


Hybridarchitektur beschleunigt KI, Vision-Workloads
Ein neuartiger hybrider Datenfluss und die Von-Neumann-Architektur können Workloads beschleunigen, einschließlich neuronale Netze, maschinelles Lernen, Computer Vision, DSP und grundlegende Unterprogramme der linearen Algebra.
Quadric, ein Startup aus dem Silicon Valley, hat einen Beschleuniger entwickelt, der sowohl KI- als auch Standard-Computer-Vision-Algorithmus-Workloads für Edge-Geräte wie Roboter, Fabrikautomatisierung und medizinische Bildgebung beschleunigen soll. Die Hardwarearchitektur des Unternehmens besteht aus einem neuartigen hybriden Datenfluss- und Von-Neumann-Design, das Workloads wie neuronale Netze, maschinelles Lernen, Computer Vision, DSP und grundlegende Unterprogramme der linearen Algebra bewältigen kann.
„Uns war von Anfang an sehr bewusst, dass KI nicht die einzige Anwendung ist, die für das On-Device-Computing auf Edge-Geräten benötigt wird“, sagte Veerbhan Kheterpal, CEO von Quadric, gegenüber EE Times . „Die Entwickler dieser Produkte benötigen für das Gesamtsystem neben KI auch klassische High-Performance-Computing-Algorithmen. Das sind wirklich die vollständigen Systemanforderungen.“
Kheterpal betonte, dass die Architektur keine Sammlung von Beschleunigern für einzelne Workloads sei. Vielmehr handelt es sich um eine einheitliche Architektur mit einem datenparallelen Befehlssatz, der darauf ausgelegt ist, verschiedene Workloads zu beschleunigen, einschließlich KI-Inferenz.
„Bei der Entwicklung der KI in letzter Zeit gibt es einige interessante Trends rund um das Ersetzen ganzer Schichten durch eine schnelle Fourier-Transformation (FFT),“ sagte Daniel Firu, Chief Product Officer von Quadric. Quadric positioniert sich, um diese Art von Workloads zu beschleunigen, und zitiert ein kürzlich erschienenes Papier von Google, in dem Forscher ein Transformatornetzwerk beschleunigten, indem sie einige Schichten durch eine FFT ersetzten. Google ersetzte die Selbstaufmerksamkeits-Unterschicht eines Transformatorencoders durch eine FFT, um ein Netzwerk zu generieren, das beim BERT-Benchmark eine Genauigkeit von 92 Prozent erreichte; Das Training war auf GPUs bis zu siebenmal schneller oder auf Google TPUs doppelt so schnell.

Das Entwickler-Kit von Quadric, eine M.2-Karte mit dem Q16-Prozessor und 4 GB externem Speicher (Quelle:Quadric)
Weinbergroboter
Die drei Mitbegründer von Quadric, Veerbhan Kheterpal, Daniel Firu und Nigel Drego, gründeten zuvor 21, ein Bitcoin-Mining-Unternehmen, das an Coinbase verkauft wurde. Quadric, Burlingame, Kalifornien, begann nicht mit der Entwicklung von Chips. Stattdessen baute es ursprünglich landwirtschaftliche Roboter, die in den Weinbergen des Napa Valley auf und ab gehen konnten, um die Reben zu beobachten und Warnungen zu senden, wenn es Bewässerungslecks oder Schädlinge sah.

Veerbhan Kheterpal (Quelle:Quadric)
„Als wir es gebaut haben, haben wir festgestellt, dass es kein praktikables Produkt sein würde, das aus der Drohnen-Lieferkette für 5 bis 10.000 US-Dollar gebaut wurde“, sagte Kheterpal. „Es müsste aus der Lieferkette von Traktoren gebaut werden, kostet 50.000 US-Dollar und muss große PCs mit GPUs und Tonnen von Kameras tragen. Zu diesem Zeitpunkt machten wir uns auf den Weg, um unter die Haube all dieser Robotik-Software zu schauen und entdeckten, was diesen Energiebedarf grundlegend verursacht hat, um mit Plattformen wie Nvidia und Intel zu steigen.“
Das Unternehmen wandte sich dem Bau eines Beschleunigerchips zu – „den Chip, den wir uns gewünscht hätten“, so Firu.
