


Startup packt 1000 RISC-V-Kerne in KI-Beschleunigerchip
Der energieeffiziente Chip des Startups zielt auf M.2 ab Beschleunigerbuchsen für Geschwindigkeitsempfehlungsmodelle in Rechenzentren.
Zeitgleich mit der Hot Chips-Konferenz ist das Startup Esperanto diese Woche aus dem Stealth-Modus mit dem bisher leistungsfähigsten kommerziellen RISC-V-Chip hervorgegangen – einem KI-Beschleuniger mit Tausenden von Kernen, der für Hyperscale-Rechenzentren entwickelt wurde. Während der Chip in einer Reihe von Spannungs- und Leistungsprofilen zwischen 10 und 60 W betrieben werden kann, liegt sein „Sweet Spot“ bei 20 W Leistung pro Chip, eine Konfiguration, die es ermöglicht, sechs Chips auf einer Glacier Point-Beschleunigerkarte zu montieren, Gesamtverbrauch unter 120 W. Die Gesamtleistung von sechs Chips beträgt ca. 800 TOPS.
Der ET-SoC-1 von Esperanto soll die meisten RISC-V-Kerne haben, die jemals auf einem einzigen Chip gebaut wurden:1.093. Die Zahl umfasst 1.088 benutzerdefinierte RISC-V-Kerne von ET-Minion, die als energieeffiziente KI-Beschleunigungsmotoren dienen. Ebenfalls enthalten sind vier ET-Maxion RISC-V-Kerne und ein RISC-V-Serviceprozessor. Das gesamte Design ist auf Energieeffizienz ausgerichtet.
Vor Hot Chips, EE Times sprach mit dem Branchenveteranen Dave Ditzel, dem Gründer und Vorstandsvorsitzenden von Esperanto. (Zu Ditzels Referenzen gehört die Co-Autorschaft mit David Patterson an der bahnbrechenden Arbeit „The Case for the Reduced Instruction Set Computer“, die 1980 veröffentlicht wurde.)

Dave Ditzel (Quelle:Esperanto)
„Wir sind die ersten, die tausend RISC-V-Kerne auf einem einzigen Chip unterbringen“, sagte Ditzel. „Die Leute sprechen seit Jahren von Vielkern-CPUs, aber davon haben wir nicht viel gesehen. Die meisten RISC-V-Sachen, die es gibt, sind für Embedded.
„Wir sagten:‚Lass uns ihnen zeigen, dass RISC-V High-End leisten kann… Wir werden ihnen zeigen, was wirklich erfahrene CPU-Designer hier können‘.“
Kundenanforderungen
Das CPU-Designer-Team von Ditzel konnte den Betreibern von Hyper-Scale-Rechenzentren Details zu ihren Anforderungen entlocken.
„Sie wollten keinen Trainingschip, sie haben kein Problem mit dem Training“, sagte Ditzel. KI-Training ist oft ein Offline-Problem, und die enorme x86-CPU-Kapazität von Hyperscalern ist nicht immer auf Spitzenlast. Daher kann diese Kapazität, wenn verfügbar, für Schulungen verwendet werden. „Ihr eigentliches Problem ist die Schlussfolgerung“, fügte Ditzel hinzu. „Das ist es, was ihre Werbung antreibt. Sie brauchen eine Antwort in 10 Millisekunden oder weniger.“
Daher wurde die Beschleunigung der Empfehlungs-Inferenz-Engine für Online-Werbung zu einem Schwerpunkt des Rechenzentrumschips. Die Anforderungen der Hyperscaler zur Beschleunigung dieses Modelltyps waren ziemlich eindeutig.
„Unsere Kunden wollten 100 Megabyte Speicher auf dem Chip – all die Dinge, die sie mit Inferenz machen wollten, passen in 100 Megabyte“, sagte er. Kunden wollten auch eine externe Schnittstelle für Off-Chip-Speicher. „Die eigentliche Frage ist, wie viel man auf der Beschleunigerkarte halten kann“, erklärt Ditzel. „Stellen Sie sich die Karte als Recheneinheit vor, nicht den Chip. Sobald Sie Speicher auf der Karte haben, können Sie viel schneller auf Dinge zugreifen, als über den PCIe-Bus zum Host zu gehen.“
Klick für Bild in voller Größe

Esperanto passt sechs duale M.2-Karten mit jeweils einem Chip auf eine Glacier Point-Beschleunigerkarte. (Quelle:Esperanto)
Das On-Chip-Speichersystem verfügt über L1-, L2- und L3-Caches und ein vollständiges Hauptspeichersystem mit Registerdateien für insgesamt knapp über 100 MB. Das On-Card-Speichersystem kann die meisten Gewichte und Aktivierungen im Modell in etwa 100 GB aufnehmen.
