


Stellen Sie sich den ETL-Herausforderungen von IoT-Daten und maximieren Sie den ROI
Unternehmen können IoT-Daten optimieren und ihren Geschäftswert schnell und kostengünstig erzielen, indem sie Fachwissen in ETL-Technologien (Extract, Transfer, Load) entwickeln.
Das Potenzial des IoT war noch nie größer. Angesichts der erwarteten Verdopplung der Investitionen in IoT-fähige Geräte bis 2021 und der steigenden Möglichkeiten in den Daten- und Analysesegmenten besteht die Hauptaufgabe darin, die Herausforderungen zu meistern und die damit verbundenen Kosten zu zähmen IoT-Datenprojekte.
Unternehmen können IoT-Daten optimieren und ihren Geschäftswert schnell und kostengünstig erzielen, indem sie Fachwissen in ETL-Technologien (Extract, Transfer, Load) wie Stream Processing und Datalakes entwickeln.
Siehe auch: 4 Prinzipien zur Ermöglichung eines makellosen Data Lake
In vielen Organisationen kann dies jedoch zu IT-Engpässen, langen Projektverzögerungen und einem Aufschub von Data Science führen. Ergebnis:IoT-Projekte – in denen prädiktive Analysedaten eine entscheidende Rolle bei der Verbesserung der betrieblichen Effizienz und der Förderung von Innovationen spielen sollen – immer noch haben die Proof-of-Concept-Schwelle noch nicht überschritten und können definitiv keinen ROI nachweisen.
Verstehen Sie die ETL-Herausforderungen, denen IoT gegenübersteht
Das folgende Diagramm hilft Ihnen, das Problem besser zu verstehen:
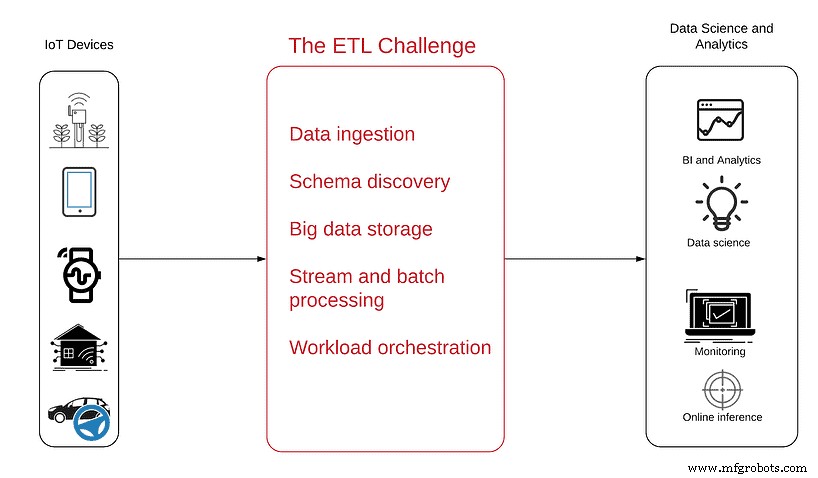
Die Datenquelle ist auf der linken Seite – unzählige mit Sensoren gefüllte Geräte, von einfachen Antennen bis hin zu komplizierten autonomen Fahrzeugen, die IoT-Daten generieren und sie als ununterbrochenen Strom halbstrukturierter Daten über das Internet senden.
Auf der rechten Seite sind die Ziele aufgeführt, die durch die Nutzung dieser Daten erreicht werden sollen, mit den resultierenden Analyseprodukten am Ende des Projekts, einschließlich:
- Business-Intelligence um einen Einblick in Produktnutzungstrends und -muster zu erhalten
- Betriebsüberwachung um Ausfälle und inaktive Geräte in Echtzeit zu sehen
- Anomalieerkennung um proaktive Benachrichtigungen über Spitzen oder abrupte Einbrüche in den Daten zu erhalten
- Eingebettete Analysen um es Kunden zu ermöglichen, ihre eigenen Nutzungsdaten zu sehen und zu verstehen
- Datenwissenschaft um die Vorteile fortschrittlicher Analysen und maschinellen Lernens in den Bereichen vorausschauende Wartung, Routenoptimierung oder KI-Entwicklung zu nutzen
Um diese Ziele zu erreichen, müssen Sie zunächst Daten aus ihrem Raw-Streaming-Modus in analysebereite Tabellen umwandeln, die mit SQL und anderen Analysetools abgefragt werden können.
Der ETL-Prozess ist oft das am schwierigsten zu verstehende Segment jedes Analyseprojekts, da IoT-Daten eine einzigartige Reihe von Eigenschaften enthalten, die nicht immer mit den üblichen relationalen Datenbanken, ETL- und BI-Tools synchron sind. Zum Beispiel:
- IoT-Daten sind Streaming-Daten kontinuierlich in kleinen Dateien generiert, die sich zu massiven, weitläufigen Datensätzen ansammeln. Diese unterscheiden sich stark von herkömmlichen tabellarischen Daten und erfordern eine komplexere ETL, um Verknüpfungen, Aggregationen und Datenanreicherung durchzuführen.
- IoT-Daten müssen jetzt gespeichert und später analysiert werden. Im Gegensatz zu typischen Datensätzen bedeutet die schiere Menge an Daten, die von IoT-Geräten erstellt werden, dass sie einen Ort haben müssen, an dem sie gespeichert werden können, bevor sie analysiert werden können – einen Cloud- oder On-Premise-Data Lake.
