


Forscher zeigen KI-Chip mit reduziertem Präzisionstraining
Auf der ISSCC präsentierte IBM Research einen Testchip, der die Hardware-Manifestation seiner jahrelangen Arbeit an niedrigpräzisen KI-Trainings- und Inferenzalgorithmen darstellt. Der 7-nm-Chip unterstützt 16-Bit- und 8-Bit-Training sowie 4-Bit- und 2-Bit-Inferenz (32-Bit- oder 16-Bit-Training und 8-Bit-Inferenz sind heute der Industriestandard).
Eine Reduzierung der Präzision kann den Rechen- und Leistungsbedarf für die KI-Berechnung reduzieren, aber IBM hat einige andere Architekturtricks im Ärmel, die ebenfalls zur Effizienz beitragen. Die Herausforderung besteht darin, die Genauigkeit zu reduzieren, ohne das Ergebnis der Berechnung zu beeinträchtigen, woran IBM auf Algorithmusebene seit einigen Jahren arbeitet.
Das AI Hardware Center von IBM wurde 2019 gegründet, um das Ziel des Unternehmens zu unterstützen, die KI-Rechenleistung um das 2,5-fache pro Jahr zu steigern, mit einem ehrgeizigen Gesamtziel einer 1000-fachen Verbesserung der Leistungseffizienz (FLOPS/W) bis 2029. Seither sind ehrgeizige Leistungs- und Energieziele erforderlich Die Größe von KI-Modellen und der Rechenaufwand, der für deren Training erforderlich ist, nehmen schnell zu. Insbesondere Modelle der Natural Language Processing (NLP) sind heute Ungetüme mit Billionen Parametern, und der CO2-Fußabdruck, der mit dem Training dieser Bestien einhergeht, ist nicht unbemerkt geblieben.
Dieser neueste Testchip von IBM Research zeigt die Fortschritte, die IBM bisher gemacht hat. Für 8-Bit-Training ist der 4-Kern-Chip zu 25,6 TFLOPS fähig, während die Inferenzleistung 102,4 TOPS für 4-Bit-Ganzzahlberechnungen beträgt (diese Zahlen gelten für eine Taktfrequenz von 1,6 GHz und eine Versorgungsspannung von 0,75 V). Die Reduzierung der Taktfrequenz auf 1 GHz und der Versorgungsspannung auf 0,55 V erhöht die Energieeffizienz auf 3,5 TFLOPS/W (FP8) oder 16,5 TOPS/W (INT4).
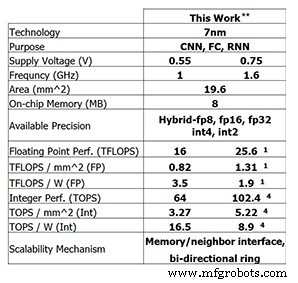
Leistung des Testchips von IBM Research (Bild:IBM Research) **Gemeldete Leistung bei 0% Sparsity. (1) RP8. (4) INT4.
Training mit geringer Präzision
Diese Leistung baut auf jahrelanger algorithmischer Arbeit an niedrigpräzisen Trainings- und Inferenztechniken auf. Der Chip unterstützt als erster IBMs spezielles 8-Bit-Hybrid-Gleitkommaformat (Hybrid FP8), das erstmals auf der NeurIPS 2019 vorgestellt wurde. Dieses neue Format wurde speziell entwickelt, um 8-Bit-Training zu ermöglichen, wodurch der Rechenaufwand für 16-Bit halbiert wird Training, ohne die Ergebnisse negativ zu beeinflussen (lesen Sie hier mehr über Zahlenformate für die KI-Verarbeitung).