Empfehlungsmodelle sind notorisch schwer zu beschleunigen, was einer der Gründe dafür ist, dass sie immer noch auf vorhandenen CPU-Servern ausgeführt werden.
„Wenn Sie aus 100 Millionen Kunden auswählen und was sie in letzter Zeit gekauft haben, müssen Sie auf diesen ... Speicher auf der Karte zugreifen und alle Arten von zufälligen Speicherzugriffen durchführen, damit Caches nicht arbeiten. Man braucht wirklich mehr von einem klassischen Computer“, sagte Ditzel. Die „x86-Server handhaben gute Speichermengen und sie haben Pre-Fetching, und Allzweck-CPUs handhaben diese Arbeitslast sehr gut. Aus diesem Grund war es für jeden Accelerator schwierig, in das Empfehlungsgeschäft einzusteigen.“
Außerdem wird die Unterstützung von INT8 zusammen mit den Datentypen FP16 und FP32 benötigt. Die Forderung nach Gleitkomma-Mathematik ergibt sich sowohl aus der Notwendigkeit, die höchstmögliche Vorhersagegenauigkeit beizubehalten, als auch aus der fehlenden Neigung, Programme für Mathematik mit geringerer Präzision zu portieren oder neu zu schreiben. Ditzel sagte, dass führende x86-Serverchiphersteller erst kürzlich 8-Bit-Vektorerweiterungen zu Server-CPUs hinzugefügt haben.
„Die meisten Schlussfolgerungen, die in [einem Hyper-Scale-Rechenzentrum] auf ihren Millionen x86-Servern vor sich gehen, sind immer noch 32-Bit-Float“, sagte er.
Der Chip von Esperanto auf einer dualen M.2-Karte ist so konzipiert, dass er in Beschleunigersteckplätze innerhalb einer bestehenden x86-CPU-Serverinfrastruktur passt. Daraus ergibt sich eine Leistungsgrenze von 120 W, die eine Luftkühlung erfordert.
Ditzel sagte, das Design von Esperanto konkurriere nicht direkt mit internen Bemühungen wie Google TPUs oder Inferentia von Amazon Web Services. Hyperscaler „versuchen, die gesamte Community dazu zu bringen, Beschleunigerchips für sie zu bauen. Viele dieser Unternehmen glauben an Open Computing und das [Open Compute Project].“ Daher „kaufen sie OCP-Server und möchten, dass dort standardisierte Sachen reinkommen. Wenn es Konkurrenz gibt, lieben sie es … sie versuchen, den Wettbewerb zu fördern und den Leuten zu zeigen, was möglich ist.“
Dennoch besteht das Startup darauf, dass Betreiber großer Rechenzentren externe Lieferanten für Beschleunigerchips benötigen. "Es ist immer noch eine Make-versus-Buy-Entscheidung." Ein Esperanto-Kunde hatte beispielsweise keinen Zugang zu intern entwickelten Chips, die von einer anderen Abteilung verwendet werden. „Wenn Sie schlagen, was sie haben, ist der Einstieg in eines dieser Unternehmen möglich.“
Neuer Ansatz
Esperanto hat den entgegengesetzten Ansatz zu den riesigen leistungshungrigen Chipbeschleunigern der Wettbewerber gewählt und bietet einen Chip mit geringerer Leistung an, der mehrfach verwendet werden kann. Der Ansatz adressiert die Anforderungen an die Speicherbandbreite, da mehr Pins für Speicher-I/O verwendet werden können, ohne auf teures HBM zurückgreifen zu müssen.
Die Hardware von Esperanto ist auch als Allzweckcomputer konzipiert; Trotz der Fokussierung auf Empfehlungsmodelle kann der Chip laut Ditzel die Parallelverarbeitung beschleunigen. Eine Sechs-Chip-Beschleunigerkarte enthält etwa 6.000 parallele Kerne, und jeder Kern kann zwei Threads ausführen, die auf jedes beliebige Problem geworfen werden können.
Ein weiterer Trick im Ärmel von Esperanto ist ein aggressives energieeffizientes Design. Die Kundenanforderungen legen das Leistungsbudget auf insgesamt 120 W fest, während der maximale Speicherplatz auf einer Glacier Point-Karte sechs Chips oder 20 W pro Chip betrug. Im Vergleich dazu arbeiten KI-Inferenzbeschleuniger mit mehr als dem Zehnfachen dieser Menge.
