


Wie man einen Algorithmus trainiert, um frühzeitige Erblindung zu erkennen und zu verhindern
Ein tragbares medizinisches Gerät, das verschiedene Stadien der diabetischen Retinopathie genau erkennen könnte, ohne dass eine Internetverbindung erforderlich wäre, würde die Zahl der Erblindungsfälle aufgrund von Retinopathie weltweit erheblich reduzieren. Mit eingebettetem maschinellem Lernen ist es jetzt möglich, Algorithmen zu entwickeln, die direkt auf batteriebetriebenen medizinischen Geräten laufen und eine Erkennung oder Diagnose durchführen können. In diesem Artikel bieten wir eine exemplarische Vorgehensweise für die Schritte, die zum schnellen Trainieren eines Algorithmus erforderlich sind, um diese Fähigkeit mithilfe einer Softwareplattform von Edge Impulse bereitzustellen.
Die diabetische Retinopathie ist eine Erkrankung, bei der die Blutgefäße im Gewebe am Augenhintergrund geschädigt werden. Es kann bei Personen auftreten, die Diabetiker sind und deren Blutzucker schlecht eingestellt ist. In extremen chronischen Fällen kann die diabetische Retinopathie zur Erblindung führen.
Mehr als zwei von fünf Amerikanern mit Diabetes haben irgendeine Form von diabetischer Retinopathie. Das macht es entscheidend, es frühzeitig zu erkennen, wann Lebensstil oder medizinische Eingriffe durchgeführt werden können. In ländlichen Gebieten auf der ganzen Welt, in denen der Zugang zu Sehhilfen eingeschränkt ist, sind die Stadien der Retinopathie noch schwerer zu erkennen, bevor ein Fall schwerwiegend wird. Mit der Erkennung der diabetischen Retinopathie haben wir uns zum Ziel gesetzt, öffentlich verfügbare medizinische Daten zu verwenden und ein maschinelles Lernmodell in Edge Impulse zu trainieren, das Inferenz direkt auf einem Edge-Gerät ausführen kann. Der Algorithmus wäre idealerweise in der Lage, den Schweregrad der diabetischen Retinopathie zwischen Bildern von Augen, die von einer Netzhautkamera aufgenommen wurden, zu beurteilen. Den Datensatz, den wir für dieses Projekt verwendet haben, finden Sie hier.
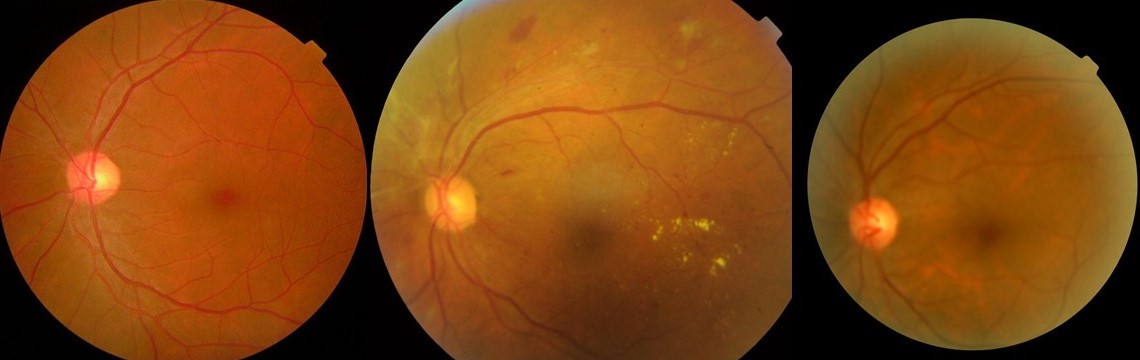
Für diesen Algorithmus haben wir die Klassen in fünf verschiedene Datensätze unterteilt:
- Keine diabetische Retinopathie (keine DR)
- Leichte DR
- Mäßige DR
- Schwere DR
- Proliferative DR
Wie bei vielen öffentlich verfügbaren Datensätzen mussten einige Datenbereinigungen und -kennzeichnungen vorgenommen werden.
