


Data Lake vs. Big Data für industrielle Anwendungen
Data Lake und Big Data sind zwei moderne Begriffe, die oft falsch verstanden und falsch verwendet werden. Aufgrund der implizierten großen Datenmengen werden diese Begriffe manchmal synonym verwendet. Data Lake und Big Data sind jedoch unterschiedlich, auch wenn ihre aktuellen Definitionen möglicherweise noch nicht vollständig festgelegt sind.

Abbildung 1. Moderne Daten können aus vielen Quellen stammen und unterschiedlicher Art sein. Bild mit freundlicher Genehmigung von Analytics Vidhya
Betrachten wir zunächst einen kurzen historischen Kontext. Ende der 2000er Jahre, mit dem explosionsartigen Wachstum von Social-Media-Plattformen wie Facebook und Twitter, begannen viele Datenwissenschaftler, das Potenzial solcher Plattformen zur Generierung großer Mengen wertvoller personenbezogener Daten zu erkennen. Folglich wurden neue Softwareanwendungen entwickelt, um die Datenverarbeitung und -analyse zu erleichtern. Ein prominentes Beispiel ist Apache Hadoop, im Wesentlichen ein Toolkit von Open-Source-Anwendungen, das große Datenmengen an Informationen verarbeiten kann.
Im nächsten Jahrzehnt kam das Internet der Dinge (IoT) auf den Markt. Dies öffnete die Türen für Millionen weiterer Datenquellen, die Einblicke in die Vorlieben und Muster einer Person geben und gleichzeitig Informationen über das Produkt selbst senden könnten.
Gleichzeitig machte das maschinelle Lernen wichtige Fortschritte und fand mehr praktische Anwendungen in der Industrielandschaft. Dies führte zu einem erhöhten Bedarf, große Datenmengen in der Industrie zu verarbeiten, insbesondere in automatisierten Prozessen.
Alle Prognosen deuten darauf hin, dass die weltweit verfügbare Gesamtdatenmenge in den kommenden Jahren weiter beschleunigt wachsen wird. Als Referenz hat die Welt im Jahr 2016 den Meilenstein von 1 Zettabyte an jährlich generiertem Internetverkehr überschritten. Ein Zettabyte entspricht 1 Billion Gigabyte.
Der jährliche Internetverkehr wird 2021 voraussichtlich 3 Zettabyte übersteigen. Diese Prognosen, zusammen mit den erweiterten Möglichkeiten des Cloud Computing, deuten darauf hin, dass der Wert und die Nutzung von Big Data (und Data Lakes) vielleicht erst am Anfang stehen.
Was ist Big Data?
Allein aus der Perspektive des Volumens betrachtet, ist die Definition von Big Data ein bewegliches Ziel. Mit der ständig wachsenden Datenmenge und dem verfügbaren Speicherplatz wächst auch der Maßstab für die als große Menge an Informationen angesehenen Daten.
Ein Datenrepository mit einer Größe von 100 Terabyte oder mehr wird heute allgemein als Big Data bezeichnet. Große Datenspeicher wie die von Social-Media-Plattformen können im Bereich von mehreren Petabyte liegen.
Eine weitere Referenz zur Definition von Big Data ist, wenn die Informationsmenge von herkömmlichen Computertools wie SQL nicht verarbeitet werden kann. Heutzutage ist es beispielsweise nicht ungewöhnlich, dass Datenbanken eine Größe von 1 Terabyte jährlich erreichen. Da SQL-Anwendungen jedoch immer leistungsfähiger werden, kann diese Größe der Datenbank immer noch verwaltet werden; Daher werden sie normalerweise nicht als Big Data betrachtet.
Das 4V-Modell von Big Data
Bisher haben wir die Definition von Big Data aus der Perspektive des Volumens betrachtet. Drei weitere wichtige Faktoren sind zu berücksichtigen:Geschwindigkeit, Vielfalt und Richtigkeit. Diese bilden zusammen mit dem Volumen das 4V-Modell.
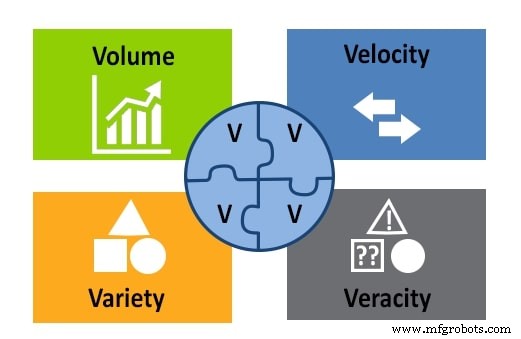
Abbildung 2. Das 4V-Modell von Big Data:Volumen, Geschwindigkeit, Vielfalt und Richtigkeit. Bild mit freundlicher Genehmigung von APSense
Vielfalt bezieht sich auf alle verschiedenen Arten von Daten, die in einem Big-Data-Repository gespeichert sind:Text, Bilder, Ton, Video usw. Es bezieht sich auch auf die Tatsache, dass Daten aus mehreren Quellen stammen können.
