


Warum Daten die Grundlage für Zuverlässigkeit sind
 Im heutigen technologischen Zeitalter sind Daten der Schlüssel zur Entscheidungsfindung. Dieses Spezialgebiet wird als „Data Science“ bezeichnet. Unternehmen können die Technologie nutzen, indem sie Daten sammeln, analysieren und nutzen, um fundierte Entscheidungen zu treffen.
Im heutigen technologischen Zeitalter sind Daten der Schlüssel zur Entscheidungsfindung. Dieses Spezialgebiet wird als „Data Science“ bezeichnet. Unternehmen können die Technologie nutzen, indem sie Daten sammeln, analysieren und nutzen, um fundierte Entscheidungen zu treffen.
Eine Forschungsgruppe prognostiziert, dass die Datengröße bei dem aktuellen Datenwachstum bis 2025 163 Zettabyte betragen wird. Um diese Zahl besser zu verstehen, bedenken Sie, dass ein Zettabyte einer Billion Gigabyte entspricht. Dies wirft Fragen zur Datenspeicherung, -qualität und -verwaltung auf.
In diesem Artikel wird die Bedeutung von Daten und ihre Verwendung bei der Durchführung aussagekräftiger Reliabilitätsstudien erörtert. Die gängige Definition von Zuverlässigkeit ist die Wahrscheinlichkeit, dass ein Gerät, ein System oder eine Einrichtung für einen bestimmten Zeitraum unter bestimmten Betriebsbedingungen fehlerfrei arbeitet. Daher sind genaue historische Fehlerdaten und deren ordnungsgemäße Analyse für jede Zuverlässigkeitsanalyse von entscheidender Bedeutung.
Die Datenanalyse bietet die Möglichkeit, riesige Datenmengen zu untersuchen und nützliche Informationen zu extrahieren, die dann eine bessere Entscheidungsfindung unterstützen können. Dies ist nur möglich, wenn man den Daten angemessen vertraut, denn schlechte Daten können zu schlechten Entscheidungen führen.
Vorteile der Datenanalyse
Die Zuverlässigkeitsanalyse ist eine effektive Methode, um Management und Ingenieure bei technischen und finanziellen Entscheidungen zu unterstützen. Die Datenanalyse hilft unter anderem dabei, Projektdesigns zu optimieren, Kosten zu senken, Komponentenlebensdauern vorherzusagen, Ausfälle zu untersuchen, Garantieintervalle auszuwerten, effektive Prüffristen zu implementieren und Key Performance Indicators (KPIs) zu ermitteln. Genaue Daten sind für die Durchführung einer umfassenden Zuverlässigkeitsstudie unerlässlich.
Datenfilterung und -erfassung sind wichtige Aufgaben eines jeden Zuverlässigkeitsingenieurs. Die Datensammlung ist die Methode zum Sammeln und Auswerten von Informationen über interessierende Variablen, um ein systematisches Modell zu erstellen, um bestimmte Forschungsfragen zu beantworten, Hypothesen zu bewerten und Ergebnisse zu schätzen und zu unterstützen.
Daher ist die Datenerhebung die gemeinsame Phase für alle Forschungen. Die Gewährleistung einer genauen und ehrlichen Datenerhebung ist der gemeinsame Faktor und das gleiche Ziel für diese Studien.
Es stehen viele Tools und Techniken zur Verfügung, um Daten so zu verarbeiten, dass sie genauer und zuverlässiger werden, z. B. um Ausreißer zu eliminieren, die die Gesamtergebnisse der Zuverlässigkeitsanalyse verzerren können.
Belastbare Daten erstellen
In jeder Betriebseinrichtung können genaue und zuverlässige Daten, einschließlich Anlagenwartungs- und Fehleraufzeichnungen, Betriebsfenster usw., die Grundlage für Zuverlässigkeitsstudien bilden. Leider verfügen nicht alle Unternehmen über die Systeme, Prozesse und die Kultur, die für die Datenerhebung und -verwaltung erforderlich sind.
Eine Voraussetzung für den Aufbau einer robusten Datenbank besteht darin, sicherzustellen, dass alle aussagekräftigen Datenpunkte gesammelt und gespeichert werden. Eine Datenbank, die nur einige wichtige Daten sammelt, kann ein unvollständiges und vielleicht sogar irreführendes Bild des aktuellen Betriebs und des Anlagenzustands bieten.
