


Was ist Hadoop? Hadoop Big Data-Verarbeitung
Die Entwicklung von Big Data hat neue Herausforderungen hervorgebracht, die neue Lösungen erforderten. Wie nie zuvor in der Geschichte müssen Server riesige Datenmengen in Echtzeit verarbeiten, sortieren und speichern.
Diese Herausforderung hat zur Entstehung neuer Plattformen wie Apache Hadoop geführt, die problemlos mit großen Datensätzen umgehen können.
In diesem Artikel erfahren Sie, was Hadoop ist, was seine Hauptkomponenten sind und wie Apache Hadoop bei der Verarbeitung von Big Data hilft.
Was ist Hadoop?
Die Apache Hadoop-Softwarebibliothek ist ein Open-Source-Framework, mit dem Sie Big Data in einer verteilten Computerumgebung effizient verwalten und verarbeiten können.
Apache Hadoop besteht aus vier Hauptmodulen :
Hadoop Distributed File System (HDFS)
Daten befinden sich im verteilten Dateisystem von Hadoop, das dem eines lokalen Dateisystems auf einem typischen Computer ähnelt. HDFS bietet im Vergleich zu herkömmlichen Dateisystemen einen besseren Datendurchsatz.
Darüber hinaus bietet HDFS eine hervorragende Skalierbarkeit. Sie können problemlos und auf handelsüblicher Hardware von einem einzelnen Computer auf Tausende skalieren.
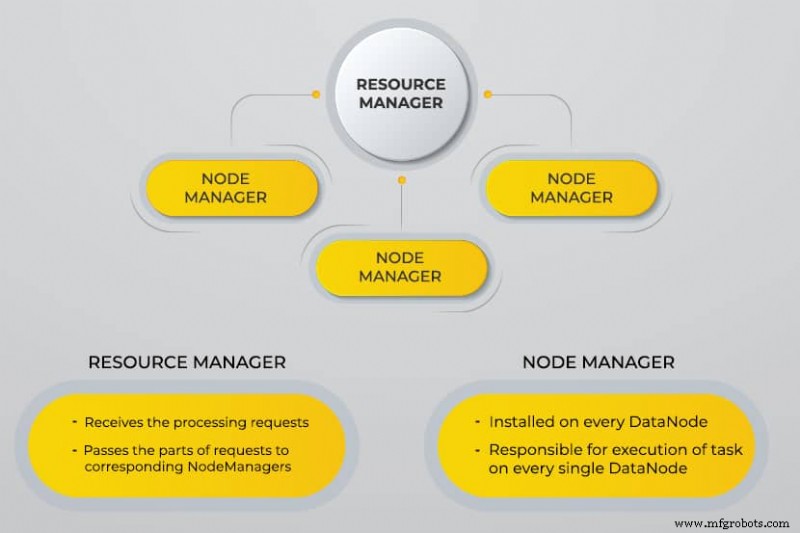
Yet Another Resource Negotiator (YARN)
YARN erleichtert geplante Aufgaben, die gesamte Verwaltung und Überwachung von Clusterknoten und anderen Ressourcen.
MapReduce
Das Hadoop MapReduce-Modul hilft Programmen, parallele Datenberechnungen durchzuführen. Die Map-Aufgabe von MapReduce konvertiert die Eingabedaten in Schlüssel-Wert-Paare. Reduzieren Sie Aufgaben, verbrauchen Sie die Eingabe, aggregieren Sie sie und produzieren Sie das Ergebnis.
Hadoop Common
Hadoop Common verwendet standardmäßige Java-Bibliotheken für alle Module.
Warum wurde Hadoop entwickelt?