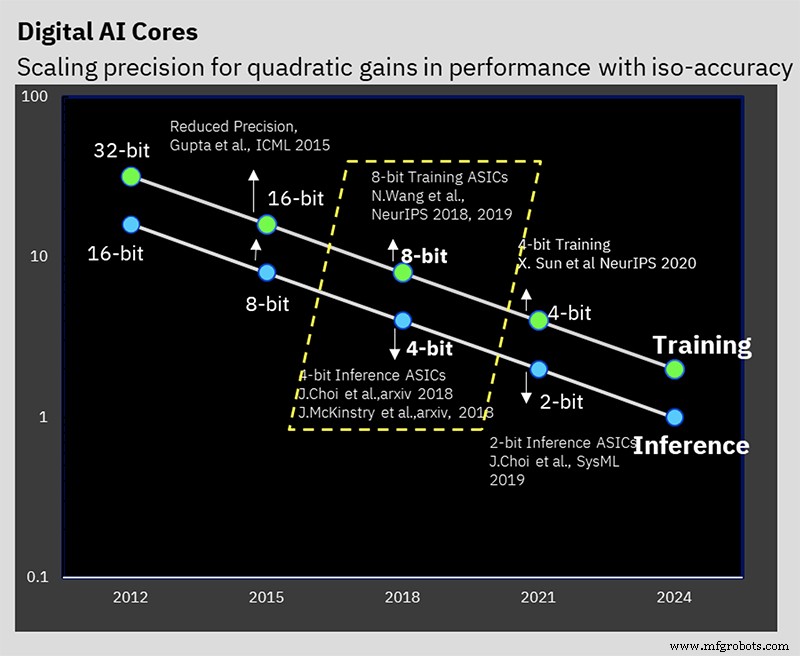
IBM Research hat an der Lösung des Problems der Aufrechterhaltung der Genauigkeit bei gleichzeitiger Reduzierung der Präzision gearbeitet (Bild:IBM)
„Was wir im Laufe der Jahre in unseren verschiedenen Studien gelernt haben, ist, dass Training mit niedriger Präzision sehr anspruchsvoll ist, aber Sie können 8-Bit-Training durchführen, wenn Sie die richtigen Zahlenformate haben“, Kailash Gopalakrishnan, IBM Fellow und Senior Manager für Beschleunigerarchitekturen und maschinelles Lernen bei IBM Research sagte EE Times . „Das Verständnis der richtigen numerischen Formate und deren Zuordnung zu den richtigen Tensoren beim Deep Learning war ein entscheidender Teil davon.“
Hybrid FP8 ist eigentlich eine Kombination aus zwei verschiedenen Formaten. Ein Format wird für Gewichtungen und Aktivierungen im Vorwärtsdurchlauf von Deep Learning verwendet, und ein anderes wird im Rückwärtsdurchlauf verwendet. Inferenz verwendet nur den Vorwärtspass, während das Training sowohl Vorwärts- als auch Rückwärtsphasen erfordert.
„Was wir gelernt haben, ist, dass Sie mehr Genauigkeit und Präzision in Bezug auf die Darstellung von Gewichtungen und Aktivierungen im Vorwärtsgang von Deep Learning benötigen“, sagte Gopalakrishnan. „Auf der anderen Seite [der Rückwärtsphase] haben die Gradienten einen hohen Dynamikbereich, und hier erkennen wir die Notwendigkeit eines [größeren] Exponenten … dies ist der Kompromiss zwischen den Anforderungen einiger Tensoren im Deep Learning mehr Genauigkeit, höhere Wiedergabetreue, während andere Tensoren einen breiteren Dynamikbereich benötigen. Dies ist die Entstehung des hybriden FP8-Formats, das wir Ende 2019 vorgestellt haben und das nun in Hardware umgesetzt wurde.“
Die Arbeit von IBM ergab, dass der beste Weg, die 8 Bits zwischen Exponent und Mantisse aufzuteilen, 1-4-3 (ein Vorzeichenbit, ein Vier-Bit-Exponent und eine Drei-Bit-Mantisse) für die Vorwärtsphase ist, mit einer Alternative 5- Bit-Exponenten-Version für die Rückwärtsphase, die einen Dynamikbereich von 2 32 . ergibt . Hybrid-FP8-fähige Hardware unterstützt diese beiden Formate.
