


Einsatz von FPGAs für Deep Learning
Ich habe vor kurzem am Xilinx Development Forum (XDF) 2018 im Silicon Valley teilgenommen. Während dieses Forums wurde mir ein Unternehmen namens Mipsology vorgestellt, ein Startup im Bereich der künstlichen Intelligenz (KI), das behauptet, die KI-bezogenen Probleme im Zusammenhang mit feldprogrammierbaren Gate-Arrays (FPGAs) gelöst zu haben. Mipsology wurde mit der großen Vision gegründet, die Berechnung jedes neuronalen Netzwerks (NN) mit der höchsten Leistung zu beschleunigen, die auf FPGAs ohne die mit ihrer Bereitstellung verbundenen Einschränkungen erreichbar ist.
Mipsology demonstrierte die Fähigkeit, mehr als 20.000 Bilder pro Sekunde auszuführen, läuft auf den neu angekündigten Alveo-Boards von Xilinx und verarbeitet eine Sammlung von NNs, darunter unter anderem ResNet50, InceptionV3, VGG19.
Einführung in neuronale Netze und Deep Learning
Ein neuronales Netz, das lose dem Netz von Neuronen im menschlichen Gehirn nachempfunden ist, bildet die Grundlage für Deep Learning (DL), ein komplexes mathematisches System, das Aufgaben selbstständig erlernen kann. Durch das Betrachten vieler Beispiele oder Assoziationen kann ein NN lernen Verbindungen und Beziehungen schneller als ein traditionelles Anerkennungsprogramm. Der Prozess der Konfiguration eines NN zum Ausführen einer bestimmten Aufgabe basierend auf Lernen Millionen von Proben des gleichen Typs werden als Training bezeichnet .
Ein NN kann sich beispielsweise viele Stimmproben anhören und DL verwenden, um zu lernen, den Klang bestimmter Wörter zu „erkennen“. Dieses NN könnte dann eine Liste neuer Stimmsamples durchsuchen und mithilfe einer Technik namens Inferenz richtig Samples identifizieren, die Wörter enthalten, die es gelernt hat .
Trotz seiner Komplexität basiert DL auf der Durchführung einfacher Operationen – meist Additionen und Multiplikationen – in Milliarden- oder Billionenhöhe. Der Rechenaufwand für die Durchführung solcher Operationen ist entmutigend. Genauer gesagt sind die Rechenanforderungen zum Ausführen von DL-Inferenzen größer als die für das DL-Training. Während das DL-Training nur einmal durchgeführt werden muss, muss ein NN, sobald es trainiert ist, für jede neue Probe, die es empfängt, immer wieder Inferenz durchführen.
Vier Möglichkeiten zur Beschleunigung der Deep-Learning-Inferenz
Im Laufe der Zeit griff die Ingenieursgemeinschaft auf vier verschiedene Computergeräte zurück, um NNs zu verarbeiten. In aufsteigender Reihenfolge der Verarbeitungsleistung und des Stromverbrauchs und in absteigender Reihenfolge der Flexibilität/Anpassung umfassen diese Geräte:zentrale Verarbeitungseinheiten (CPUs), Grafikverarbeitungseinheiten (GPUs), FPGAs und anwendungsspezifische integrierte Schaltkreise (ASICs). Die folgende Tabelle fasst die Hauptunterschiede zwischen den vier Computergeräten zusammen.
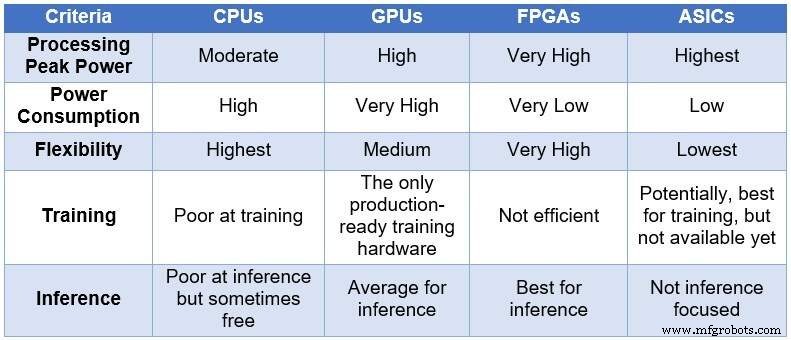
Vergleich von CPUs, GPUs, FPGAs und ASICs für DL-Computing (Quelle:Lauro Rizzatti)
CPUs basieren auf der Von-Neuman-Architektur. Obwohl sie flexibel sind (der Grund für ihre Existenz), sind CPUs von einer langen Latenz betroffen, da Speicherzugriffe mehrere Taktzyklen benötigen, um eine einfache Aufgabe auszuführen. Wenn sie auf Aufgaben angewendet werden, die von den niedrigsten Latenzen profitieren, wie NN-Berechnungen und insbesondere DL-Training und Inferenz, sind sie die schlechteste Wahl.