Das World Wide Web ist in den letzten zehn Jahren exponentiell gewachsen und besteht heute aus Milliarden von Seiten. Die Online-Suche nach Informationen wurde aufgrund ihrer beträchtlichen Menge schwierig. Diese Daten wurden zu Big Data und bestehen aus zwei Hauptproblemen:
- Schwierigkeit beim Speichern all dieser Daten auf effiziente und leicht abzurufende Weise
- Schwierigkeit bei der Verarbeitung der gespeicherten Daten
Entwickler haben an vielen Open-Source-Projekten gearbeitet, um Websuchergebnisse schneller und effizienter zurückzugeben, indem sie die oben genannten Probleme angegangen sind. Ihre Lösung bestand darin, Daten und Berechnungen über einen Cluster von Servern zu verteilen, um eine gleichzeitige Verarbeitung zu erreichen.
Letztendlich stellte Hadoop eine Lösung für diese Probleme dar und brachte viele weitere Vorteile mit sich, einschließlich der Reduzierung der Kosten für die Serverbereitstellung.
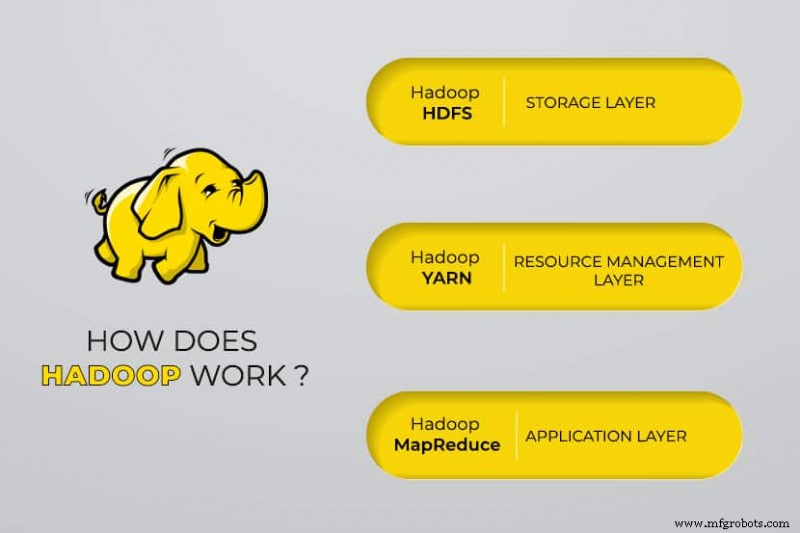
Wie funktioniert die Hadoop Big Data-Verarbeitung?
Mit Hadoop nutzen wir die Speicher- und Verarbeitungskapazität von Clustern und implementieren eine verteilte Verarbeitung für Big Data. Im Wesentlichen bietet Hadoop eine Grundlage, auf der Sie andere Anwendungen zur Verarbeitung von Big Data aufbauen.
Anwendungen, die Daten in verschiedenen Formaten sammeln, speichern sie im Hadoop-Cluster über die API von Hadoop, die eine Verbindung zum NameNode herstellt. Der NameNode erfasst die Struktur des Dateiverzeichnisses und die Platzierung von „Blöcken“ für jede erstellte Datei. Hadoop repliziert diese Chunks über DataNodes zur parallelen Verarbeitung.
MapReduce führt Datenabfragen durch. Es bildet alle DataNodes ab und reduziert die Aufgaben im Zusammenhang mit den Daten in HDFS. Der Name „MapReduce“ selbst beschreibt, was es tut. Map-Tasks werden auf jedem Knoten für die bereitgestellten Eingabedateien ausgeführt, während Reducer ausgeführt werden, um die Daten zu verknüpfen und die endgültige Ausgabe zu organisieren.