Um die Patientenidentität zu schützen, erhielt jedes Bild im Datensatz einfach einen id_code und eine Diagnose von 0 bis 5, wobei 0 der niedrigste Schweregrad von No DR und 5 der schlechteste oder Proliferative DR ist.
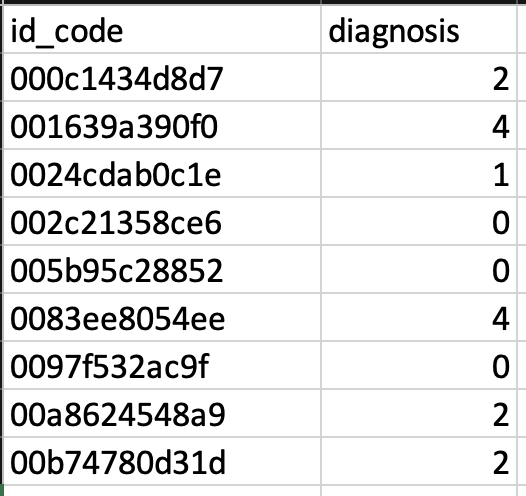
Um die Daten in Edge Impulse aufzunehmen, musste eine gewisse Partitionierung der Bilder erfolgen. Angesichts der einfachen Art und Weise, wie die Daten aufgeteilt wurden, beschloss ich, ein VBA-Skript zu schreiben, um den Bild-ID-Code aus Excel zu lesen, das zugehörige Bild zu übernehmen und es in den entsprechenden Ordner zu legen. Das Skript zum Verschieben dieser Dateien ist hier verlinkt. Für diejenigen mit besseren Python- oder anderen Skriptsprachenkenntnissen gibt es viele Möglichkeiten, dies zu tun, die möglicherweise noch einfacher sind.
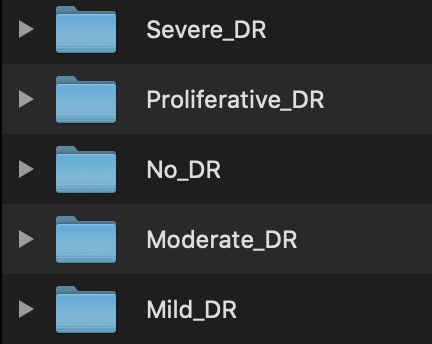
Edge Impulse verfügt über andere Datenaufnahmefunktionen wie die Cloud-Data-Bucket-Integration oder die Datenerfassung von Geräten, aber das Hochladen von Daten war die Methode, die ich hier verwendet habe. Mit der Daten-Upload-Option konnte ich in meinen 5 verschiedenen Klassen eine Serie von fünf Uploads einbringen. Bei jedem Upload habe ich die Daten als eine der 5 Klassen gekennzeichnet und die zugehörigen Bilder in jedem Ordner hochgeladen.
