


PyTorch vs. TensorFlow:Eingehender Vergleich
Die zunehmende Popularität von Deep Learning hat zu einem gesunden Wettbewerb zwischen Deep-Learning-Frameworks geführt. PyTorch und TensorFlow sind zwei der beliebtesten Deep-Learning-Frameworks. Die Bibliotheken konkurrieren Kopf an Kopf um die Führung als primäres Deep-Learning-Tool.
TensorFlow ist älter und hatte deswegen immer einen Vorsprung, aber PyTorch hat in den letzten sechs Monaten aufgeholt. Es herrscht große Verwirrung darüber, bei der Auswahl eines Deep-Learning-Frameworks für ein Projekt die richtige Wahl zu treffen.
Dieser Artikel vergleicht PyTorch mit TensorFlow und bietet einen ausführlichen Vergleich der beiden Frameworks.
PyTorch vs. TensorFlow:Ein Überblick
Sowohl PyTorch als auch TensorFlow verfolgen, was ihre Konkurrenz tut. Es gibt jedoch noch einige Unterschiede zwischen den beiden Frameworks.
Hinweis: Diese Tabelle ist horizontal scrollbar.
| Bibliothek | PyTorch | TensorFlow 2.0 |
|---|---|---|
| Erstellt von | FAIR Lab (Facebook AI Research Lab) | Google Brain-Team |
| Basierend auf | Fackel | Theano |
| Produktion | Forschungsorientiert | Branchenorientiert |
| Visualisierung | Visdom | Tensorbrett |
| Bereitstellung | Fackelaufschlag (experimentell) | TensorFlow-Server |
| Mobile Bereitstellung | Ja (experimentell) | Ja |
| Geräteverwaltung | CUDA | Automatisiert |
| Grafikerstellung | Dynamischer und statischer Modus | Eifriger und statischer Modus |
| Lernkurve | Einfacher für Entwickler und Wissenschaftler | Einfacher für Projekte auf Branchenebene |
| U se Fälle | Facebook CheXNet Tesla Autopilot Über PYRO | Google Sinovation Unternehmungen PayPal China Mobil |
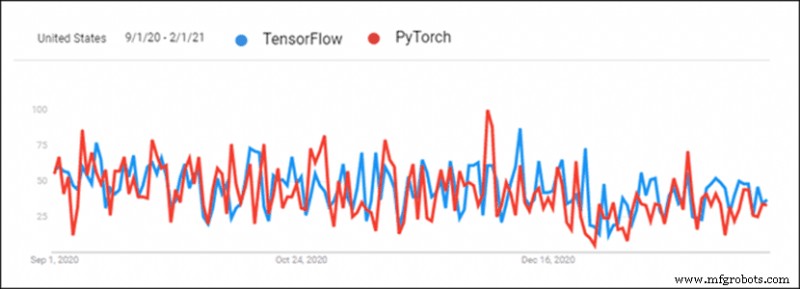
1. Visualisierung
Die Visualisierung per Hand braucht Zeit. PyTorch und TensorFlow verfügen beide über Tools zur schnellen visuellen Analyse. Dies erleichtert die Überprüfung des Schulungsprozesses. Die Visualisierung eignet sich auch hervorragend zum Präsentieren von Ergebnissen.
TensorFlow
Tensorboard wird zur Visualisierung von Daten verwendet. Die Benutzeroberfläche ist interaktiv und optisch ansprechend. Tensorboard bietet einen detaillierten Überblick über Metriken und Trainingsdaten. Die Daten lassen sich einfach exportieren und eignen sich hervorragend für Präsentationszwecke. Plugins machen Tensorboard auch für PyTorch verfügbar.
Tensorboard ist jedoch umständlich und kompliziert zu verwenden.
PyTorch
PyTorch verwendet Visdom zur Visualisierung. Die Benutzeroberfläche ist leicht und einfach zu bedienen. Visdom ist flexibel und anpassbar. Die direkte Unterstützung für PyTorch-Tensoren macht die Verwendung einfach.
Visdom mangelt es an Interaktivität und vielen wesentlichen Funktionen zur Datenübersicht.