Geschwindigkeit ist ein wichtiger Aspekt bei Big Data, da die Informationen ständig einströmen. Geschwindigkeit betrifft die Geschwindigkeit, mit der Daten gesammelt, generiert und verteilt werden.
Veracity misst die Genauigkeit und Qualität der Daten, um zu bewerten, ob ein Data Scientist sie für Analysen und Schlussfolgerungen verwenden kann.
Nachdem wir Big Data jetzt verstanden haben, lassen Sie uns Data Lakes überprüfen, bevor wir uns damit befassen, wie man diese in einem Kontrollsystem verwendet.
Was ist ein Data Lake?
Data Lakes sind zentralisierte Speicher für große Mengen an Rohdaten, bei denen es sich um Informationen handelt, die in Zukunft wertvoll sein können oder nicht und deren Zweck noch nicht zu 100 % bekannt ist. Data Lakes können relationale und nicht-relationale Datenbanken zusammen mit anderen Arten von Dateien und Entitäten speichern.
Obwohl die Informationen in einem Data Lake nicht verarbeitet oder organisiert werden, sind sie so strukturiert, dass alle Eingaben und Ausgaben als gute Architektur betrachtet werden.
Data Lake vs. Big Data
Ein Data Lake ist eine Instanz einer Big-Data-Anwendung. Sie folgen den im 4V-Modell beschriebenen Kriterien mit einigen zusätzlichen Besonderheiten. In Bezug auf das Volumen liegen Data Lakes im Durchschnitt am unteren Ende dessen, was als Big Data bezeichnet wird.
Informationen in Data Lakes sind vielfältig, aber die Bedingung ist, dass es sich nur um unverarbeitete Rohdaten handelt. Ein- und Ausgabegeschwindigkeiten sind so relevant wie bei jedem modernen System und Datenqualitätsbewertungen werden in einem durchdachten Data Lake durchgeführt.
Industrielle Anwendungen für Daten
Fortschrittliche Automatisierung führt zu einem schnellen Anstieg der Menge an Informationen, die in der Fabrikhalle verarbeitet werden. Dank dessen treten Fertigungs- und andere industrielle Prozesse jetzt in den Bereich von Big Data ein, wobei mehrere Geschäftsaktivitäten jetzt Tools wie Data Lakes verwenden.
Ein prominentes Beispiel ist die vorausschauende Wartung. Die Fähigkeit, einen mechanischen oder elektrischen Fehler vorherzusagen, ist sehr wertvoll und kann zu erheblichen Einsparungen bei den Reparaturkosten führen. Data Lakes sind nützliche Tools, die Informationen aus Protokolldateien, mehreren Sensoren und Eingabegeräten zusammenstellen können, die verwendet werden können, um Trends zu verstehen und Probleme vorherzusagen.
Maschinelles Lernen ist ein Konzept, bei dem Roboter mit Informationen versorgt werden, die ihnen helfen können, sich an sich ändernde äußere Bedingungen anzupassen. Die Erfassung von Informationen ähnelt der Predictive Maintenance, mit dem zusätzlichen Schritt, dass Auswertungen und Änderungen am Prozess automatisch der Anlagensteuerung zugeführt werden. Machine-Learning-Daten können in einem strukturierten Data Lake gespeichert werden.
Abbildung 3. Machine Learning hat mehrere Strategien, die jeweils große Datenmengen erfordern. Bild mit freundlicher Genehmigung von WordStream
Zusammenfassend lässt sich sagen, dass ein Data Lake eine Instanz einer Big-Data-Anwendung ist. Diese beiden Möglichkeiten zum Anzeigen von Daten können zusammenarbeiten. Durch die Nutzung von Big Data und Data Lake kann ein Steuerungsingenieur Ausfälle vorhersagen, Wartungsroutinen erstellen, die digitale Transformation der Anlage vorantreiben und vieles mehr.
Wofür nutzen Sie Big Data und Data Lakes in Ihrem Job?
Internet der Dinge-Technologie
- Sensoren und Prozessoren konvergieren für industrielle Anwendungen
- Cervoz:Auswahl des richtigen Flash-Speichers für industrielle Anwendungen
- GE führt Cloud-Service für industrielle Daten und Analysen ein
- Aussichten für die Entwicklung des industriellen IoT
- Vier große Herausforderungen für das industrielle Internet der Dinge
- Sechs Grundlagen für erfolgreiche sensorgestützte Anwendungen
- So verstehen Sie Big Data:RTUs und Prozesssteuerungsanwendungen
- Die Voraussetzungen für den Erfolg der Industrial Data Science schaffen
- Für echte Einblicke in das industrielle Internet:Erfassen Sie nicht nur Daten, sondern verwenden Sie sie
- Wird Big Data ein Allheilmittel für marode Gesundheitsbudgets sein?