


Wie viele versteckte Schichten und versteckte Knoten benötigt ein neuronales Netzwerk?
Dieser Artikel enthält Richtlinien zum Konfigurieren des verborgenen Teils eines mehrschichtigen Perceptrons.
Bisher haben wir in dieser Serie über neuronale Netze Perceptron-NNs, Multilayer-NNs und die Entwicklung solcher NNs mit Python besprochen. Bevor wir weiter diskutieren, wie viele versteckte Ebenen und Knoten Sie verwenden können, sollten Sie sich die folgende Reihe ansehen.
- Wie man eine Klassifikation mit einem neuronalen Netzwerk durchführt:Was ist das Perzeptron?
- So verwenden Sie ein einfaches Beispiel für ein neuronales Perceptron-Netzwerk zum Klassifizieren von Daten
- Wie man ein grundlegendes neuronales Perceptron-Netzwerk trainiert
- Einfaches neuronales Netzwerk-Training verstehen
- Eine Einführung in die Trainingstheorie für neuronale Netze
- Lernrate in neuronalen Netzen verstehen
- Fortgeschrittenes maschinelles Lernen mit dem mehrschichtigen Perzeptron
- Die Sigmoid-Aktivierungsfunktion:Aktivierung in mehrschichtigen neuronalen Perzeptronnetzwerken
- Wie man ein mehrschichtiges neuronales Perceptron-Netzwerk trainiert
- Verstehen von Trainingsformeln und Backpropagation für mehrschichtige Perzeptronen
- Neurale Netzwerkarchitektur für eine Python-Implementierung
- So erstellen Sie ein mehrschichtiges neuronales Perceptron-Netzwerk in Python
- Signalverarbeitung mit neuronalen Netzen:Validierung im neuronalen Netzdesign
- Trainings-Datasets für neuronale Netze:So trainieren und validieren Sie ein neuronales Python-Netz
- Wie viele versteckte Schichten und versteckte Knoten benötigt ein neuronales Netzwerk?
Zusammenfassung mit versteckten Ebenen
Sehen wir uns zunächst einige wichtige Punkte zu versteckten Knoten in neuronalen Netzwerken an.
- Perzeptrone, die nur aus Eingabe- und Ausgabeknoten bestehen (sogenannte einschichtige Perzeptrone) sind nicht sehr nützlich, da sie die komplexen Eingabe-Ausgabe-Beziehungen, die viele Arten von realen Phänomenen charakterisieren, nicht annähern können. Genauer gesagt sind einschichtige Perzeptrone auf linear trennbar beschränkt Probleme; wie wir in Teil 7 gesehen haben, ist selbst etwas so Grundlegendes wie die boolesche XOR-Funktion nicht linear trennbar.
- Hinzufügen einer versteckten Ebene zwischen Eingabe- und Ausgabeschicht macht das Perceptron zu einem universellen Approximator , was im Wesentlichen bedeutet, dass es in der Lage ist, äußerst komplexe Input-Output-Beziehungen zu erfassen und zu reproduzieren.
- Das Vorhandensein einer verborgenen Ebene macht das Training etwas komplizierter, da die Eingabe-zu-Versteckung Gewichtungen haben einen indirekten Einfluss auf den endgültigen Fehler (mit diesem Begriff bezeichne ich die Differenz zwischen dem Ausgabewert des Netzwerks und dem Zielwert von den Trainingsdaten geliefert).
- Die Technik, mit der wir ein mehrschichtiges Perceptron trainieren, heißt Backpropagation :Wir propagieren den endgültigen Fehler zurück zur Eingangsseite des Netzwerks auf eine Weise, die es uns ermöglicht, Gewichtungen effektiv zu modifizieren, die nicht direkt mit dem Ausgangsknoten verbunden sind. Die Backpropagation-Prozedur ist erweiterbar – d. h. die gleiche Prozedur ermöglicht es uns, Gewichtungen zu trainieren, die einer beliebigen Anzahl von versteckten Schichten zugeordnet sind.
Das folgende Diagramm fasst die Struktur eines einfachen mehrschichtigen Perceptrons zusammen.