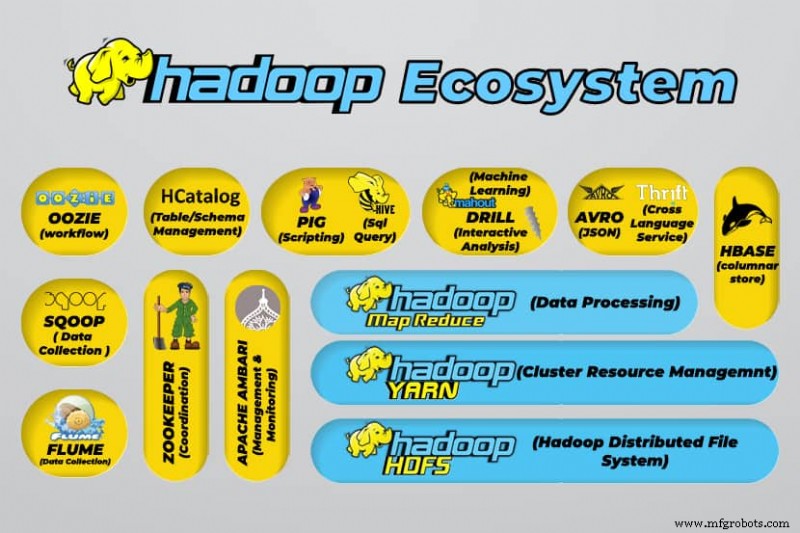
Hadoop Big Data-Tools
Das Hadoop-Ökosystem unterstützt eine Vielzahl von Open-Source-Big-Data-Tools. Diese Tools ergänzen die Kernkomponenten von Hadoop und verbessern seine Fähigkeit, Big Data zu verarbeiten.
Zu den nützlichsten Big-Data-Verarbeitungstools gehören:
- Apache Hive
Apache Hive ist ein Data Warehouse zur Verarbeitung großer Datensätze, die im Dateisystem von Hadoop gespeichert sind.
- Apache Zookeeper
Apache Zookeeper automatisiert Failover und reduziert die Auswirkungen eines ausgefallenen NameNode.
- Apache HBase
Apache HBase ist eine nicht relationale Open-Source-Datenbank für Hadoop.
- Apache Flume
Apache Flume ist ein verteilter Dienst für das Daten-Streaming großer Mengen von Protokolldaten.
- Apache Sqoop
Apache Sqoop ist ein Befehlszeilentool zum Migrieren von Daten zwischen Hadoop und relationalen Datenbanken.
- Apache-Schwein
Apache Pig ist die Entwicklungsplattform von Apache zur Entwicklung von Jobs, die auf Hadoop ausgeführt werden. Die verwendete Softwaresprache ist Pig Latin.
- Apache Oozie
Apache Oozie ist ein Planungssystem, das die Verwaltung von Hadoop-Jobs erleichtert.
- Apache HCatalog
Apache HCatalog ist ein Speicher- und Tabellenverwaltungstool zum Sortieren von Daten aus verschiedenen Datenverarbeitungstools.
Vorteile von Hadoop
Hadoop ist eine robuste Lösung für die Verarbeitung von Big Data und ein unverzichtbares Tool für Unternehmen, die mit Big Data arbeiten.