Esperanto ging das Thema aus mehreren Blickwinkeln an. Die Taktfrequenz wurde auf ein optimales Niveau von etwa 1 GHz reduziert. Die Versorgungsspannung wurde auf etwa 0,4 V reduziert, über die Grenze von SRAMs hinaus. Die Schaltkapazität wurde durch die Verwendung von mageren RISC-V-Kernen mit dem kleinsten kommerziell nutzbaren Befehlssatz unterstützt, um die Anzahl der Transistoren zu reduzieren. Als fortschrittliche aber stabile Prozesstechnologie wurde TSMC 7nm gewählt.
Klick für Bild in voller Größe
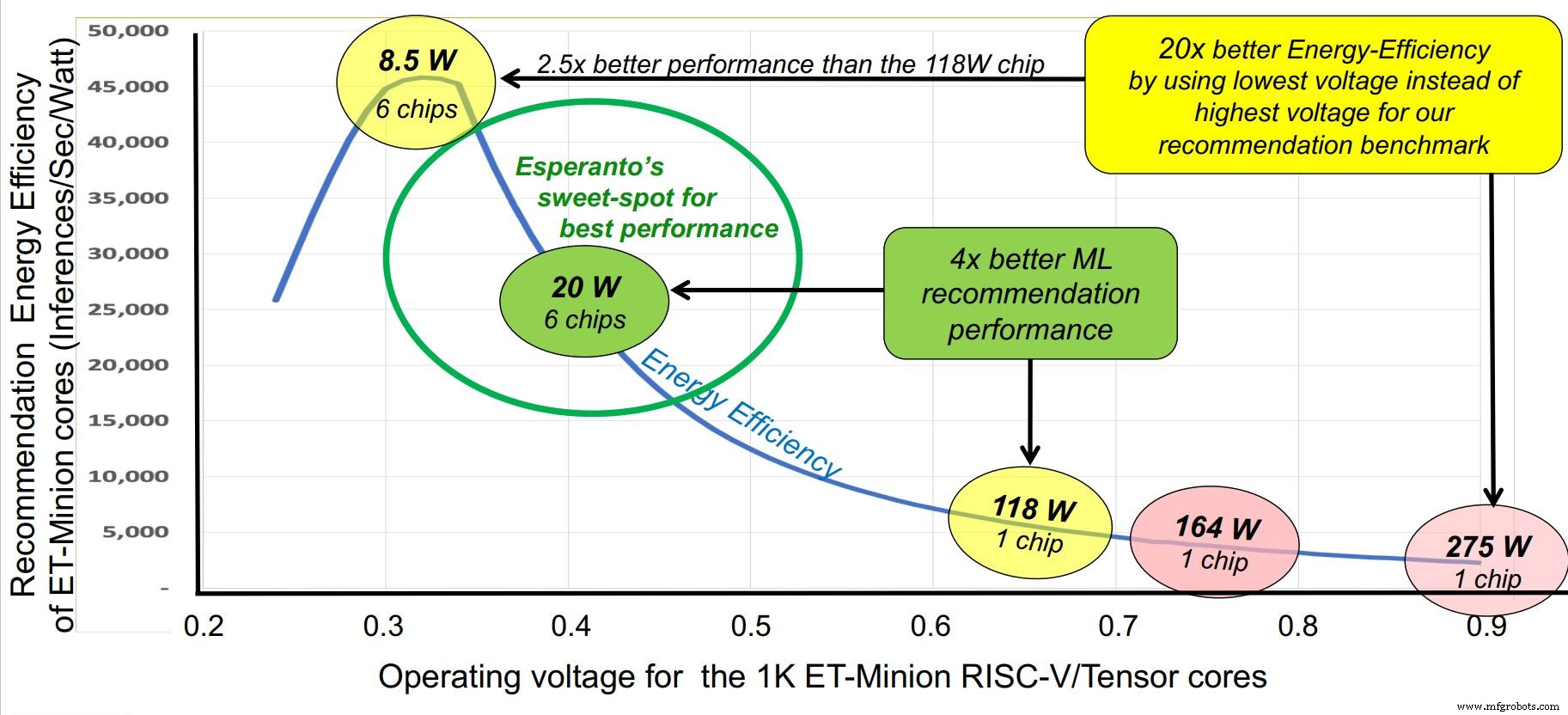
Esperanto hat einen „Sweet Spot“ für den Betrieb bei etwa 1 GHz identifiziert. (Quelle:Esperanto)
Kerndesign
Der Chip von Esperanto enthält 1.088 ET-Minion-Kerne, die die KI-Arbeitslast verarbeiten. Die Kerne sind 64-Bit-RISC-V-Prozessoren der Reihe nach, wobei die eigene KI-optimierte Vektor- und Tensoreinheit von Esperanto einen Großteil der Chipfläche einnimmt. Fließkomma-MACs dominieren die Konfiguration. Ungewöhnlicherweise haben Integer-MACs die doppelte Verarbeitungsbreite von Gleitkommazahlen (gemäß Kundenanforderungen, bemerkte Ditzel). Ebenfalls unterstützt werden vektortranszendente Anweisungen wie Sigmoidfunktionen, die in Deep-Learning-Modellen üblich sind. Da die Kerne in einer einzigen Niederspannungsdomäne laufen, wurden mehr Transistoren mit SRAM im kleinen L1-Cache verwendet, um eine robuste Leistung zu gewährleisten.
