as-a-Service — Dieses serverlose Cloud-Service-Modell macht das Infrastrukturmanagement überflüssig. Der Dienstanbieter hat die Aufgabe, Rechenressourcen nach Bedarf bereitzustellen, um den Code der Benutzer auszuführen. Dies geschieht immer dann, wenn ein Ereignis oder eine Anfrage ausgelöst wird. Serverlose Funktionen werden in zustandslosen Containern ausgeführt, was bedeutet, dass Rechenressourcen nur bereitgestellt werden, wenn die Funktion aufgerufen wird.
Der Hauptpunkt der Verwirrung liegt zwischen Backend-as-a-Service und Platform-as-a-Service (PaaS). Ersteres ist eine Technik des Serverless Computing, während letzteres ein Cloud-Bereitstellungsmodell ist. Obwohl sie einige grundlegende Merkmale gemeinsam haben, ist PaaS nicht auf die Anforderungen von Serverless ausgerichtet.
Platform-as-a-Service — Bei PaaS mieten Benutzer die für Entwicklungsarbeitslasten erforderlichen Hardware- und Softwarelösungen von einem Dienstanbieter gegen eine Abonnementgebühr. Es ermöglicht Entwicklern, mehr Zeit mit dem Programmieren zu verbringen, ohne sich um das Infrastrukturmanagement kümmern zu müssen. Andererseits bietet BaaS zusätzliche Funktionen wie eine sofort einsatzbereite Benutzerauthentifizierung, verwaltete Datenbanken, E-Mail-Benachrichtigungen und dergleichen. BaaS ermöglicht es Entwicklern auch, sich ausschließlich auf den Aufbau des Frontends zu konzentrieren und gleichzeitig verschiedene Backend-Dienste nach Bedarf zu integrieren.
Infrastruktur als Service — IaaS bezieht sich auf eine Self-Service-Cloud-Lösung, bei der der Anbieter die Infrastruktur im Namen des Benutzers hostet. Alle Serverbereitstellungs- und -verwaltungsvorgänge, einschließlich der Softwareinstallation, werden vom Benutzer durchgeführt. Einige IaaS-Anbieter bieten auch serverlose Lösungen an, jedoch als deutlich unterschiedliche Produkte.
Häufige Anwendungsfälle für serverloses Computing
Wie bereits erwähnt, ist Serverless nicht jedermanns Sache. Aber wenn Ihre Anforderungen mit einigen dieser Anwendungsfälle übereinstimmen, könnten Sie von Serverless profitieren.
APIs erstellen
Da keine Server verwaltet werden müssen, ist das Erstellen hochskalierbarer und reaktionsschneller APIs einer der beliebtesten Anwendungsfälle für serverlose Anwendungen. Die automatische Skalierungsfunktion von Serverless stellt sicher, dass APIs auch bei starkem Datenverkehr immer verfügbar sind. Darüber hinaus werden dem Benutzer keine ungenutzten Ressourcen in Rechnung gestellt, wenn keine Aufrufe an die API erfolgen.
Websites und Anwendungen
Die Bereitstellung von Websites und webbasierten Apps auf einer serverlosen Plattform erfordert keine vorherige Einrichtung der Infrastruktur. Dies verkürzt die Zeit, die zum Starten einer voll funktionsfähigen Web-App benötigt wird, erheblich. Auch die Auto-Scaling-Funktion spielt hier eine wichtige Rolle, da sich der Benutzer nicht um die Bereitstellung weiterer Server kümmern muss, um die steigende Nachfrage zu unterstützen. Dadurch ist es viel einfacher, eine Verfügbarkeit von 100 % aufrechtzuerhalten.
Mehrsprachige Anwendungen
Mit Serverless kann eine einzelne App in verschiedenen Sprachen geschrieben werden. Serverless ermöglicht es Entwicklern, eine monolithische App in kleinere Teile zu zerlegen und sie als Microservices auszuführen. Diese Microservices kommunizieren dann über eine API miteinander. Jedes Segment einer App kann mit einer anderen Programmiersprache geschrieben werden.