2017 wurde eine Seed-Finanzierungsrunde gestartet, gefolgt von einer Serie-A-Runde, die 13 Millionen US-Dollar von potenziellen Kunden einbrachte, darunter Quadrics Hauptinvestor, der japanische Automobil-Tier-One Denso. Die Gesamtfinanzierung von Quadric beträgt 18 Millionen $.
Turing abgeschlossen
Quadric verwendet eine befehlsgesteuerte Architektur, die Elemente aus Datenflussarchitekturen aufnimmt und mit Elementen einer Von-Neumann-Maschine kombiniert. Ziel ist es, heterogene Systeme in Edge-Geräten durch weniger komplexe zu ersetzen. Als Turing-Komplettmaschinen bieten Quadric Vortex-Kerne eine Kombination aus Beschleunigung und Flexibilität, so das Unternehmen. Die Architektur ist in Bezug auf Arrays von Kernen skalierbar und bis hin zu fortschrittlichen (7- oder 5-nm-) Prozessknoten portierbar. Dies eignet sich für Edge-Geräteanwendungen mit Leistungsbudgets zwischen ungefähr Hunderten von Milliwatt bis 20 W.
Der erste Chip des Unternehmens, der Q16, ist ein Array von 16 x 16 Vortex-Kernen. Jeder Kern hat die Fähigkeit, Matrixmultiplikationen und KI-Berechnungen durchzuführen, aber jeder hat auch eine multifunktionale ALU für Operationen wie UND, ODER, Reduktion, Verschiebung und andere. Software ermöglicht es Entwicklern, verschiedene Algorithmustypen auszudrücken, einschließlich LSTM-Aktivierungsfunktionen und mehr. If-Then-Else-Anweisungen sind im gesamten Array verfügbar, sodass Entwickler die feinkörnige Sparsity nutzen können.
Jeder Kern im Array hat einen Einzelzyklus-Zugriff auf seine benachbarten Kerne sowie einen Einzelzyklus-Zugriff auf den In-Core-Speicher von 4 KB. Neben dem Array ist auch On-Chip-Speicher enthalten, der den Kernen deterministischen Zugriff mit geringer Latenzzeit ermöglicht.
Die Kerne arbeiten parallel auf eine Art und Weise, die Quadric als „Single Instruction, Multiple Decodierung“ bezeichnet; jeder Kern erhält bei jedem Zyklus die gleiche Anweisung. Aber basierend auf dynamischen Daten zur Laufzeit kann jeder Kern diese Anweisung anders interpretieren. Dadurch können Kerne oder Kerngruppen leicht unterschiedliche Funktionen ausführen.
Ebenfalls enthalten ist ein dedizierter Broadcast-Bus, der die Bandbreite in das Array optimiert und verwendet werden kann, um Konstanten, wie z auf den Bus abgebildet).
Dynamische Informationen gelangen über statische, softwaregesteuerte Load-Store-Einheiten in das Array, die deterministische Kernel-Laufzeiten ermöglichen. Das Gerät ermöglicht das gleichzeitige Laden und Speichern von zwei beliebigen Edges eines Geräts sowie eine spezielle Eigenschaft von einem Edge, die zum Senden von neuronalen Netzwerkgewichten verwendet werden kann – das gleichzeitige Laden von zwei Edges und das gleichzeitige Speichern von einem dritten Edge können die Laufzeiten der Rechenausführung verkürzen.

Daniel Firu (Quelle:Quadric)
„Sie können auf eine Seite laden und dann von einer senkrechten Seite lagern“, sagte Firu. „Dadurch können einige ziemlich interessante Dinge auf Softwareebene passieren. Sie können mit diesem Paradigma auch beginnen, Dinge wie Daten-Neuzuordnungen und Rotationen von Bildern und ähnliches zu tun.“
Inzwischen bieten softwaregesteuerte statische Speicher (kein Cache) auf dem Chip Platz für große Datenstrukturen. Quadric ermöglicht den API-Zugriff auf diese, sodass Entwickler beliebige Datenstrukturen darin definieren können. Im Q16-Chip sind die Speicher 8 GB groß, genug, um „zwei oder drei Frame-Puffer bei HD oder ein ganzes neuronales Netzwerk von Gewichten hineinzupassen“, sagte Firu.
