


Ist 2017 das Jahr der Sprachschnittstelle?
In den letzten Jahren haben bedeutende Fortschritte in der automatischen Spracherkennung (ASR) zu einer Fülle von Geräten und Anwendungen geführt, die Sprache als ihre Hauptschnittstelle verwenden. Das IEEE-Spektrum Magazin hat 2017 zum Jahr der Spracherkennung erklärt; ZDNet berichtete von der CES 2017, dass Sprache die nächste Computerschnittstelle ist; und viele andere teilen ähnliche Ansichten. Wo stehen wir also in Bezug auf die Weiterentwicklung von Sprachschnittstellen? Dieser Beitrag gibt einen Überblick über den aktuellen Stand von Sprachschnittstellen und deren Basistechnologien.
Wie viele Ihrer Geräte kommunizieren mit Ihnen?
Sprachaktivierung ist überall um uns herum. Fast jedes Smartphone verfügt über eine Sprachschnittstelle, Flaggschiffe wie das Apple iPhone 7 und das Samsung Galaxy S7 inklusive Always-Listening-Funktionen. Die meisten Smartwatches bieten Sprachaktivierung sowie andere Wearables und insbesondere Hearables wie Apples AirPods und Samsungs Gear IconX. In den meisten dieser Geräte gibt es keine bequeme Möglichkeit, eine andere Schnittstelle zu integrieren, was Voice zu einer idealen und notwendigen Lösung macht. Neue Kameras, wie die GoPro Hero 5, lassen sich per Sprachbefehl bedienen, was sich hervorragend für Selfies eignet. Sprachgesteuerte Auto-Infotainment-Systeme sind zu einem Standard geworden und machen es viel sicherer, den Sender während der Fahrt zu wechseln.
Das Amazon Echo hat den Trend zu Gesprächsassistenten entzündet, der mit Google Home in Flammen steht und eine Vielzahl ähnlicher Klone auf der CES 2017 präsentiert wurde. Der Sprachdienst des Echos namens Alexa verfügt über mehrere integrierte Fähigkeiten. Du kannst zum Beispiel "Alexa, erzähl mir einen Witz" . sagen (sehr trockener Vortrag), "Alexa, haben die Krieger gewonnen?" (natürlich taten sie das) oder "Alexa, wer spielte in dem Film 2001:A Space Odyssey?" (kein anderer scheint es zu wissen). Es gibt auch eine Menge amüsanter Ostereier, wie die Antwort, wenn du "Alexa, starte die Selbstzerstörungssequenz" sagst. (Siehe auch dieses Video, das einige von Alexas Ostereiern zeigt).
Zusätzlich zu den integrierten Funktionen können Alexa von Drittanbietern mithilfe des Alexa Skills Kit (ASK) um neue Funktionen erweitert werden. Diese ASK ermöglicht es Entwicklern, Alexa neue Fähigkeiten beizubringen, damit sie (oder sie?) mehr Produkte und Dienste steuern und damit interagieren kann. Wie Sie in diesem Video sehen können, hat beispielsweise eine Person seinen iRobot Roomba gehackt und eine Fähigkeit hinzugefügt, um den Staubsaugerroboter zu steuern.
Andere Alexa-Fähigkeiten umfassen nützliche Dinge, wie das Bestellen von Essen in einer Vielzahl von Restaurants oder das Anrufen eines Ubers, und zufällige Vergnügungen, wie das Stellen magischer 8-Ball-Fragen, Seinfeld-Trivia und das Erlernen neuer Fakten über Obst. Die Zusammenarbeit zwischen Amazon und Unternehmen wie Whirlpool und GE wird auch die Eignung von Alexa im Smart Home stärken, indem Funktionen zur Steuerung von Haushaltsgeräten wie Waschmaschinen, Kühlschränken, Lampen und mehr hinzugefügt werden.