2. Diagrammerstellung
Es gibt zwei Arten der Generierung neuronaler Netzwerkarchitekturen:
- Statische Diagramme – Fixed-Layer-Architektur. Die Karte wird zuerst generiert, dann werden Daten durch sie hindurchgeschoben.
- Dynamische Grafiken – Dynamische Schichtarchitektur. Die Karte wird implizit mit Datenüberladung definiert.
TensorFlow
TensorFlow verwendete von Anfang an statische Diagramme. Statische Diagramme ermöglichen die Verteilung auf mehrere Maschinen. Modelle werden unabhängig vom Code bereitgestellt. Die Verwendung statischer Graphen machte TensorFlow produktionsfreundlicher und flexibler bei der Arbeit mit neuen Architekturen.
TensorFlow fügte eine Funktion hinzu, die dynamische Graphen nachahmt, die als Eiferausführung bezeichnet werden. TensorFlow 2 wird standardmäßig mit Eager Execution ausgeführt. Die Generierung statischer Diagramme ist verfügbar, wenn die eifrige Ausführung deaktiviert wird.
PyTorch
PyTorch verfügte von Anfang an über dynamische Diagramme. Diese Funktion hat PyTorch in Konkurrenz zu TensorFlow gebracht.
Die Möglichkeit, Graphen unterwegs zu ändern, erwies sich als programmierer- und forscherfreundlicherer Ansatz zur Generierung neuronaler Netze. Strukturierte Daten und Größenvariationen in Daten sind mit dynamischen Diagrammen einfacher zu handhaben. PyTorch bietet auch statische Diagramme.
3. Lernkurve
Die Lernkurve hängt von der bisherigen Erfahrung und dem Endziel der Verwendung von Deep Learning ab.
TensorFlow
TensorFlow ist die anspruchsvollere Bibliothek. Keras-Funktionen erleichtern die Verwendung von TensorFlow. Im Allgemeinen ist TensorFlow für jemanden, der gerade erst mit Deep Learning beginnt, schwer zu verstehen.
Grund dafür ist die vielfältige Funktionalität von TensorFlow. Es gibt viele Funktionen zu erkunden und herauszufinden. Dies ist ablenkend und für einen Anfänger überflüssig.
PyTorch
PyTorch ist die leichter zu erlernende Bibliothek. Der Code ist einfacher zu experimentieren, wenn Python vertraut ist. Es gibt einen pythonischen Ansatz zum Erstellen eines neuronalen Netzwerks in PyTorch. Die Flexibilität von PyTorch bedeutet, dass der Code experimentierfreundlich ist.
PyTorch ist nicht so funktionsreich, aber alle wesentlichen Funktionen sind verfügbar. PyTorch ist einfacher zu starten und zu erlernen.
4. Bereitstellung
Die Bereitstellung ist ein Softwareentwicklungsschritt, der für Softwareentwicklungsteams wichtig ist. Durch die Softwarebereitstellung wird ein Programm oder eine Anwendung für die Verwendung durch Verbraucher verfügbar gemacht.
TensorFlow
TensorFlow verwendet TensorFlow Serving für die Modellbereitstellung. TensorFlow-Serving ist für Produktions- und Industrieumgebungen konzipiert. Die Bereitstellung ist flexibel und leistungsstark mit einer REST-Client-API. TensorFlow-Serving lässt sich gut in Docker und Kubernetes integrieren.
PyTorch
PyTorch hat kürzlich damit begonnen, das Problem der Bereitstellung anzugehen. Fackelaufschlag setzt PyTorch-Modelle ein. Es gibt eine RESTful-API für die Anwendungsintegration. Die PyTorch-API ist für den mobilen Einsatz erweiterbar. Fackelaufschlag lässt sich in Kubernetes integrieren.
5. Parallelität und verteiltes Training
Parallelität und verteiltes Training sind für Big Data unerlässlich. Die allgemeinen Metriken sind:
- Geschwindigkeitserhöhung – Verhältnis der Geschwindigkeit eines sequentiellen Modells (einzelne GPU) im Vergleich zur Geschwindigkeit des parallelen Modells (mehrere GPU).
- Durchsatz – Die maximale Anzahl von Bildern, die pro Zeiteinheit durch das Modell geleitet wurden.