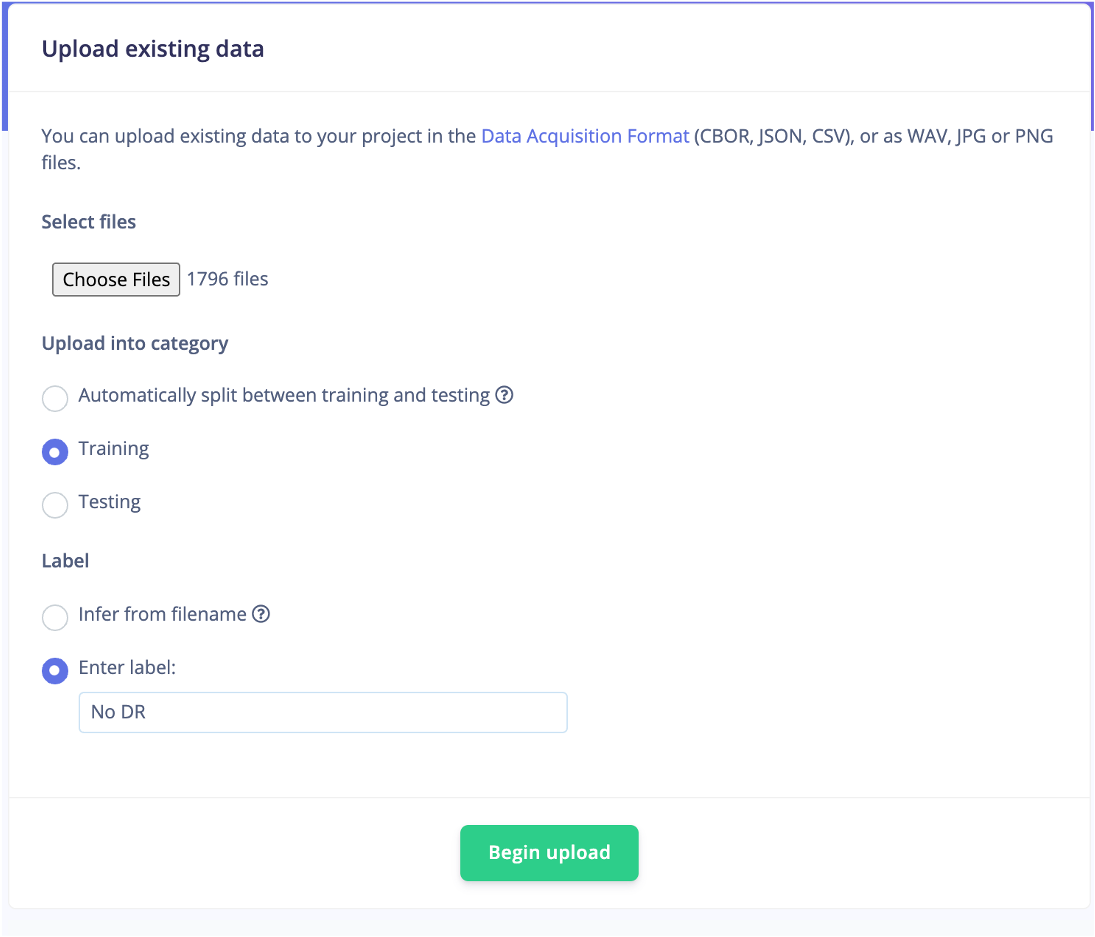
Edge Impulse hat die Möglichkeit, Daten automatisch in Trainings- oder Testdaten mit einer 80/20-Aufteilung aufzuteilen. Ich habe dem Testdatensatz jedoch manuell etwa 500 Bilder aus den verschiedenen Klassen hinzugefügt.
Als nächstes war es an der Zeit, mein Modell einzurichten und den Signalverarbeitungsblock und den neuronalen Netzwerkblock für dieses Modell auszuwählen. Für dieses Modell habe ich den Bildblock in einen Transfer-Lernblock eingespeist, mit dem Ziel, zwischen fünf verschiedenen Klassen zu unterscheiden.
Von hier aus ging ich, um das neuronale Netz zu trainieren. Beim Herumspielen mit den Einstellungen des neuronalen Netzes lag die beste Genauigkeit, die ich erhielt, bei etwa 74 %. Nicht schlecht, aber bei einigen Randfällen blieb das Modell stecken. Zum Beispiel wurde eine schwere DR manchmal als leichte DR klassifiziert. Das Modell war im Verlauf der DR nicht sehr genau, wie Sie im Screenshot unten sehen können.