Die wichtigsten Funktionen und Vorteile von Hadoop sind unten aufgeführt:
- Schnellere Speicherung und Verarbeitung großer Datenmengen
Mit dem Aufkommen von Social Media und dem Internet of Things (IoT) stieg die zu speichernde Datenmenge dramatisch an. Die Speicherung und Verarbeitung dieser Datensätze ist für die Unternehmen, denen sie gehören, von entscheidender Bedeutung. - Flexibilität
Dank der Flexibilität von Hadoop können Sie unstrukturierte Datentypen wie Text, Symbole, Bilder und Videos speichern. In herkömmlichen relationalen Datenbanken wie RDBMS müssen Sie die Daten verarbeiten, bevor Sie sie speichern. Mit Hadoop ist eine Vorverarbeitung der Daten jedoch nicht erforderlich, da Sie die Daten so speichern können, wie sie sind, und entscheiden, wie sie später verarbeitet werden. Mit anderen Worten, es verhält sich wie eine NoSQL-Datenbank. - Rechenleistung
Hadoop verarbeitet Big Data über ein verteiltes Rechenmodell. Seine effiziente Nutzung der Rechenleistung macht es sowohl schnell als auch effizient. - Reduzierte Kosten
Viele Teams gaben ihre Projekte aufgrund der hohen Kosten auf, bevor Frameworks wie Hadoop auf den Markt kamen. Hadoop ist ein Open-Source-Framework, das kostenlos verwendet werden kann und zum Speichern von Daten billige Standardhardware verwendet. - Skalierbarkeit
Mit Hadoop können Sie Ihr System schnell und ohne großen Verwaltungsaufwand skalieren, indem Sie einfach die Anzahl der Knoten in einem Cluster ändern. - Fehlertoleranz
Einer der vielen Vorteile der Verwendung eines verteilten Datenmodells ist seine Fähigkeit, Ausfälle zu tolerieren. Hadoop ist nicht von Hardware abhängig, um die Verfügbarkeit aufrechtzuerhalten. Wenn ein Gerät ausfällt, leitet das System die Aufgabe automatisch an ein anderes Gerät weiter. Fehlertoleranz ist möglich, da redundante Daten beibehalten werden, indem mehrere Datenkopien im gesamten Cluster gespeichert werden. Mit anderen Worten, die Hochverfügbarkeit wird auf der Softwareebene aufrechterhalten.
Die drei wichtigsten Anwendungsfälle
Big Data verarbeiten
Wir empfehlen Hadoop für große Datenmengen, normalerweise im Bereich von Petabyte oder mehr. Es eignet sich besser für riesige Datenmengen, die eine enorme Rechenleistung erfordern. Hadoop ist möglicherweise nicht die beste Option für ein Unternehmen, das kleinere Datenmengen im Bereich von mehreren hundert Gigabyte verarbeitet.
Speichern eines vielfältigen Datensatzes
Einer der vielen Vorteile von Hadoop ist, dass es flexibel ist und verschiedene Datentypen unterstützt. Unabhängig davon, ob Daten aus Text, Bildern oder Videodaten bestehen, Hadoop kann sie effizient speichern. Organisationen können je nach Bedarf wählen, wie sie Daten verarbeiten. Hadoop hat die Eigenschaften eines Data Lake, da es Flexibilität über die gespeicherten Daten bietet.
Parallele Datenverarbeitung
Der in Hadoop verwendete MapReduce-Algorithmus orchestriert die parallele Verarbeitung gespeicherter Daten, sodass Sie mehrere Aufgaben gleichzeitig ausführen können. Gemeinsame Operationen sind jedoch nicht zulässig, da dies die Standardmethodik in Hadoop durcheinander bringt. Es beinhaltet Parallelität, solange die Daten voneinander unabhängig sind.
Wofür wird Hadoop in der realen Welt verwendet?
Unternehmen aus der ganzen Welt nutzen Hadoop-Big-Data-Verarbeitungssysteme. Einige der vielen praktischen Anwendungen von Hadoop sind unten aufgeführt:
- Kundenanforderungen verstehen
In der heutigen Zeit hat sich Hadoop als sehr nützlich erwiesen, um Kundenanforderungen zu verstehen. Große Unternehmen in der Finanzbranche und in den sozialen Medien nutzen diese Technologie, um Kundenanforderungen zu verstehen, indem sie Big Data bezüglich ihrer Aktivitäten analysieren.
Unternehmen verwenden diese Daten, um Kunden personalisierte Angebote zu unterbreiten. Möglicherweise haben Sie dies durch Anzeigen erlebt, die auf Social Media- und E-Commerce-Websites basierend auf unseren Interessen und Internetaktivitäten gezeigt wurden. - Optimierung von Geschäftsprozessen
Hadoop hilft, die Leistung von Unternehmen zu optimieren, indem es ihre Transaktions- und Kundendaten besser analysiert. Trendanalysen und Vorhersageanalysen können Unternehmen dabei helfen, ihre Produkte und Bestände anzupassen, um den Umsatz zu steigern. Eine solche Analyse erleichtert eine bessere Entscheidungsfindung und führt zu höheren Gewinnen.