Derzeit scheint Amazon in diesem Markt führend zu sein, aber andere unternehmen große Anstrengungen (und Investitionen), um aufzuholen. Mark Zuckerberg rekrutierte Morgan Freeman als Stimme seines Sprachassistenten für künstliche Intelligenz (KI). Laut einer Notiz, in der beschrieben wird, wie er sie gebaut hat, hat Zuckerberg ein Jahr damit verbracht, die Anwendung als einfache KI zu entwickeln, um sein Zuhause "wie Jarvis in Iron Man" . zu führen (er nannte es auch Jarvis). Jarvis identifiziert angeblich anhand seiner Stimme, wer spricht, und erkennt auch Gesichter, sodass autorisierte Personen an der Tür hereingelassen werden können, während er Zuckerberg berichtet.
Ein weiterer interessanter Anwärter ist ein japanisches Amazon-Echo-ähnliches Gerät namens Gatebox, das einen holografischen Charakter namens Azuma Hikari aufweist.

Japans Antwort auf das Amazon Echo (Quelle:Gatebox)
Neben einem einfachen Lautsprecher nutzt das Gerät eine Leinwand und einen Projektor, um den virtuellen Assistenten sowohl visuell als auch akustisch zum Leben zu erwecken. Neben Mikrofonen verfügt es auch über Kameras sowie Bewegungs- und Temperatursensoren, die eine ganzheitlichere Interaktion mit dem Benutzer ermöglichen.
Wie funktioniert diese Fernfeld-Sprachaufnahme?
Wie hört und versteht ein Gerät Ihre Sprachbefehle, während es Musik auf der anderen Seite des Raums abspielt? Es gibt viele Komponenten, die dieses Kunststück ermöglichen, aber einige von ihnen sind von größter Bedeutung. Die erste ist die Engine für die automatische Spracherkennung (ASR), die es Maschinen ermöglicht, die von uns erzeugten Klänge in ausführbare Anweisungen umzuwandeln. Damit die ASR-Engine ordnungsgemäß funktioniert, muss sie eine saubere Sprachprobe empfangen. Dies erfordert eine Rauschunterdrückung und Echounterdrückung, um die Interferenzen herauszufiltern. Im Folgenden sind einige der wichtigsten Technologien aufgeführt, die die Fernfeld-Sprachaufnahme ermöglichen:
Deep Learning spielt dabei eine große Rolle. Die Fähigkeit, natürliche Sprache zu verstehen, wurde vor einigen Jahren etabliert, aber jüngste Verfeinerungen haben sie der Fähigkeit des Menschen nahe gebracht. Durch den Einsatz lernbasierter Techniken wie Deep Neural Networks (DNNs) haben sowohl die Sprachverarbeitung als auch die visuelle Objekterkennung in vielen Testfällen die menschliche Leistung erreicht oder übertroffen. DNNs werden während der Trainingsphase aus massiven Datensätzen generiert. Nachdem das Training offline durchgeführt wurde, werden die DNNs verwendet, um ihre Funktion in Echtzeit auszuführen.
Adaptive Beamforming ist der Schlüssel zu einer robusten sprachaktivierten Benutzeroberfläche. Es ermöglicht Funktionen wie Rauschunterdrückung, Sprecherverfolgung, falls sich der Benutzer während des Gesprächs bewegt, und Sprechertrennung, wenn mehrere Benutzer gleichzeitig sprechen.
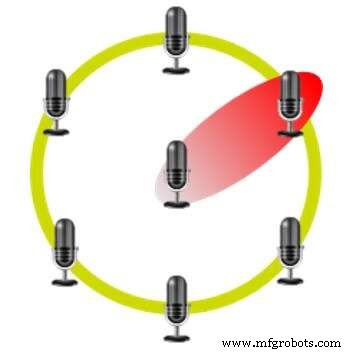
Beamforming mit einem hexagonalen Mikrofonarray (Quelle:CEVA)
Dieses Verfahren verwendet mehrere Mikrofone in festen Positionen relativ zueinander. Zum Beispiel verwendet das Amazon Echo sieben Mikrofone in einem sechseckigen Layout mit einem Mikrofon an jedem Scheitelpunkt und einem in der Mitte. Die Zeitverzögerung zwischen dem Empfang des Signals in den verschiedenen Mikrofonen ermöglicht es dem Gerät, zu erkennen, woher die Stimme kommt, und Geräusche aus anderen Richtungen zu unterdrücken.