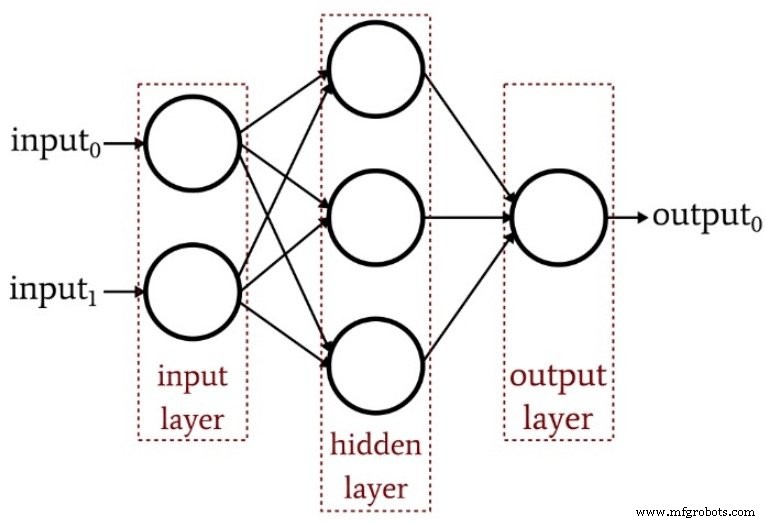
Wie viele versteckte Ebenen?
Wie zu erwarten, gibt es auf diese Frage keine einfache Antwort. Das Wichtigste ist jedoch zu verstehen, dass ein Perceptron mit einer versteckten Schicht ein extrem leistungsfähiges Rechensystem ist. Wenn Sie mit einer versteckten Schicht keine ausreichenden Ergebnisse erzielen, probieren Sie zuerst andere Verbesserungen aus – vielleicht müssen Sie Ihre Lernrate optimieren, die Anzahl der Trainingsepochen erhöhen oder Ihren Trainingsdatensatz erweitern. Das Hinzufügen einer zweiten versteckten Schicht erhöht die Codekomplexität und die Verarbeitungszeit.
Beachten Sie auch, dass ein überlastetes neuronales Netzwerk nicht nur eine Verschwendung von Codierungsaufwand und Prozessorressourcen ist – es kann sogar positiven Schaden anrichten, indem es das Netzwerk anfälliger für Übertraining macht.
Wir haben bereits in Teil 4 über Übertraining gesprochen, der das folgende Diagramm enthält, um den Betrieb eines neuronalen Netzes zu visualisieren, dessen Lösung nicht ausreichend verallgemeinert ist.
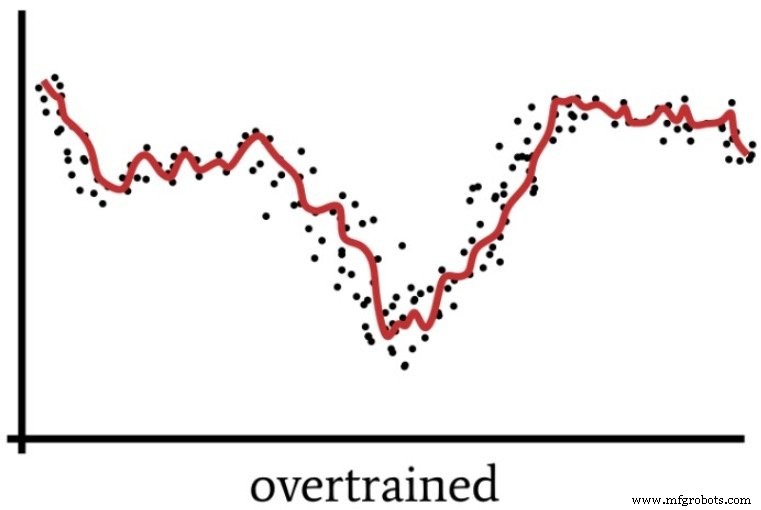
Ein Perceptron mit Superkräften kann Trainingsdaten auf eine Weise verarbeiten, die vage analog dazu ist, wie Menschen manchmal eine Situation „überdenken“.
Wenn wir uns zu sehr auf Details konzentrieren und zu viel intellektuellen Aufwand für ein in Wirklichkeit recht einfaches Problem betreiben, verpassen wir das „Big Picture“ und erhalten eine Lösung, die sich als suboptimal erweisen wird. Ebenso könnte sich ein Perceptron mit übermäßiger Rechenleistung und unzureichenden Trainingsdaten für eine zu spezifische Lösung entscheiden, anstatt eine verallgemeinerte Lösung zu finden (wie in der nächsten Abbildung gezeigt), die neue Eingabeproben effektiver klassifiziert.