CI/CD-Pipelines
Automatisierung ist der Schlüssel zum Ausführen erfolgreicher Entwicklungs-, Test- und Integrationspipelines. Serverless ermöglicht es Entwicklern, Code automatisch zu testen und Fehler schneller zu beheben. Da Serverless ereignisbasiert ist, können Benutzer Ereignisse festlegen, um automatisierte Tests ohne manuellen Eingriff auszulösen.
Was sind die Vorteile von Serverless Computing?
Im Vergleich zum traditionellen serverorientierten Cloud Computing abstrahiert Serverless Computing den Infrastrukturbetrieb. Alles funktioniert sofort, was wiederum schnellere Code-Releases und automatisierte Skalierbarkeit zu einem niedrigeren Preis gewährleistet.
Dies sind die drei häufigsten Vorteile von Serverless:
Automatische Skalierung
Der serverlose Anbieter skaliert Infrastrukturressourcen nach Bedarf. Skalierungsvorgänge werden dynamisch und automatisch ohne Eingreifen von Entwicklern durchgeführt.
Schnellere Time-to-Market
Ohne komplexe Server-Cluster bereitstellen zu müssen, können sich Entwickler mehr darauf konzentrieren, eine höhere Release-Geschwindigkeit zu erreichen. Dies verkürzt die Zeit, die benötigt wird, um Code für die Produktion freizugeben oder inkrementelle Codeänderungen zu implementieren, was zu einer schnelleren Bereitstellung von Apps für Kunden führt.
Optimierte Kosten
Da alles nach Bedarf bereitgestellt wird, müssen Unternehmen nie für ungenutzten Speicherplatz, Rechenzeit oder Netzwerke bezahlen. Die Nutzung serverloser Dienste wird normalerweise in Millisekunden gemessen und entsprechend abgerechnet.
Was sind die Nachteile von Serverless Computing?
Wie jede Softwarelösung hat auch Serverless einige Nachteile. Aber abhängig von der App, die Sie erstellen, sind Sie möglicherweise nicht so besorgt über einige dieser Nachteile von Serverless.
Latenz
Beim Ausführen einer Funktion stellen Serverless-Provider bei jedem Aufruf automatisch die erforderlichen Ressourcen bereit. Abhängig von der Größe des Workloads werden Container normalerweise in Millisekunden bereitgestellt, können aber sogar mehrere Sekunden dauern. Die Latenz kann durch „Warnstarts“ reduziert werden, die Instanzen aus einer vorherigen Ausführung wiederverwenden.
Ausführungsdauer
Die Ausführungszeit einer serverlosen Funktion ist begrenzt und wird nach einer bestimmten Zeit abgebrochen. Dies ist normalerweise etwa fünf Minuten nach dem Aufruf, variiert jedoch je nach Anbieter. Ausführungsbeschränkungen sind ein großer Nachteil für Apps, die Prozesse mit langer Dauer initiieren. Dieses Problem kann gemildert werden, indem der Code in kleinere Teile segmentiert und als Microservices ausgeführt wird.
Anbieterbindung
Anbieter verwenden normalerweise proprietäre Technologien, um ihre serverlosen Dienste zu ermöglichen. Dies kann zu Problemen für Benutzer führen, die ihre Workloads auf eine andere Plattform migrieren möchten. Beim Wechsel zu einem anderen Anbieter sind Änderungen am Code und der Architektur der App unvermeidlich.