Hierarchische Akkumulation
Eine Innovation, die die Forscher als "hierarchische Akkumulation" bezeichnen, ermöglicht es, dass die Akkumulation neben den Gewichten und Aktivierungen in der Präzision reduziert wird. Typische FP16-Trainingsschemata akkumulieren in 32-Bit-Arithmetik, um die Genauigkeit zu erhalten, aber das 8-Bit-Training von IBM kann in FP16 akkumulieren. Eine Beibehaltung der Akkumulation im RP32 hätte die Vorteile eines Wechsels zum RP8 von vornherein eingeschränkt.
„Was bei der Gleitkomma-Arithmetik passiert, ist, dass die Genauigkeit der Gleitkomma-Darstellung selbst die Genauigkeit Ihrer Summe“, erklärte Gopalakrishnan. „Wir kamen zu dem Schluss, dass dies nicht der beste Weg ist, die Addition nacheinander durchzuführen, sondern wir neigen dazu, die lange Akkumulation in Gruppen aufzuteilen, die wir Chunks nennen. Und dann addieren wir die Chunks zueinander, und das minimiert die Wahrscheinlichkeit, dass solche Fehler auftreten.“
Inferenz mit geringer Genauigkeit
Die meisten KI-Inferenz verwendet heute das 8-Bit-Integer-Format (INT8). Die Arbeit von IBM hat gezeigt, dass 4-Bit-Ganzzahlen der Stand der Technik sind, wenn es darum geht, wie niedrig die Genauigkeit sein kann, ohne dass eine signifikante Vorhersagegenauigkeit verloren geht. Nach der Quantisierung (dem Prozess der Umwandlung des Modells in Zahlen mit niedrigerer Genauigkeit) wird ein quantisierungsbewusstes Training durchgeführt. Dies ist effektiv ein Neutrainingsschema, das alle Fehler abschwächt, die aus der Quantisierung resultieren. Dieses erneute Training kann den Genauigkeitsverlust minimieren; IBM kann „leicht“ mit einem halben Prozent Verlust an Genauigkeit in 4-Bit-Ganzzahlarithmetik quantisieren, was laut Gopalakrishnan für die meisten Anwendungen „sehr akzeptabel“ ist.
On-Chip-Ring
Abgesehen von der Konzentration auf niedrige Präzisionsarithmetik gibt es andere Hardware-Innovationen, die zur Effizienz des Chips beitragen.
Eine davon ist die On-Chip-Ringkommunikation, ein für Deep Learning optimiertes Network-on-Chip, das es jedem der Kerne ermöglicht, Daten per Multicast an die anderen zu senden. Multicast-Kommunikation ist für Deep Learning von entscheidender Bedeutung, da die Kerne Gewichtungen teilen und Ergebnisse an andere Kerne kommunizieren müssen. Es ermöglicht auch die Übertragung von Daten, die aus dem Off-Chip-Speicher geladen wurden, an mehrere Kerne. Dadurch wird die Anzahl der Lesevorgänge des Speichers und die insgesamt gesendete Datenmenge reduziert, wodurch die erforderliche Speicherbandbreite minimiert wird.
„Wir haben festgestellt, dass wir die Kerne schneller betreiben können als die Ringe, weil die Ringe viele lange Drähte beinhalten“, sagte Ankur Agrawal, Forschungsmitarbeiter für maschinelles Lernen und Beschleunigerarchitekturen bei IBM Research. „Wir haben die Betriebsfrequenz des Rings von der Betriebsfrequenz der Kerne entkoppelt … das ermöglicht uns, die Leistung des Rings in Bezug auf die Kerne unabhängig zu optimieren.“
Energieverwaltung
Eine weitere Innovation von IBM war die Einführung eines Frequenzskalierungsschemas zur Maximierung der Effizienz.