Die Verwendung validierter Werkzeuge, die Methoden zur Sammlung der bewerteten und zuverlässigen Daten sind, kann eine nützliche Praxis sein. Ein großes Unternehmen in Finnland berichtete beispielsweise, dass etwa jeder sechste geschlossene Wartungsbericht (17,2 %) keinen Fehlermodus enthielt.
Außerdem verzeichnete keiner der geschlossenen Wartungsberichte die Anzahl und Art der Ersatzteile. Diese Beobachtungen deuten darauf hin, dass dieses spezielle Unternehmen über eine begrenzte Datenbank verfügt, die nur eine begrenzte Perspektive auf Gerätefehler und Wartungshistorie bietet, wobei kritische Informationen fehlen, wie z. B. der Ort von Fehlern und deren Auswirkungen.
Eine weitere Voraussetzung für eine effektive Datenanalyse ist das zeitnahe Reporting von Daten. Wartungsabteilungen, die ihre Ergebnisse wöchentlich oder sogar monatlich melden, verlieren mit größerer Wahrscheinlichkeit kritische Daten und Aktivitäten als Unternehmen, die ein dynamisches System einsetzen, das Daten kontinuierlich konsolidiert.
Eine weitere bewährte Methode besteht darin, sicherzustellen, dass das Datenerfassungs- und -speichersystem die als qualitativ hochwertige Dateninstanzen und -werte angesehenen Daten mit so viel Automatisierung wie möglich definiert, um die Konsistenz bei der Berichterstellung und Datenbankdurchsuchbarkeit zu fördern. Ein Wartungsberichtssystem, das von offenen Textfeldern abhängig ist, wandelt die Datenanalyse im Wesentlichen in einen manuellen Prozess um.
Obwohl offene Textfelder in jeder gut gestalteten Datenbank einen Platz haben, sollten sie verwendet werden, um mehr Details und Erläuterungen bereitzustellen.
Stattdessen sollte das Datenerfassungs- und -speichersystem separate Zellen für jeden aussagekräftigen Datenpunkt haben und so viele Dropdown-Menüs wie möglich verwenden, um die Konsistenz von Beschreibung und Berichten zu gewährleisten. Zuverlässigkeitsingenieure können nur dann umfangreiche Zuverlässigkeitsstudien durchführen, wenn die Daten durchsuchbar und im gesamten System konsistent beschrieben sind.
Durch das Definieren der für eine Datenbank erforderlichen Berichts- und Analysetypen werden die einzuschließenden Datenfelder bestimmt. Daher ist der erste Schritt, um qualitativ hochwertige Daten zu erhalten, die zu beantwortende Frage zu definieren und sicherzustellen, dass die gesammelten Daten für diesen Zweck geeignet sind.
Für Zuverlässigkeitsstudien sollten Datenbanksystemfelder Wartungsinformationen zu Ersatzteilen, Ausfallarten, Arbeitsstunden, wichtigen Inspektionsergebnissen, beschädigten Komponenten und Routineaktivitäten sammeln. Darüber hinaus ermöglicht die Kontrolle der Konsistenz der Berichterstattung in diesen Bereichen über umfassende Dropdown-Menüs Softwareanwendungen, Schlüsselfunktionen auszuführen, wie die Berechnung der mittleren Zeit zwischen Ausfällen (MTBF), der Verfügbarkeit und anderer Zuverlässigkeits-KPIs.
Datenqualitätsfaktoren
Tools und Technologie
Es stehen unzählige Tools zur Verfügung, um die Datenqualitätsziele zu erreichen, darunter Tools zur Reduzierung von Duplikaten, zur Integration und Migration von Daten zwischen und zwischen Plattformen sowie zur Durchführung von Datenanalysen.
Datenanalysetools ermöglichen es dem Benutzer, Bedeutungen aus Daten zu extrahieren, z. B. durch Kombinieren und Kategorisieren von Daten, um Trends und Muster aufzudecken. Viele Technologien sind jetzt mobilfähig. Diese Technologien können menschliche und Systemfehler bei der Datenerfassung minimieren. Die Einführung dieser neuen Tools und Technologien kann dazu beitragen, die Datenqualität zu verbessern.