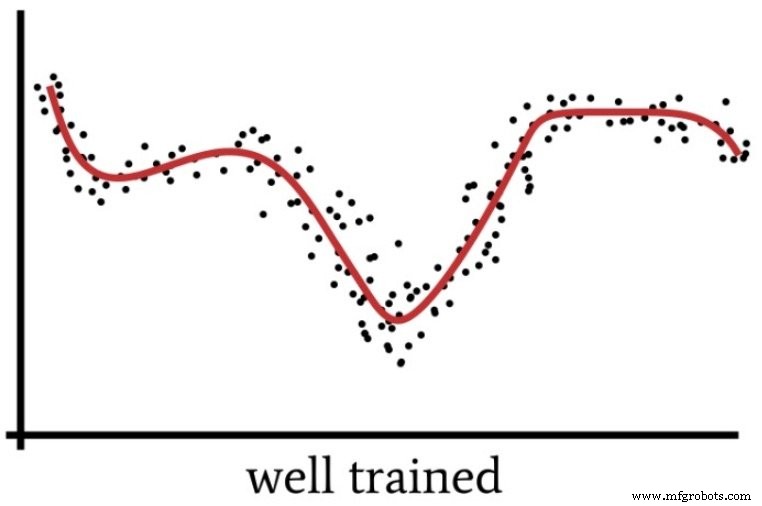
Wann brauchen wir also tatsächlich mehrere versteckte Schichten? Aus eigener Erfahrung kann ich dir keine Richtwerte geben. Das Beste, was ich tun kann, ist, das Fachwissen von Dr. Jeff Heaton (siehe Seite 158 des verlinkten Textes) weiterzugeben, der feststellt, dass eine verborgene Schicht es einem neuronalen Netzwerk ermöglicht, sich jeder Funktion anzunähern, die eine „kontinuierliche Abbildung von einem endlichen Raum in einen anderen“ beinhaltet .”
Mit zwei versteckten Schichten ist das Netzwerk in der Lage, „eine beliebige Entscheidungsgrenze mit beliebiger Genauigkeit darzustellen“.
Wie viele versteckte Knoten?
Das Finden der optimalen Dimensionalität für eine verdeckte Schicht erfordert Versuch und Irrtum. Wie oben besprochen, ist es unerwünscht, zu viele Knoten zu haben, aber Sie müssen über genügend Knoten verfügen, damit das Netzwerk die Komplexität der Eingabe-Ausgabe-Beziehung erfassen kann.
Versuch und Irrtum ist schön und gut, aber Sie brauchen einen vernünftigen Ausgangspunkt. In demselben oben verlinkten Buch (auf Seite 159) nennt Dr. Heaton drei Faustregeln für die Wahl der Dimensionalität einer verdeckten Schicht. Ich werde darauf aufbauen, indem ich Empfehlungen ausspreche, die auf meiner vagen Signalverarbeitungsintuition basieren.
- Wenn das Netzwerk nur einen Ausgabeknoten hat und Sie der Meinung sind, dass die erforderliche Eingabe-Ausgabe-Beziehung relativ einfach ist, beginnen Sie mit einer Dimensionalität der versteckten Schicht, die zwei Drittel der Eingabedimensionalität entspricht.
- Wenn Sie über mehrere Ausgabeknoten verfügen oder der Meinung sind, dass die erforderliche Eingabe-Ausgabe-Beziehung komplex ist, machen Sie die Dimensionalität der verborgenen Schicht gleich der Eingabedimensionalität plus der Ausgabedimensionalität (aber halten Sie sie kleiner als das Doppelte der Eingabedimensionalität).
- Wenn Sie der Meinung sind, dass die erforderliche Eingabe-Ausgabe-Beziehung extrem komplex ist, setzen Sie die verborgene Dimensionalität auf eins weniger als das Doppelte der Eingabedimension.
Schlussfolgerung
Ich hoffe, dieser Artikel hat Ihnen geholfen, den Prozess der Konfiguration und Verfeinerung der Hidden-Layer-Konfiguration eines mehrschichtigen Perceptrons zu verstehen.
Im nächsten Artikel werden wir die Auswirkungen der Dimensionalität versteckter Schichten anhand meiner Python-Implementierung und einiger Beispielprobleme untersuchen.
Industrieroboter
- Was ist eine Kniehebelpresse und wie funktioniert sie?
- Wie funktioniert eine Zahnstangenpresse?
- Was ist Spritzpressen und wie funktioniert es?
- Was ist eine Übertragung und wie funktioniert sie?
- Integrieren von Bias-Knoten in Ihr neuronales Netzwerk
- So erhöhen Sie die Genauigkeit eines neuronalen Netzes mit versteckter Schicht
- Trainings-Datasets für neuronale Netze:So trainieren und validieren Sie ein neuronales Python-Netzwerk
- So erstellen Sie ein mehrschichtiges neuronales Perceptron-Netzwerk in Python
- Was ist eine Industriekupplung und wie funktioniert sie?
- Wie viel PS braucht eine Hydraulikpumpe?