„Deep-Learning-Workloads sind etwas Besonderes, da Sie bereits während der Kompilierungsphase wissen, auf welche Berechnungsphasen Sie bei dieser sehr großen Workload stoßen werden“, sagte Agrawal. „Wir können einige Voreinstellungen vornehmen, um herauszufinden, wie das Leistungsprofil in verschiedenen Teilen der Berechnung aussehen wird.“
Das Leistungsprofil von Deep Learning weist normalerweise große Spitzen (für rechenintensive Operationen wie Faltung) und Tiefs (vielleicht für Aktivierungsfunktionen) auf.
Das Schema von IBM legt die anfängliche Betriebsspannung und -frequenz des Chips ziemlich aggressiv fest, sodass der Chip selbst bei den niedrigsten Leistungsmodi fast an der Grenze seines Leistungsbereichs liegt. Wenn dann mehr Leistung benötigt wird, wird die Betriebsfrequenz reduziert.
„Das Nettoergebnis ist ein Chip, der während der gesamten Berechnung fast mit der Spitzenleistung arbeitet, sogar während der verschiedenen Phasen“, erklärte Agrawal. „Insgesamt können Sie alles schneller erledigen, wenn Sie diese Phasen mit geringem Stromverbrauch nicht haben. Sie haben jeden Rückgang des Stromverbrauchs in Leistungssteigerungen umgesetzt, indem Sie Ihren Stromverbrauch für alle Betriebsphasen fast auf dem Spitzenstromverbrauch gehalten haben.“
Die Spannungsskalierung wird nicht verwendet, da dies im laufenden Betrieb schwieriger ist. Die Zeit, die benötigt wird, um sich bei der neuen Spannung zu stabilisieren, ist für Deep-Learning-Berechnungen zu lang. IBM entscheidet sich daher im Allgemeinen dafür, den Chip bei der niedrigstmöglichen Versorgungsspannung für diesen Prozessknoten zu betreiben.
Testchip
Der Testchip von IBM hat vier Kerne, zum Teil, um das Testen all der verschiedenen Funktionen zu ermöglichen. Gopalakrishnan beschrieb, wie die Kerngröße bewusst optimal gewählt wird; Eine Architektur mit Tausenden winziger Kerne ist komplex zu verbinden, während das Problem zwischen großen Kernen auch schwierig aufzuteilen sein kann. Dieser Zwischenkern wurde entwickelt, um die Anforderungen von IBM und seinen Partnern im AI Hardware Center zu erfüllen, und findet einen optimalen Platz in Bezug auf die Größe.
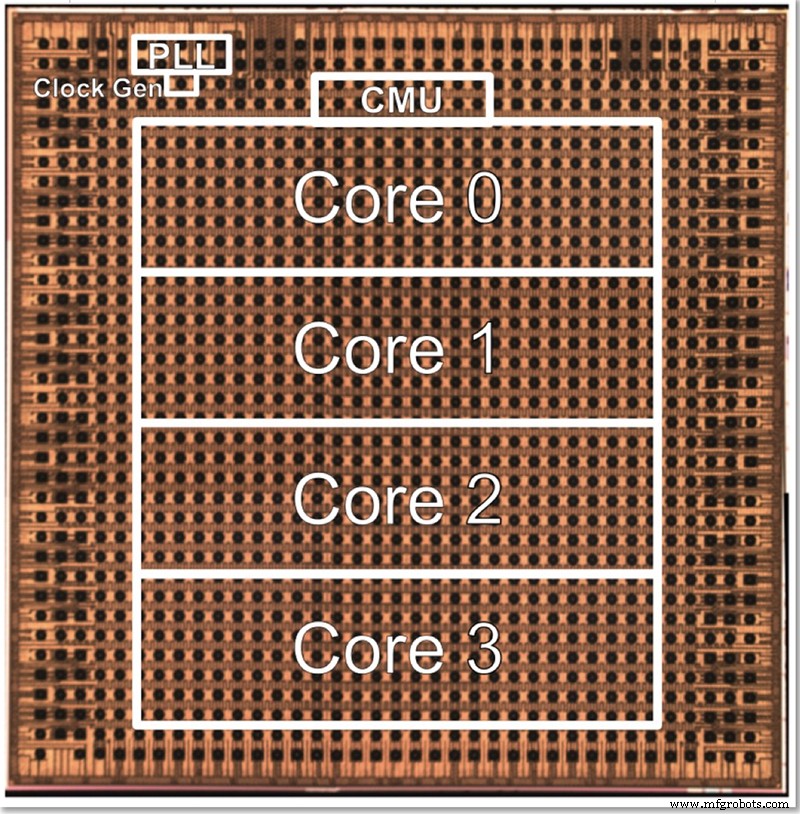
Ein Die-Foto für IBMs 4-Kern-Testchip mit niedriger Präzision (Bild:IBM)