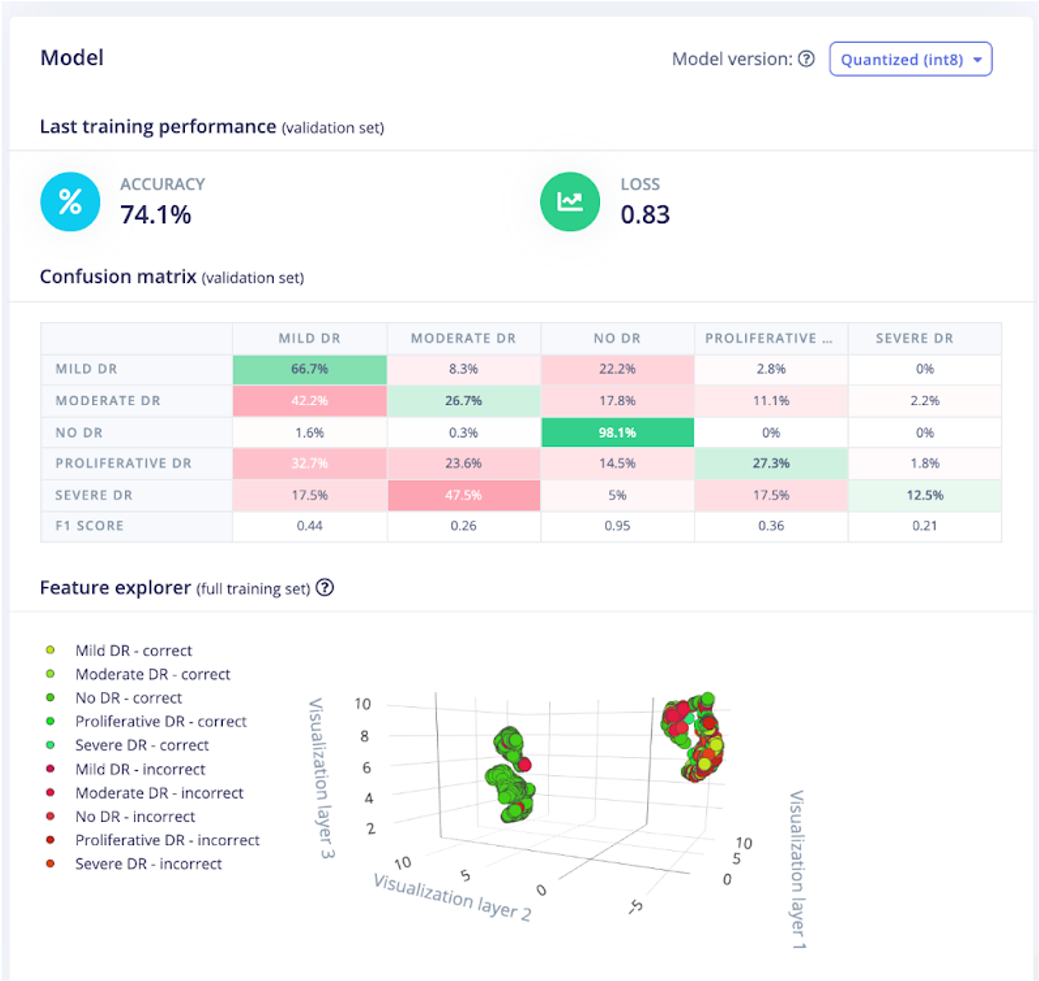
Dies brachte mich dazu, über die realen Anwendungen eines solchen Projekts nachzudenken und ob diese Genauigkeit akzeptabel wäre. Im Idealfall könnte eine Art tragbare Netzhautkamera (in einer Umgebung mit geringer drahtloser Konnektivität) einen solchen Algorithmus auf dem Gerät selbst ausführen. Wenn das Bild aufgenommen, verarbeitet und ein Ergebnis ausgegeben wird, könnte die Person, die den Sehtest durchführt, dem Patienten zu diesem Zeitpunkt mitteilen, dass er je nach Ergebnis weitere medizinische Hilfe oder Intervention aufsuchen muss.
Für diese Anwendung ist es wichtiger, eine DR in allen Stadien zu erkennen, damit der Patient entweder eine vorbeugende Behandlung beginnen oder in schwereren Fällen sofort ärztliche Hilfe aufsuchen kann. Angesichts dieses Anwendungsfalls erfüllt das Modell seine potenzielle Anwendung tatsächlich relativ gut.
Ganz spontan gibt es einige Änderungen oder Verbesserungen, die ich am Modell vornehmen könnte, um die resultierende Ausgabe in Bezug auf die Diagnose des Schweregrads von DR genauer zu machen:
- Mehr Daten sind immer besser. Angesichts dieses begrenzten Datensatzes wäre jedoch eine weitere Datenerhebung erforderlich.