Menschen und Prozesse
Jeder Mitarbeiter auf allen Ebenen des Unternehmensbetriebs, von der Wartungsmannschaft über den Ingenieur bis hin zum Management, muss ein gemeinsames Verständnis der Rolle von Daten im Unternehmen haben. Dies beinhaltet, welche Daten erhoben werden, wie oft und zu welchen Zwecken die Daten verwendet werden. Neben Schulungen müssen klare Prozesse etabliert werden, um eine zuverlässige und konsistente Datenerhebung und -speicherung zu gewährleisten.
Organisationskultur
Managementunterstützung und Unternehmenskultur spielen eine entscheidende Rolle für die Datenqualität. Dem Management gemeldete KPIs sollten die Datenqualität überwachen. Wenn eine Organisation ein neues Projekt oder eine neue Initiative zur Leistungssteigerung, zur Erhöhung der Anzahl der Möglichkeiten oder zur Lösung wichtiger Probleme starten möchte, muss sie häufig Änderungen vornehmen, einschließlich Änderungen an Prozessen, Arbeitsrollen, Organisationsstrukturen und -arten sowie beim Einsatz von Technologie .
Verfahren und Arbeitsprozesse müssen aktualisiert und an Best Practices angepasst werden. Kontinuierliche Verbesserung wird der Treiber für den Erfolg sein. Die Qualität und Quantität der Daten werden für diesen Treiber entscheidend sein. Durch kontinuierliches Training kann die Bedeutung der Daten beim Personal entwickelt werden, was zur Verbesserung der Unternehmenskultur beiträgt.
Einfluss von Daten auf die Zuverlässigkeit
Um die Bedeutung der Datenqualität zu veranschaulichen, betrachten Sie die folgende Fallstudie. Eine Anlage startete ein Projekt zur Steigerung der Ölförderung durch die Installation eines neuen Gas-Öl-Trennpakets (GOSP) mit Rohölstabilisierungseinheiten. Die GOSPs würden aus Separationsfallen, Nass-Crude-Handling-Anlagen, einem Wasser-Öl-Separator, Gaskompressionsanlagen, einem Fackelsystem, Transfer-/Versandpumpen und Stabilisierungsanlagen bestehen.
Eine Studie zu Zuverlässigkeit, Verfügbarkeit und Wartbarkeit (RAM) wurde durchgeführt, um die Produktionsverfügbarkeit der Anlagen vorherzusagen und mit der Zielverfügbarkeit zu vergleichen. Die Studie würde auch verwendet werden, um Bereiche zu identifizieren, die den Produktionsdurchsatz begrenzen, Maßnahmen zur Erreichung der zur Erreichung der Produktionsziele erforderlichen Verfügbarkeit zu empfehlen, die Betriebs- und Wartungsphilosophien zu bestätigen, die zur Erreichung der Gesamtsystemverfügbarkeit angewendet wurden, und um Abhilfemaßnahmen oder potenzielle Konstruktionsänderungen zu definieren .
Die Rohdaten der Instandhaltung sind in Tabelle 1 zusammengefasst. Sie basieren auf Interviews mit Instandhaltungsteams bestehender Betriebsstätten. Die für die Studie gesammelten Daten hatten in einer Reihe von Bereichen Probleme, angefangen mit dem falschen Vergleich von Wartungsdaten alter Anlagen, um den Betriebsbereich für die neue Anlage zu bestimmen.
Tabelle 1 legt beispielsweise nahe, dass ein Kompressor alle 10 Monate aufgrund von Problemen mit der Gleitringdichtung 30 Tage lang außer Betrieb ist. Bei dieser Schätzung wird davon ausgegangen, dass ein Kompressor aufgrund von Problemen mit der Gleitringdichtung 10 Prozent seiner Lebensdauer mit Wartungen verbringt. Diese Annahme ist falsch, da die Einrichtung neue Technologien übernehmen wird. Darüber hinaus werden viele Erfahrungen aus älteren Anlagen in das neue Design einfließen.