Software-Stack
Quadric hat seinen Software-Stack vor Silizium gebaut. Kunden verwenden es seit einem Jahr mit dem Architektursimulator des Unternehmens oder mit FPGAs, sagte Kheterpal. Der Stack von Quadric abstrahiert die Architektur und den Befehlssatz durch einen LLVM-basierten Compiler mit einer C++-API darüber.
Der Quellmodus unterstützt verschiedene datenparallele Algorithmen mit C++-Steuerung auf Quellebene der Architekturmerkmale des Prozessors. Da neuronale Netze immer komplexer werden, ermöglicht der Quellmodus Entwicklern auch, benutzerdefinierte Operationen auszudrücken.
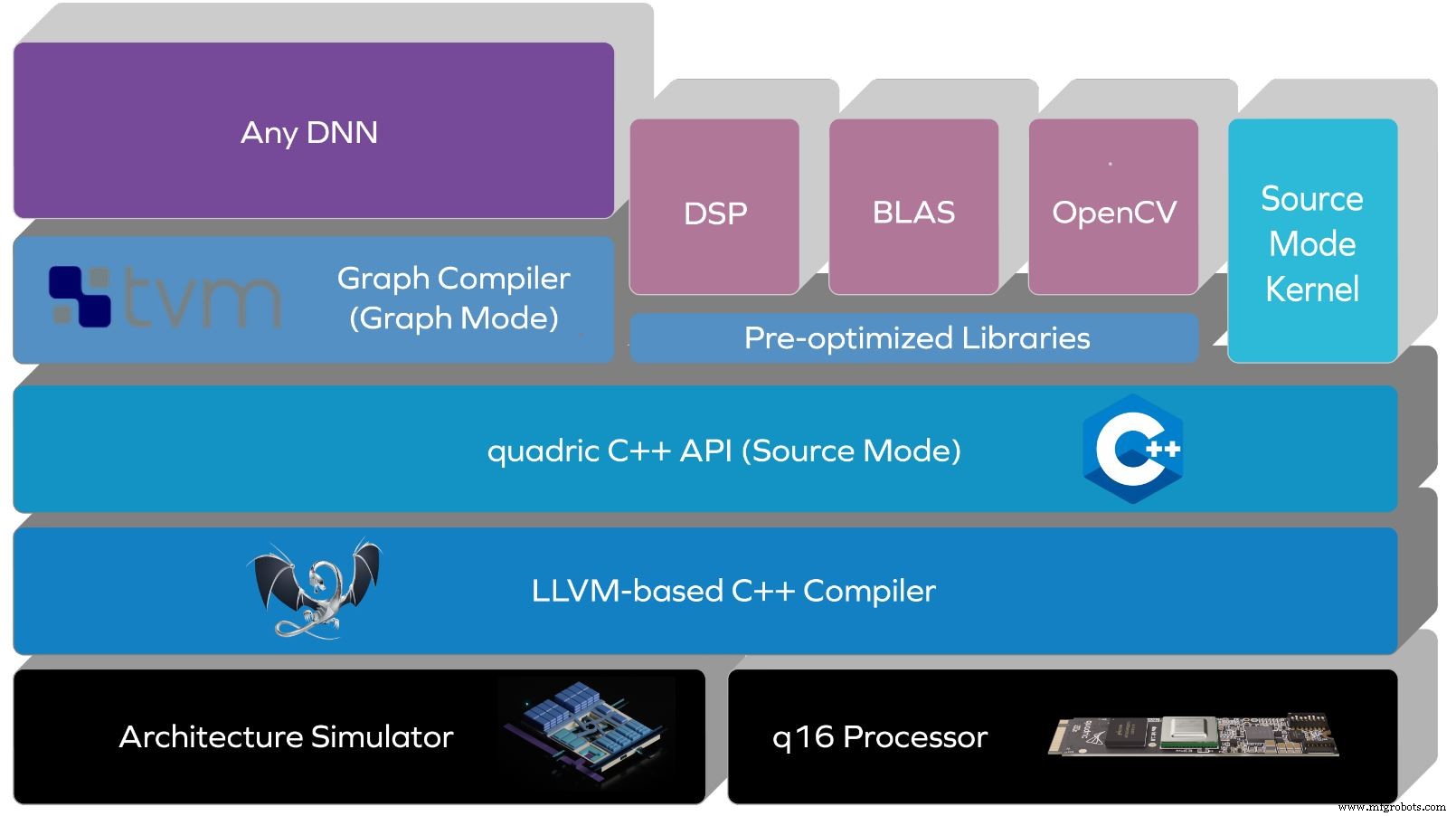
Quadrics Software-Stack (Quelle:Quadric)
Ein zukünftiges Update des Stack wird einen No-Code-Graph-Modus bieten, der TensorFlow- oder ONNX-Versionen neuronaler Netze unterstützt. Dazu gehört ein TVM-basierter Deep Neural Network (DNN)-Compiler, der automatisch Code generiert.