Die Architektur kann nach oben oder unten skaliert werden, indem die Anzahl der Kerne geändert wird. Schließlich stellt sich Gopalakrishnan vor, dass 1-2-Core-Chips für Edge-Geräte geeignet wären, während 32-64-Core-Chips im Rechenzentrum funktionieren könnten. Die Tatsache, dass es mehrere Formate unterstützt (FP16, hybrides FP8, INT4 und INT2), macht es auch für die meisten Anwendungen vielseitig genug, sagte er.
„Verschiedene [Anwendungs-]Domänen hätten unterschiedliche Anforderungen an Energieeffizienz und Präzision usw.“, sagte er. „Unser Schweizer Taschenmesser der Präzision, jedes einzeln optimiert, ermöglicht es uns, diese Kerne in verschiedenen Bereichen zu zielen, ohne dabei zwangsläufig auf Energieeffizienz zu verzichten.“
Neben der Hardware hat IBM Research auch einen Tool-Stack („Deep Tools“) entwickelt, dessen Compiler eine hohe Auslastung des Chips (60-90 %) ermöglicht.
EE-Zeiten “ Ein früheres Interview mit IBM Research ergab, dass auf dieser Architektur basierende KI-Trainings- und Inferenzchips mit niedriger Präzision in etwa zwei Jahren auf den Markt kommen sollten.
>> Dieser Artikel wurde ursprünglich veröffentlicht am unsere Schwesterseite EE Times.
Verwandte Inhalte:
- KI-Chips behalten die Genauigkeit mit Modellreduktion bei
- KI-Modelle am Edge trainieren
- Das Rennen um die KI am Rand läuft
- Edge AI fordert die Speichertechnologie heraus
- Ingenieurgruppe versucht, 1-mW-KI an den Rand zu bringen
- Neurale Netzwerkanwendung für kleine Aufgaben
- KI-IC-Forschung untersucht alternative Architekturen
Für mehr Embedded, abonnieren Sie den wöchentlichen E-Mail-Newsletter von Embedded.
Eingebettet
- Entwerfen mit Bluetooth Mesh:Chip oder Modul?
- Forscher bauen winzige Authentifizierungs-ID-Tags
- Umgang mit weniger Wartungspersonal
- Die Rockwell-Allianz mit dem College in Minnesota erweitert den Zugang zu Automatisierungsschulungen
- Forscher zeigen, wie man die Sicherheitslücken von Bluetooth Classic ausnutzt
- Wie IBM Watson jedes andere Unternehmen mit KI unterstützt
- Erhöhen Sie Ihre Marketingbemühungen, um mit Agenturpräzision zu arbeiten
- Erhöhen Sie Ihre Marketingbemühungen, um mit Agenturpräzision zu arbeiten
- IBM:Proaktive Gewährleistung von Zuverlässigkeit und Sicherheit mit EAM
- Bau überlegener Hydrauliksysteme mit Präzisionsbearbeitung