Eine weitere falsche Annahme aus den Daten ist die Auswirkung von Korrosion. Die Rohdaten deuten darauf hin, dass der Kompressor alle vier Jahre (48 Monate) 30 Tage lang wegen Schachtfraß in Wartung gehalten wird. Die Verwendung von verbessertem Material in der Kompressorwelle beseitigt diese Art von Problemen.
Tabelle 1 zeigt außerdem, dass die mittlere Reparaturzeit (MTTR) aufgrund von Vibrationen 60 Tage beträgt. Vergleichen Sie diese Annahme mit der durchschnittlich erwarteten MTTR für neue Kompressoren von nur vier Tagen aufgrund eines verbesserten Ersatzteilmanagements.
Wie dieses Beispiel veranschaulicht, sind die Annahmen, die aus Daten extrahiert wurden, die für alternde Einrichtungen mit alter Ausrüstung stimmen können, nicht korrekt, wenn sie auf neue Einrichtungen angewendet werden, die mit verbesserten Materialien und effizienteren Technologien ausgestattet sind.
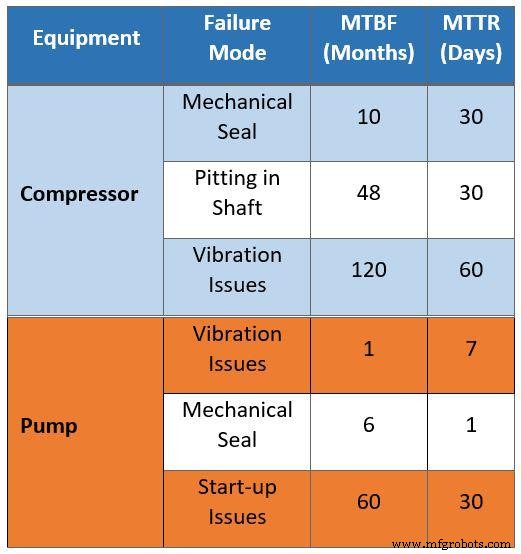
Tabelle 1. Feldrohdaten, die für eine Zuverlässigkeits-, Verfügbarkeits- und Wartbarkeitsstudie gesammelt wurden
Tabelle 2 fasst denselben Datensatz zusammen, der von Zuverlässigkeitsingenieuren korrigiert wurde. Die Ingenieure griffen auf dieselben Daten zu, die auch dem Drittanbieter zur Verfügung gestellt wurden, und filterten die Rohdaten, um alle Wartungsprobleme zu beseitigen, die durch die Prozessinstrumentierung automatisch korrigiert werden könnten. Die Daten wurden dann nach Wartungs- und Betriebsmanagementstrategien kategorisiert, um Probleme im Zusammenhang mit Konstruktionsfehlern wie Engpässe, begrenzte Kapazität und Verfügbarkeit zu identifizieren.
Die korrigierten Daten können auf die neue Anlage angewendet und für Entscheidungen zur Designoptimierung verwendet werden. Beispielsweise zeigen die Ausfallarten für Gaskompressoren jetzt eine MTBF von acht Jahren aufgrund trockener Dichtungen und eine MTTR von drei Tagen. Außerdem wurden die Korrosionsannahmen für Wellenkompressoren durch verbesserte Materialien im neuen Anlagendesign eliminiert.
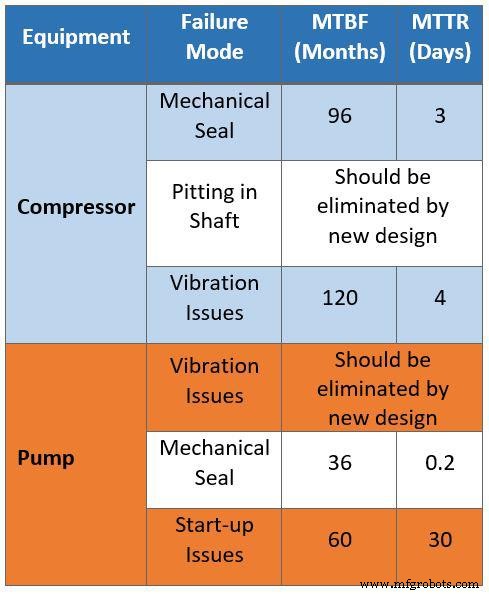
Tabelle 2. Gefilterte Daten, die für die Zuverlässigkeits-, Verfügbarkeits- und Wartbarkeitsstudie gesammelt wurden
Die Verfügbarkeit und Kapazität für beide Designs sind in Abbildung 1 dargestellt. Dies veranschaulicht den Unterschied in den Ergebnissen zwischen den beiden Modellen basierend auf den bereitgestellten Datensätzen sowie den Unterschied in den Verfügbarkeits- und Kapazitätsergebnissen. Die ursprünglichen Daten beziffern die Verfügbarkeit der neuen Anlage aufgrund einer langen MTTR und einer kurzen MTBF mit 77,34 Prozent, während der korrigierte Datensatz die Gesamtverfügbarkeit mit 99 Prozent berechnet, was der tatsächlichen Situation entspricht.