Klick für Bild in voller Größe
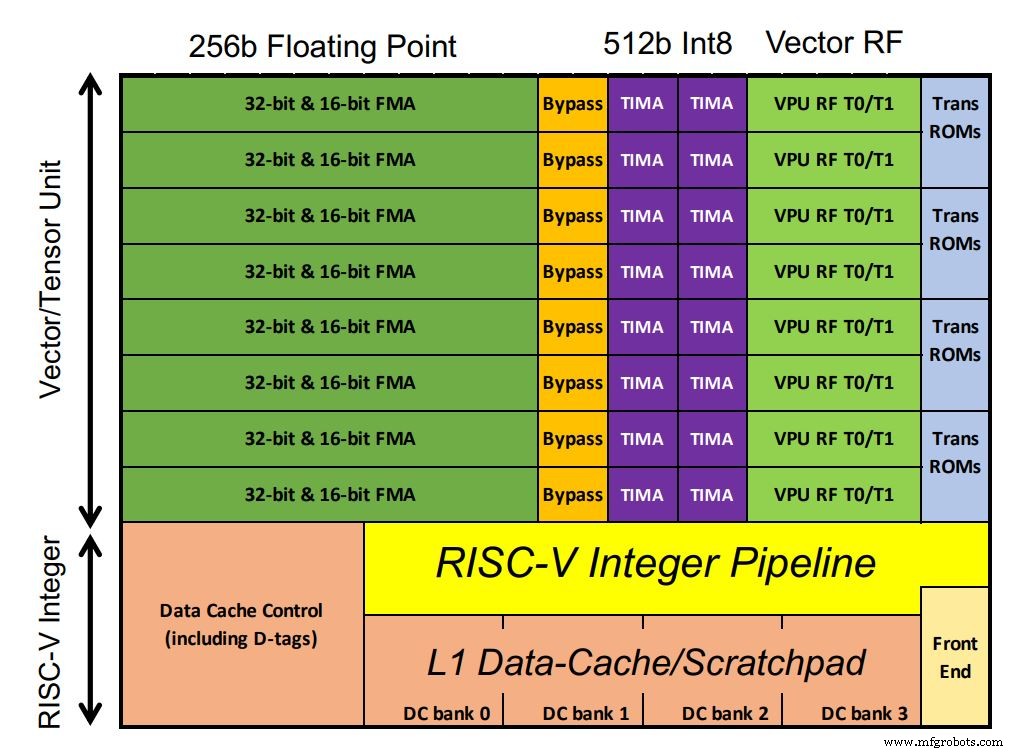
Der Chip von Esperanto enthält 1.088 ET-Minion-Kerne (zum Vergrößern auf das Bild klicken) (Quelle:Esperanto)
Jeder Kern ist zu 128 GOPS pro GHz fähig. Ein benutzerdefinierter Multi-Cycle-Tensor-Befehl führt große Matrixmultiplikationen durch, wobei ein separater Controller bis zu 512 Zyklen übernimmt und die volle 512-Bit-Breite verwendet. Dadurch kann der einzelne Tensorbefehl mehr als 64.000 arithmetische Operationen ausführen, bevor der Controller den nächsten RISC-V-Befehl abruft. Dies reduziert die Befehlsbandbreite, da der Großteil der Arbeitslast den Tensorbefehl verwendet. Daher ist nur eine Anweisung pro 512 Taktzyklen erforderlich.