GPUs bieten einen hohen Rechendurchsatz auf Kosten einer verringerten Flexibilität. Darüber hinaus verbrauchen GPUs erheblichen Strom, der eine Kühlung erfordert, was sie für den Einsatz in Rechenzentren weniger ideal macht.
Obwohl benutzerdefinierte ASICs eine ideale Lösung zu sein scheinen, haben sie ihre eigenen Probleme. Die Entwicklung eines ASIC dauert Jahre. DL und NN entwickeln sich mit fortlaufenden Durchbrüchen schnell weiter, wodurch die Technologie des letzten Jahres irrelevant wird. Um mit einer CPU oder GPU konkurrieren zu können, müsste ein ASIC außerdem eine große Siliziumfläche mit der dünnsten Prozessknotentechnologie verwenden. Dies macht die Vorabinvestition teuer, ohne dass die langfristige Relevanz garantiert wird. Alles in allem sind ASICs für bestimmte Aufgaben effektiv.
FPGA-Geräte haben sich als die beste Wahl für Inferenz erwiesen. Sie sind schnell, flexibel, energieeffizient und bieten eine gute Lösung für die Datenverarbeitung in Rechenzentren, insbesondere in der schnelllebigen Welt von DL, am Rand des Netzwerks und unter dem Schreibtisch von KI-Wissenschaftlern.
Die größten heute verfügbaren FPGAs umfassen Millionen einfacher Boolescher Operatoren, Tausende von Speichern und DSPs sowie mehrere CPU-ARM-Kerne. Alle diese Ressourcen arbeiten parallel – jeder Taktimpuls löst bis zu Millionen gleichzeitiger Operationen aus – was zu Billionen von Operationen pro Sekunde führt. Die von DL erforderliche Verarbeitung lässt sich recht gut auf FPGA-Ressourcen abbilden.
FPGAs haben andere Vorteile gegenüber CPUs und GPUs, die für DL verwendet werden, einschließlich der folgenden:
Sie sind nicht auf bestimmte Datentypen beschränkt. Sie können nicht standardmäßige niedrige Präzision verarbeiten und sind besser geeignet, um einen höheren Durchsatz für DL zu liefern.
Sie verbrauchen weniger Strom als CPUs oder GPUs – normalerweise fünf- bis zehnmal weniger durchschnittliche Energie für dieselbe NN-Berechnung. Ihre wiederkehrenden Kosten in Rechenzentren sind niedriger.
Sie können umprogrammiert werden, um jeder Aufgabe gerecht zu werden, sind aber generisch genug, um verschiedene Aufgaben zu erfüllen. DL entwickelt sich schnell weiter, und derselbe FPGA wird neue Anforderungen erfüllen, ohne das Silizium der nächsten Generation (das bei ASICs typisch ist) zu benötigen, wodurch die Betriebskosten gesenkt werden.
Sie reichen von großen bis hin zu kleinen Geräten. Sie können in Rechenzentren oder in einem Internet of Things (IoT)-Knoten verwendet werden. Der einzige Unterschied besteht in der Anzahl der darin enthaltenen Blöcke.
Es ist nicht alles Gold was glänzt
Die hohe Rechenleistung, der geringe Stromverbrauch und die Flexibilität eines FPGAs haben ihren Preis – schwierig zu programmieren.
Internet der Dinge-Technologie
- CEVA:KI-Prozessor der zweiten Generation für tiefe neuronale Netzwerk-Workloads
- Plädoyer für neuromorphe Chips für KI-Computing
- ICP:FPGA-basierte Beschleunigerkarte für Deep-Learning-Inferenz
- Ausgelagerte KI und Deep Learning im Gesundheitswesen – Ist der Datenschutz gefährdet?
- Wie die Hightech-Industrie KI für exponentielles Geschäftswachstum nutzt
- Künstliche Intelligenz vs. maschinelles Lernen vs. Deep Learning | Der Unterschied
- Apple und IBM Watson-Team für mobiles maschinelles Lernen in Unternehmen
- Deep Learning und seine vielen Anwendungen
- Werkzeugstabilitätslösung für Tieflochbohren
- Wie Deep Learning Inspektionen für die Biowissenschaftsbranche automatisiert