Bei demselben Projekt wurde eine ähnliche Praxis für die anderen Geräte durchgeführt. Das Projektmanagementteam (PMT) wurde angewiesen, aufgrund der hohen Verfügbarkeit Ersatzgeräte zu eliminieren. Die Ergebnisse wurden verwendet, um die Designkonfiguration für eine vollständige Systemauslastung zu optimieren. Wie diese Fallstudie zeigt, kann die Verwendung korrigierter Daten einen großen Einfluss auf die Investitions- und Baukosten neuer Projekte haben, indem unnötige Ausrüstung eliminiert und die Fertigstellungszeit für das Projekt beschleunigt und Kosten vermieden werden.
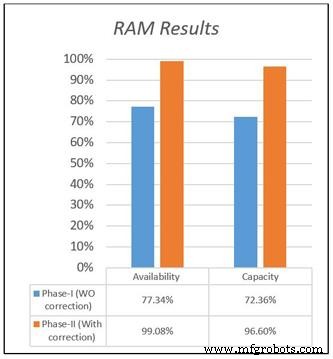
Abbildung 1. Ergebnisse der Studie zu Zuverlässigkeit, Verfügbarkeit und Wartbarkeit (RAM)
Abbildung 2. Die Beziehung zwischen Eingabedaten, Konstruktions- und Simulatorergebnissen
Aussagekräftige Ergebnisse für jede Zuverlässigkeitssoftware oder jeden Simulator hängen von der Qualität der Eingabedaten und des Designs ab. Wie heißt es so schön:„Müll rein, Müll raus“. Abbildung 2 zeigt die Beziehung zwischen Entwurfs- und Eingabedaten mit den Ergebnissen der RAM-Simulation. Sobald das RAM-Modell auf der Grundlage von Eingabedaten aufgebaut ist, kann eine potenzielle Optimierung eingeführt werden. Die Daten sind das Schlüsselelement für das Modell und andere Zuverlässigkeitsleistungsmessungen.
Gleiches gilt für fokussierte Reliabilitätsstudien. Zuverlässigkeitsingenieure verbringen einen Großteil ihrer Zeit damit, Daten im Betrieb zu analysieren. Ingenieure können beispielsweise eine Zuverlässigkeitsstudie zu bestimmten Elementen mit schlechtem Akteur durchführen, die als Komponente, Ausrüstung oder System mit hohen Wartungskosten und hohen Ausfallraten definiert sind.
Die Ergebnisse dieser Bewertung werden verwendet, um begrenzte Ressourcen auf Gegenstände mit hoher Auswirkung zu konzentrieren, die den größten Nutzen für den Außendienst in Bezug auf Wartungskosten und Verfügbarkeit haben. Wenn Ingenieure nicht repräsentative Daten oder nicht genügend Daten haben, werden alle Ergebnisse und Empfehlungen nicht die wirklichen Probleme lösen.
Dies stellt eine verpasste Gelegenheit dar, der Wartungsplanung, dem Ersatzteilmanagement, der Wartungsbudgetierung und den technischen Herausforderungen einen Mehrwert zu verleihen. Daher erfordern Qualitätsdaten effiziente Datenerfassungssysteme, die die Art und Menge der Daten, die erforderlich sind, um die Entscheidungen der Organisation zu unterstützen, eindeutig identifizieren.