Akustische Echounterdrückung ist notwendig, da viele der Produkte mit automatischer Spracherkennung auch selbst Töne erzeugen; B. Musik abspielen oder Informationen liefern. Auch während dieser Aktionen müssen die Geräte in der Lage sein zu hören, damit der Benutzer die Musik unterbrechen (barge-in) und stoppen oder eine andere Aktion anfordern kann. Um weiterhören zu können, muss das Gerät in der Lage sein, den von ihm selbst erzeugten Ton zu unterdrücken. Dies wird als akustische Echokompensation (AEC) bezeichnet.
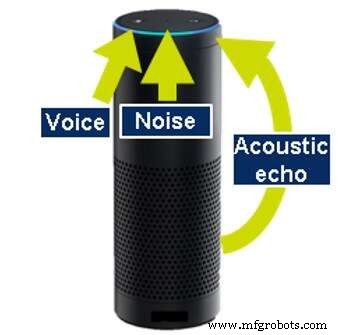
Akustische Echounterdrückung (Quelle:CEVA)
Um AEC durchzuführen, muss das Gerät den von ihm erzeugten Ton kennen, entweder durch Analysieren der Ausgabedaten oder durch Abhören der erzeugten Töne mit einem zusätzlichen dedizierten Mikrofon. Eine ähnliche Technologie wird auch verwendet, um Echos zu entfernen, die von Wänden und anderen Objekten um das Gerät zurückprallen.

Eine Multi-Mikrofon-Entwicklungsplattform zur Modellierung von DNNs, Beamforming- und Echokompensationsalgorithmen (Quelle:CEVA)
Eine andere Art von Echo wird durch die Benutzerbefehle selbst erzeugt, wenn sie von Gegenständen oder von Wänden zurückprallen. Das Unterdrücken solcher unvorhersehbarer Echos erfordert noch einen weiteren Algorithmus, der als Enthallung bezeichnet wird. Der Ton wird dann gefiltert und das Gerät kann auf Befehle des Benutzers hören.
Die heutigen Sprachschnittstellen sind alles andere als perfekt
Einerseits scheint 2017 ein bemerkenswertes Jahr für Sprachschnittstellen zu werden, wenn man bedenkt, wie weit sie bereits verbreitet sind. Andererseits ist es trotz all der beeindruckenden Fortschritte der letzten Jahre noch ein weiter Weg.
Es bleiben viele Probleme mit aktuellen Implementierungen von Sprachschnittstellen in massenproduzierten Geräten, aber das wird das Thema für eine zukünftige Kolumne sein. In meinem nächsten Beitrag möchte ich auf einige der Mängel und fehlenden Funktionen eingehen, die die heutigen Sprachschnittstellen beeinträchtigen. Stellen Sie sicher, dass Sie einschalten.
Eran Belaish ist Product Marketing Manager der Audio- und Sprachproduktlinie von CEVA und entwickelt exquisite Lösungen, die von Sprachauslösung und mobiler Stimme bis hin zu drahtlosem Audio und High-Definition-Heimaudio reichen. Obwohl Eran nicht mit der faszinierenden Welt des immersiven Klangs beschäftigt ist, taucht er gerne in die faszinierende Stille der Unterwasserwelt ein.
Eingebettet
- Der CEO von Monroe Engineering ist Finalist bei Entrepreneur of The Year von EY
- Die Befehlszeilenschnittstelle
- MajorTom:Alexa Voice Controlled ARDrone 2.0
- Motion als Lieferant des Jahres ausgezeichnet
- Mobius erhält Auszeichnung als Produkt des Jahres
- 2020 wird das Jahr der kontinuierlichen Intelligenz
- CMMS-Trends 2019:Das Jahr des Kunden
- Monroe wurde zum Unternehmen des Jahres 2019!
- The Great Wisconsin Chili Cook-Off
- Die vereinte Stimme der Druckluftindustrie