- Skalierbarkeit – Wie das System mit zunehmender Arbeitslast umgeht.
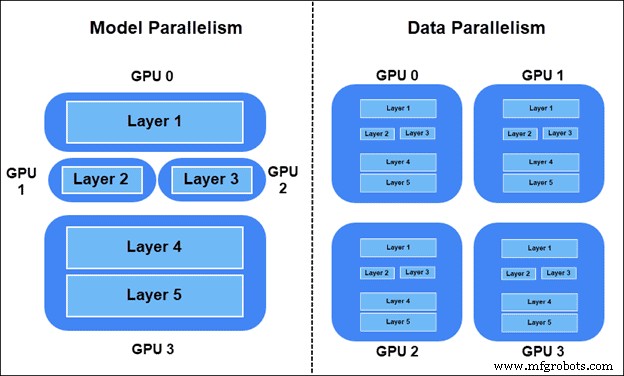
Es gibt zwei Möglichkeiten, das Trainingspensum zu verteilen:
- Modellparallelität – Schichten des Modells auf verschiedenen Geräten aufgeteilt. Teile des Diagramms werden gleichzeitig im Training verwendet.
- Datenparallelität – Alle Geräte haben eine Kopie des gesamten Modells. Jedes Gerät trainiert mit unterschiedlichen Datenproben. Bevorzugt wird das synchrone SGD-Verfahren (Stochastic Gradient Descent).
TensorFlow-Modellparallelität
Um einen Teil des Modells in einem bestimmten Gerät in TensorFlow zu platzieren, verwenden Sie tf.device .
Teilen Sie beispielsweise zwei lineare Ebenen auf zwei verschiedenen GPU-Geräten auf:
import tensorflow as tf
from tensorflow.keras import layers
with tf.device(‘GPU:0’):
layer1 = layers.Dense(16, input_dim=8)
with tf.device(‘GPU:1’):
layer2 = layers.Dense(4, input_dim=16) PyTorch-Modellparallelität
Verschieben Sie Teile des Modells mit nn.Module.to auf verschiedene Geräte in PyTorch Methode.
Verschieben Sie beispielsweise zwei lineare Layer auf zwei verschiedene GPUs:
import torch.nn as nn layer1 = nn.Linear(8,16).to(‘cuda:0’) layer2 = nn.Lienar(16,4).to(‘cuda:1’)
TensorFlow-Datenparallelität
Um synchrone SGD in TensorFlow durchzuführen, legen Sie die Verteilungsstrategie mit tf.distribute.MirroredStrategy() fest und umbrechen Sie die Modellinitialisierung:
import tensorflow as tf strategy = tf.distribute.MirroredStrategy() with strategy.scope(): model = … model.compile(...)
Nachdem Sie das Modell mit dem Wrapper kompiliert haben, trainieren Sie das Modell wie gewohnt.
PyTorch-Datenparallelität
Umschließen Sie das Modell für synchrone SGD in PyTorch in torch.nn.DistributedDataParallel nach der Modellinitialisierung und setzen Sie den Gerätenummernrang beginnend mit Null:
from torch.nn.parallel import DistributedDataParallel. model = ... model = model.to() ddp_model = DistributedDataParallel(model, device_ids=[])
6. Geräteverwaltung
Beim Verwalten von Geräten kommt es zu massiven Leistungsänderungen. Sowohl PyTorch als auch TensorFlow wenden neuronale Netze gut an, aber die Ausführung ist unterschiedlich.
TensorFlow
TensorFlow wechselt automatisch zur GPU-Nutzung, wenn eine GPU verfügbar ist. Es gibt Kontrolle über GPUs und wie auf sie zugegriffen wird. Die GPU-Beschleunigung ist automatisiert. Das bedeutet, dass es keine Kontrolle über die Speichernutzung gibt.
PyTorch
PyTorch verwendet CUDA, um die Nutzung von GPU oder CPU anzugeben. Das Modell läuft nicht ohne CUDA-Spezifikationen für GPU- und CPU-Nutzung. Die GPU-Nutzung ist nicht automatisiert, was bedeutet, dass die Ressourcennutzung besser kontrolliert werden kann. PyTorch verbessert den Trainingsprozess durch GPU-Steuerung.