Acht ET-Minion-Kerne bilden eine „Nachbarschaft“, und modifizierte Anweisungen nutzen ihre physische Nähe. Eine weitere Funktion namens „kooperative Lasten“ ermöglicht es Kernen, Daten ohne Cache-Abruf direkt voneinander zu übertragen. Diese Konfiguration spart Strom. Die acht Kerne teilen sich außerdem einen großen L2-Cache aus Gründen der Energieeffizienz.
Wenn man wieder herauszoomt, bilden vier 8-Kern-Nachbarschaften ein „Minion Shire“ mit 34 Shires auf jedem Chip, also insgesamt 1.088 Kernen. (Eine Berechnung mit nur 1.024 Kernen zur Verbesserung der Ausbeute ist ebenfalls möglich, sagte Ditzel). Vier ET-Maxion-Kerne, jeder mit einer Leistung, die ungefähr mit einem Arm A-72 vergleichbar ist, sind für den zukünftigen Standalone-Betrieb anstelle der aktuellen Beschleunigerkonfiguration vorgesehen.
Die Schwankung der Schwellenspannung wird gemildert, indem jedem Shire seine eigene Spannungsversorgung bereitgestellt wird, sodass die einzelnen Spannungen fein abgestimmt werden können.
Speichersystem
Jeder Chip hat vier 64-Bit-DDR-Schnittstellen – eigentlich repräsentiert jede Schnittstelle vier 16-Bit-Kanäle – für insgesamt 96x 16-Bit-Kanäle. Das Design verwendet LPDDR4x, das als Low-Power-Speicher für Smartphones entwickelt wurde. Die Energie pro Bit entspricht ungefähr der von HBM, aber die Beibehaltung der Gesamtmenge von 1.536 Bits über die Speicherschnittstelle für die Sechs-Chip-Beschleunigerkarte führt zu einer höheren Gesamtspeicherbandbreite.
Esperanto montiert seine Chips auf Dual-Socket-M.2-Karten; sechs passen auf eine OCP Glacier Point v2-Beschleunigerkarte (drei vorne, drei hinten). Das liefert etwa 800 TOPS mit den Chips, die mit 1 GHz laufen. Sie können auch auf PCIe-Karten mit niedrigem Profil (halbe Höhe, halbe Länge) montiert werden, die das Leistungsbudget jedes Chips auf etwa 60 W erhöhen. Die Chips können je nach Anwendung zwischen 300 MHz und 2 GHz arbeiten.
Basierend auf den Ergebnissen der Hardware-Emulation behauptete Ditzel, dass sechs Esperanto-Chips auf einer Glacier Point-Karte Konkurrenten übertreffen können. Der Vorteil des Startups ist bei Empfehlungs-Benchmarks deutlich, wenn man das Speichersystemdesign und die Performance-pro-Watt-Zahlen betrachtet, eine Folge der Fokussierung auf ein Low-Voltage-Design.
Zukünftige Versionen könnten eine verkleinerte Version von ET-SoC-1 für Edge-Anwendungen enthalten. Ditzel sagte, die aktuelle Version solle in den „nächsten Monaten“ auf den Markt kommen.
>> Dieser Artikel wurde ursprünglich auf unserer Schwesterseite EE veröffentlicht Zeiten.
Verwandte Inhalte:
- KI-fähige SoCs verarbeiten mehrere Videostreams
- Xilinx zielt auf die Auslagerung von Rechenzentren mit „zusammensetzbarer“ Hardware ab
- Reduced Operation Set Computing (ROSC) für die NNA-Funktionsabdeckung
- Hybridarchitektur beschleunigt KI- und Vision-Workloads
- Hardwarebeschleuniger dienen KI-Anwendungen
Für mehr Embedded, abonnieren Sie den wöchentlichen E-Mail-Newsletter von Embedded.
Eingebettet
- Revolver
- Gute Aussichten für EDA in der Cloud
- RISC-V-Gipfel:Highlights der Tagesordnung
- Arm ermöglicht benutzerdefinierte Anweisungen für Cortex-M-Kerne
- Entwerfen mit Bluetooth Mesh:Chip oder Modul?
- KI-Chiparchitektur zielt auf die Grafikverarbeitung ab
- Kleines Bluetooth 5.0-Modul integriert Chipantenne
- Forscher bauen winzige Authentifizierungs-ID-Tags
- Debüts des bildgebenden Radarprozessors für die Automobilindustrie mit 30 fps
- Low-Power-Radarchip verwendet neuronale Spiking-Netzwerke