- Eine Idee könnte sein, Klassen zu kombinieren, indem man eine milde – mittlere Klasse und eine proliferative – schwere Klasse bildet. Ich frage mich, ob dies dem Algorithmus helfen könnte, angesichts der Ähnlichkeiten zwischen bestimmten Fällen von leichter und mittelschwerer DR, die jetzt alle in dieselbe Gruppe fallen würden, besser zu klassifizieren.
Spielen Sie mit der Anzahl der Schichten innerhalb des neuronalen Netzes (NN) sowie mit den Ausfällen herum.

Aus Bereitstellungssicht hatte dieses trainierte Modell einen größeren Speicherbedarf und benötigte schätzungsweise 306 KB Flash und 236 KB RAM. Abhängig von dem Gerät, auf dem die Inferenz ausgeführt wurde, betrug die Zeit, die benötigt wurde, um ein Inferenzergebnis zurückzugeben, zwischen 0,8 Sekunden und 6 Sekunden, wenn ein Benchmarking auf einem Cortex-M4 bei 80 MHz oder Cortex-M7 bei 216 MHz durchgeführt wurde. Angesichts der Tatsache, dass dieses Endprodukt jedoch Bilder aufnehmen muss, gehe ich davon aus, dass so etwas wie die Verarbeitungsfähigkeiten des Cortex-M7 oder höher benötigt werden.
Zusammenfassend konnten wir mit einem Open-Source-Datensatz ein relativ gut funktionierendes Machine-Learning-Modell zur Erkennung verschiedener Formen der diabetischen Retinopathie (DR) trainieren. Das Endziel wäre, Modelle wie dieses direkt auf dem eingebetteten Mikrocontroller oder Linux-Gerät bereitzustellen und mehr medizinische Geräte wie das unten aufgeführte Inferenz am Edge ausführen zu lassen. Dies eröffnet neue Möglichkeiten für Gesundheitsdienste, indem medizinische Technologie bereitgestellt wird, die in ländlichen Gebieten ohne drahtlose Konnektivität verwendet werden kann, um Tests für Bevölkerungsgruppen bereitzustellen, die nur einen geringen Zugang zur Gesundheitsversorgung haben.
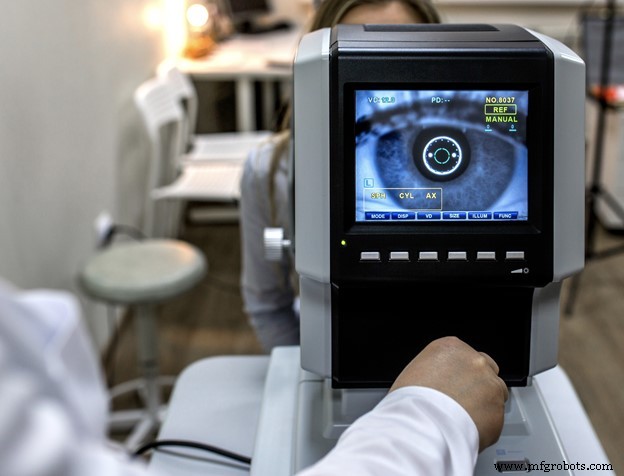
Es gibt in der Tat eine gute Gelegenheit für den Einsatz von Embedded Machine Learning (ML) in medizinischen Geräten. Weitere Details zu diesem Projekt, einschließlich weiterer Verbesserungspotenziale, finden Sie hier.
Eingebettet
- Wie wurde Titan vom Menschen entdeckt und genutzt?
- Cloud und wie sie die IT-Welt verändert
- Vier Arten von Cyberangriffen und wie man sie verhindert
- Wie man allgemeine Probleme mit schweren Maschinen und Ausrüstungen vermeidet
- Was ist Schweißporosität und wie kann man sie verhindern?
- Was ist Rost und wie kann man Rost verhindern? Eine vollständige Anleitung
- Die häufigsten Ursachen für Maschinenausfälle und wie man sie vermeidet
- Was ist Interoperabilität und wie kann mein Unternehmen sie erreichen?
- Fallstricke beim Maschinenschutz und wie man sie vermeidet
- Lecks erkennen und beheben