- IoT-Daten präsentieren aufgrund mehrerer Geräte ungeordnete Ereignisse die sich in und aus Bereichen mit Internetkonnektivität bewegen können. Das bedeutet, dass Protokolle Server möglicherweise zu unterschiedlichen Zeiten und nicht immer in der „richtigen“ Reihenfolge erreichen.
- IoT-Daten erfordern häufig einen Zugriff mit geringer Latenz. Im Betrieb müssen Sie möglicherweise Anomalien oder bestimmte Geräte in Echtzeit oder nahezu in Echtzeit identifizieren, sodass Sie sich die durch die Stapelverarbeitung verursachten Latenzen nicht leisten können.
Sollten Sie Open-Source-Frameworks verwenden, um einen Data Lake zu erstellen?
Um eine Unternehmensdatenplattform für die Datenanalyse aufzubauen, verwenden viele Organisationen diesen gemeinsamen Ansatz:Erstellen Sie einen Data Lake mit Open-Source-Stream-Processing-Frameworks als Bausteine plus Zeitreihendatenbanken wie Apache Spark/Hadoop, Apache Flink, InfluxDB und andere.
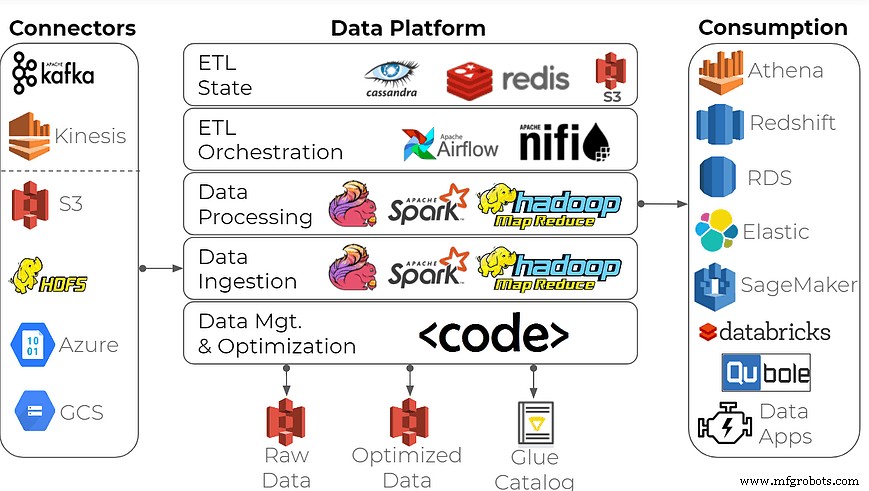
Kann dieses Toolset die Arbeit erledigen? Sicher, aber es richtig zu machen, kann für alle außer den datenerfahrensten Unternehmen überwältigend sein. Der Aufbau einer solchen Datenplattform erfordert die spezialisierten Fähigkeiten von Bigdata-Ingenieuren und eine starke Aufmerksamkeit für die Dateninfrastruktur – normalerweise keine starke Rolle in der Fertigung und Unterhaltungselektronik, Branchen, die eng mit IoT-Daten zusammenarbeiten. Erwarten Sie verspätete Lieferungen, hohe Kosten und eine Menge verschwendeter Entwicklungsstunden.
Wenn Ihr Unternehmen eine hohe Leistung sowie eine vollständige Palette von Funktionalitäten und Anwendungsfällen wünscht – Betriebsberichte, Ad-hoc-Analysen und Datenaufbereitung für maschinelles Lernen – dann entscheiden Sie sich für eine geeignete Lösung. Ein Beispiel wäre die Verwendung einer Data Lake ETL-Plattform, die speziell entwickelt wurde, um Streams in analysebereite Datensätze umzuwandeln.
Die Lösung ist nicht so starr und komplex wie Spark/Hadoop-Datenplattformen. Es ist mit einer Self-Service-Benutzeroberfläche und SQL aufgebaut, nicht mit der intensiven Programmierung in Java/Scala. Für Analysten, Datenwissenschaftler, Produktmanager und Datenanbieter in DevOps und Data Engineering kann es ein wirklich benutzerfreundliches Tool sein, das:
- Bietet Self-Service für Datenkonsumenten, ohne sich auf IT und Data Engineering verlassen zu müssen
- Optimiert ETL-Abläufe und Big-Data-Speicherung, um die Infrastrukturkosten zu senken
- Ermöglicht Organisationen dank vollständig verwaltetem Service, sich auf Funktionen anstatt auf die Infrastruktur zu konzentrieren
- Beseitigt die Notwendigkeit, mehrere Systeme für Echtzeitdaten, Ad-hoc-Analysen und Berichte zu unterhalten
- Stellt sicher, dass die Daten das AWS-Konto des Kunden nie verlassen, um absolute Sicherheit zu gewährleisten
Sie können von IoT-Daten profitieren – es braucht nur die richtigen Tools, um sie nutzbar zu machen.
Internet der Dinge-Technologie
- Smart Data:Die nächste Grenze im IoT
- Einfach, interoperabel und sicher – Verwirklichung der IoT-Vision
- Nutzung von IoT-Daten vom Edge in die Cloud und zurück
- Welche Branchen werden die Gewinner der IoT-Revolution sein und warum?
- Die Notwendigkeit, Daten zu integrieren, ist dringend und nicht trivial, sagt der Vater des IoT
- Die 3 wichtigsten Herausforderungen bei der Aufbereitung von IoT-Daten
- Sind IoT und Cloud Computing die Zukunft der Daten?
- AIoT:Die leistungsstarke Konvergenz von KI und IoT
- Demokratisierung des IoT
- Maximierung des Wertes von IoT-Daten