„Wir kombinieren die Leistungsfähigkeit von No-Code mit der Flexibilität, Ihren eigenen benutzerdefinierten Code zu haben und diese auf interessante Weise zu kombinieren, um Ihre Anwendung zu erreichen“, sagte Kheterpal. „Die meisten Plattformen bieten nur eine KI-spezifische Architektur mit einer Art DNN-Compiler – aber wie sieht es mit der Anpassung aus? Was ist mit einem DNN, das nicht unterstützt wird? Was ist mit Operatoren, die nicht unterstützt werden? Wir haben diese Einschränkungen nicht, da dies ein vollständiger Turing-Kern ist. Die Kerne können jede Operation ausführen. Die Codeflexibilität gibt Entwicklern die Möglichkeit, jeden beliebigen Algorithmus zu schreiben.“
Chip-Roadmap
Der Q16-Chip von Quadric, der 256 Vortex-Kerne in einem 16 x 16-Array in 16-nm-Silizium aufweist, bietet 4 INT8 DNN TOPS. Es kann ResNet-50 mit 200 Inferenzen pro Sekunde ausführen (für INT8-Parameter bei einer Bildgröße von 224 x 224) und verbraucht durchschnittlich 2 W.
Die Roadmap von Quadric umfasst eine zweite Generation der Architektur sowie ein Tapeout eines Q32-Chips (ein Array von 1.000 Kernen), „wahrscheinlich in 7 nm“, sagte Firu. Während der Q16 ausschließlich ein Beschleuniger ist (er würde neben einem System-Host-Prozessor sitzen), kann der in Entwicklung befindliche Q32 auch Arm- oder RISC-V-Kerne enthalten, die als Host fungieren.
Ein M.2-Format-Entwicklerkit mit einem Q16-Prozessor und 4 GB externem Speicher, der direkt dem universellen Speicherplatz des Q16 zugeordnet ist, ist ab sofort erhältlich.
>> Dieser Artikel wurde ursprünglich auf unserer Schwesterseite EE veröffentlicht Zeiten.
Verwandte Inhalte:
- Hardwarebeschleuniger dienen KI-Anwendungen
- Wenn ein DSP einen Hardwarebeschleuniger schlägt
- Ein Leitfaden zum Beschleunigen von Anwendungen mit genau den richtigen benutzerdefinierten RISC-V-Anweisungen
- Inferenz-Chipleistung baut auf optimiertem Speicher-Subsystem-Design auf
- Neue KI-Beschleunigungsmodule verbessern die Edge-Leistung
- Edge AI fordert die Speichertechnologie heraus
Für mehr Embedded, abonnieren Sie den wöchentlichen E-Mail-Newsletter von Embedded.
Eingebettet
- Hybrid-Cloud-Umgebungen:Ein Leitfaden für die besten Anwendungen, Workloads und Strategien
- KI-Chiparchitektur zielt auf die Grafikverarbeitung ab
- Wireless-MCU verfügt über eine Dual-Core-Architektur
- Spezialisierte Prozessoren beschleunigen Endpoint-KI-Workloads
- Referenzdesign unterstützt speicherintensive KI-Workloads
- Smart Sensor Board beschleunigt die Entwicklung von Edge-KI
- Smart-Kamera bietet schlüsselfertige Edge Machine Vision Edge-KI
- IBM präsentiert eine hybride Blockchain-Architektur für das Internet der Dinge
- Omrons TM Cobot beschleunigt Integration und Programmierung
- Hyperspektrales Sehen. Was ist es?