7. Anwendungsfälle für beide Deep-Learning-Plattformen
TensorFlow und PyTorch wurden zunächst in ihren jeweiligen Unternehmen eingesetzt. Seitdem es Open Source ist, gibt es auch viele Anwendungsfälle außerhalb von Google und Facebook.
TensorFlow
Google-Forscher des Google Brain Teams verwendeten TensorFlow erstmals für Google-Forschungsprojekte. Google verwendet TensorFlow für:
- Suchergebnisse und automatische Vervollständigung.
- Speech-to-Text und Sprachtechnologie.
- Bilderkennung und -klassifizierung.
- Maschinelle Übersetzungssysteme.
- Spamerkennung für Gmail.
Auch außerhalb von Google gibt es viele Anwendungsfälle. Zum Beispiel:
- Sinovation Ventures – Klassifikation und Segmentierung von Krankheiten anhand von Netzhautbildern.
- PayPal – Betrugserkennung mit Deep Transfer Learning und generativer Modellierung.
- China Mobile – Deep-Learning-Systeme zur Problemerkennung in Netzwerken, automatische Vorhersage von Umstellungszeitfenstern und Überprüfung von Betriebsprotokollen.
PyTorch
PyTorch wurde erstmals bei Facebook vom Facebook AI Researchers Lab (FAIR) eingesetzt. Facebook verwendet PyTorch für:
- Gesichtserkennung und Objekterkennung.
- Spam-Filterung und Erkennung gefälschter Nachrichten.
- Newsfeed-Automatisierung und System zum Vorschlagen von Freunden.
- Spracherkennung.
- Maschinelle Übersetzungssysteme.
PyTorch ist Open Source. Mittlerweile gibt es viele Anwendungsfälle außerhalb von Facebook, wie zum Beispiel:
- CheXNet – Pneumonie-Wahrscheinlichkeits-Scoring und Thorax-Röntgen-Heatmap unter Verwendung von Convolutional Neural Networks.
- Tesla-Autopilot – Echtzeit-Computer-Vision-Multitasking für autonome Fahrzeuge.
- Uber AI Labs PYRO – Probabilistische Programmiersprache für tiefe probabilistische Modellierung. Vorhersage und Optimierung der Abstimmung von Kunden mit Fahrern, optimalen Routen und intelligenten Fahrzeugen der nächsten Generation.
Sollten Sie PyTorch oder TensorFlow verwenden?
PyTorch ist die beliebteste Option unter Programmierern und wissenschaftlichen Forschern. Die wissenschaftliche Gemeinschaft bevorzugt PyTorch, wenn man die Anzahl der Zitate betrachtet. Mit den neuesten Bereitstellungs- und Produktionsfunktionen ist PyTorch eine großartige Option, wenn Sie von der Forschung zur Produktion übergehen.
Organisationen und Startups verwenden im Allgemeinen TensorFlow. Die Bereitstellungs- und Produktionsfunktionen verleihen TensorFlow einen guten Ruf in Unternehmensanwendungsfällen. Die Visualisierung mit Tensorboard zeigt Kunden auch eine elegante Präsentation.
PyTorch und TensorFlow sind leistungsstarke Deep-Learning-Bibliotheken, die sich intensiv weiterentwickeln. Heute gibt es mehr Ähnlichkeiten als Unterschiede zwischen den beiden und der Wechsel von einem zum anderen ist ein nahtloser Prozess.
Cloud Computing
- AWS und Azure:Übersicht und Vergleich der Dienste
- IoT in der Fertigung:Ein genauer Blick
- GPS vs. RFID:Ein Vergleich von Technologien zur Standortbestimmung von Vermögenswerten
- ZigBee vs. XBee:Ein leicht verständlicher Vergleich
- Vergleich einer CNC-Holzdrehmaschine mit einer herkömmlichen Holzdrehmaschine
- Kapazitiver Spannungsteiler:Eine ausführliche Anleitung
- Vergleich von 3D-Technologien:SLA vs. FDM
- Ein eingehender Blick auf die Zentrifugalwasserpumpe
- Honen und Läppen im Vergleich
- Förderband-Vergleich im Bergbau