Sicherheit
Benutzer haben wenig Kontrolle über die Instanzkonfiguration, auf der ihr Code ausgeführt wird. Dies bleibt dem Benutzer verborgen und fällt in den Bereich des Dienstanbieters. Damit fällt auch der Sicherheitsbetrieb in die Hände des Anbieters. Der Benutzer ist hilflos, wenn ein Angriff erfolgt, und verlässt sich ausschließlich auf den Anbieter, um den Schaden zu mindern und das System wiederherzustellen. Anwendungen mit mehreren Einstiegspunkten in einer serverlosen Umgebung sind aufgrund einer größeren Angriffsfläche anfälliger für Schwachstellen.
Wie sieht die Zukunft für serverloses Computing aus?
Serverless Computing ist noch eine relativ neue Technologie. Seine Zukunft hängt von der Fähigkeit der Dienstanbieter ab, einige der oben aufgeführten Nachteile zu beheben – vor allem Kaltstarts. Anbieter müssen die Zeit verkürzen, die zum Ausführen einer Funktion benötigt wird, nachdem sie eine Weile im Leerlauf war. Durch die Lösung dieses Problems wird die Latenz verringert und eine nahtlose Benutzererfahrung gewährleistet.
Serverless stützt sich derzeit auf zustandslose Container für die Funktionsausführung. Die Zukunft von Serverless bewegt sich dahin, zustandsbehaftete Apps in die Lage zu versetzen, die Vorteile von Serverless zu nutzen. Dadurch können Entwickler zustandsbehaftete Apps erstellen, ohne sich Gedanken über die Datenverwaltung im Backend machen zu müssen.
In Bezug auf DevOps wird Serverless zur Ausweitung von NoOps führen. Dieser Trend wird dazu führen, dass Serverless-Anbieter den gesamten Infrastrukturbetrieb im Auftrag des Kunden übernehmen. In einer solchen Umgebung besteht für Unternehmen keine Notwendigkeit, interne Betriebsteams zu haben.
Kubernetes soll in den kommenden Jahren zur Grundlage von Serverless werden. Mit Unterstützung für Netzwerke, agiles Autoscaling und Multi-Cloud-Bereitstellungen verbessert die Kubernetes-Portabilität serverloses Computing in mehr als einer Hinsicht. Das Ausführen bestimmter App-Klassen ohne Server ist unpraktisch, da Dienstanbieter ihr Verhalten manchmal einschränken. Mit Kubernetes können Entwickler diese Einschränkungen überwinden und serverlose Plattformen basierend auf ihren spezifischen Anforderungen erstellen.
Schlussfolgerung
Auch wenn der Name auf das Fehlen von Servern hindeutet, ist Serverless Computing immer noch auf Cloud- oder physische Server angewiesen. Es handelt sich um ein Computermodell, das Infrastrukturoperationen eliminiert und es Entwicklern ermöglicht, sich auf das Schreiben und Bereitstellen von Apps zu konzentrieren. Das serverlose Modell dreht sich um zwei Schlüsselbereiche:Backend-as-a-Service und Functions-as-a-Service.
Ersteres bietet Benutzern eine sofort einsatzbereite Backend-Architektur, während letzteres das Ausführen von Apps in zustandslosen Containern ermöglicht. Diese Container werden automatisch basierend auf Ereignissen oder Auslösern bereitgestellt. Daher ist Serverless keine Patentlösung für alle aktuellen Entwicklungsprobleme. Es ist hauptsächlich auf nicht-monolithische Apps ausgerichtet, die eine auf Mikrodiensten basierende Architektur verwenden.
Cloud Computing
- Serverless Computing – Das neueste Angebot als Service
- Was sind die besten Cloud-Computing-Kurse?
- Was ist Cloud Computing und wie funktioniert die Cloud?
- Welche Beziehung besteht zwischen Big Data und Cloud Computing?
- Die größten Hindernisse für eine breitere serverlose Einführung
- Cloud Computing vs. On-Premise
- Was ist A2-Stahl?
- Was ist Edge Computing und warum ist es wichtig?
- Was ist Quantencomputing?
- Was ist der HS-Code für Hydraulikpumpen?