3 wichtige Schritte zur Verbesserung der Datenqualität
1. Stellen Sie die richtige Datenbankplattform bereit
Die für die Organisation ausgewählte Lösung sollte keine Wartungsmeldungen oder Arbeitsaufträge schließen, bis alle erforderlichen Felder ausgefüllt sind. Mit anderen Worten, die ausgewählte Plattform sollte Verknüpfungen deaktivieren, um die Konsistenz der gesammelten Daten zu gewährleisten.
2. Integrieren Sie vorhandene Funktionen in eine umfassende Lösung
Die Plattform sollte alle Zuverlässigkeitsfunktionen in einer Lösung integrieren, um Daten besser zu integrieren und die Anzahl der in einem Unternehmen bereitgestellten Systeme zu reduzieren. Wenn beispielsweise Ersatzteile aus dem Lager entnommen wurden, sollten diese gegen eine besondere Benachrichtigung verrechnet werden. Dies würde eine Plattform erfordern, die das Ersatzteilmanagement mit den Wartungsaktivitäten vereint.
3. Implementieren Sie ein Programm zur Datenqualitätssicherung
Die Qualitätssicherungsaktivitäten für die bereitgestellte Lösung sollten eine regelmäßige Prüfung der Datenqualität im gesamten Unternehmen umfassen. Beispielsweise könnte das Qualitätssicherungsteam stichprobenartig 5 Prozent der Wartungsmeldungen und Arbeitsaufträge für jede Betriebsstätte prüfen, um die Qualität der gesammelten Daten zu bewerten. Die Ergebnisse dieser Bewertung könnten dann verwendet werden, um die Nutzung der Lösung weiter zu verbessern und eine effektive Datenbank sicherzustellen.
Daten sind der Grundstein
Vollständige Daten zur Wartung und Reparatur von Anlagen müssen korrekt erfasst, gespeichert und analysiert werden. Mitarbeiter an vorderster Front, einschließlich Wartungsteams und Betriebspersonal, die an der Datenerfassung beteiligt sind, müssen auch die Bedeutung ihrer Rolle für die Datenqualität verstehen.
Denken Sie daran, dass Daten der Eckpfeiler für die Entscheidungsfindung in jedem Unternehmen sind und die Datenqualität im Mittelpunkt aller Zuverlässigkeitsstudien steht. Wenn Sie über qualitativ hochwertige Daten verfügen, können Sie diese selbstbewusst für effektive Interessenvertretung, aussagekräftige Forschung, strategische Planung und Managementbereitstellung verwenden.
Über die Autoren
Khalid A. Al-Jabr ist ein Spezialist für Zuverlässigkeitstechnik bei Saudi Aramco, der über mehr als 18 Jahre Industrieerfahrung mit Schwerpunkt auf Anlagenzuverlässigkeit und Herausforderungen verfügt. Er ist promovierter Ingenieur, Diplomingenieur und zertifizierter Fachmann für Ingenieurmanagement und Datenanalyse.
Qadeer Ahmed arbeitet als beratender Zuverlässigkeitsingenieur für Saudi Aramco und hat 18 Jahre Erfahrung in der Zuverlässigkeitstechnik. Als staatlich geprüfter Ingenieur hat er einen Ph.D. und ist ein Certified Maintenance &Reliability Professional (CMRP) und ein Six Sigma Black Belt.
Dahham Al-Anazi ist ein Leiter der Zuverlässigkeitstechnik für die Beratungsdienstleistungsabteilung von Saudi Aramco. Er verfügt über mehr als 25 Jahre technische Erfahrung und ist promovierter Maschinenbauer.
Internet der Dinge-Technologie
- Warum die Zukunft der Datensicherheit in der Cloud programmierbar ist
- Was mache ich mit den Daten?!
- Warum hervorragende Zuverlässigkeit für die Sicherheit unerlässlich ist
- Aussichten für die Entwicklung des industriellen IoT
- Das Potenzial für die Integration visueller Daten in das IoT
- Warum das Internet der Dinge künstliche Intelligenz braucht
- Die Voraussetzungen für den Erfolg der Industrial Data Science schaffen
- Trends treiben die Verarbeitung weiter an den Rand für KI
- Warum Automatisierung der einzige Weg in die Zukunft für die Fertigung ist
- DataOps:Die Zukunft der Gesundheitsautomatisierung