Darüber hinaus verwenden Unternehmen Hadoop, um ihre Arbeitsumgebung zu verbessern, indem sie das Verhalten der Mitarbeiter überwachen, indem sie Daten über ihre Interaktionen untereinander sammeln. - Verbesserung der Gesundheitsversorgung
Einrichtungen in der medizinischen Industrie können Hadoop verwenden, um die riesige Menge an Daten zu Gesundheitsproblemen und medizinischen Behandlungsergebnissen zu überwachen. Forscher können diese Daten analysieren, um Gesundheitsprobleme zu identifizieren, Medikamente vorherzusagen und Behandlungspläne festzulegen. Solche Verbesserungen werden es den Ländern ermöglichen, ihre Gesundheitsdienste schnell zu verbessern. - Finanzhandel
Hadoop verfügt über einen ausgeklügelten Algorithmus zum Scannen von Marktdaten mit vordefinierten Einstellungen, um Handelsmöglichkeiten und saisonale Trends zu identifizieren. Finanzunternehmen können die meisten dieser Vorgänge durch die robusten Funktionen von Hadoop automatisieren. - Hadoop für IoT verwenden
IoT-Geräte sind auf die Verfügbarkeit von Daten angewiesen, um effizient zu funktionieren. Hersteller und Erfinder nutzen Hadoop als Data Warehouse für Milliarden von Transaktionen. Da IoT ein Datenstreaming-Konzept ist, ist Hadoop eine geeignete und praktische Lösung zur Verwaltung der riesigen Datenmengen, die es umfasst.
Hadoop wird kontinuierlich aktualisiert, wodurch wir die mit IoT-Plattformen verwendeten Anweisungen verbessern können.
Weitere praktische Anwendungen von Hadoop umfassen die Verbesserung der Geräteleistung, die Verbesserung der persönlichen Quantifizierung und Leistungsoptimierung sowie die Verbesserung des Sports und der wissenschaftlichen Forschung.
Was sind die Herausforderungen bei der Verwendung von Hadoop?
Jede Anwendung bringt sowohl Vorteile als auch Herausforderungen mit sich. Hadoop bringt auch mehrere Herausforderungen mit sich:
- Der MapReduce-Algorithmus ist nicht immer die Lösung
Der MapReduce-Algorithmus unterstützt nicht alle Szenarien. Es eignet sich für einfache Informationsanfragen und Probleme, die in unabhängige Einheiten zerlegt werden, nicht jedoch für iterative Aufgaben.
MapReduce ist für fortgeschrittenes analytisches Computing ineffizient, da iterative Algorithmen eine intensive Interkommunikation erfordern und mehrere Dateien in der MapReduce-Phase erstellen. - Vollständig entwickeltes Datenmanagement
Hadoop bietet keine umfassenden Tools für Datenmanagement, Metadaten und Data Governance. Außerdem fehlen ihm die notwendigen Werkzeuge zur Datenstandardisierung und Qualitätsbestimmung. - Talentlücke
Aufgrund der steilen Lernkurve von Hadoop kann es schwierig sein, Programmierer auf Einstiegsniveau mit Java-Kenntnissen zu finden, die ausreichen, um mit MapReduce produktiv zu arbeiten. Diese Intensität ist der Hauptgrund dafür, dass die Anbieter daran interessiert sind, relationale (SQL) Datenbanktechnologie auf Hadoop zu setzen, da es viel einfacher ist, Programmierer mit fundierten SQL-Kenntnissen zu finden als mit MapReduce-Kenntnissen.
Die Hadoop-Administration ist sowohl eine Kunst als auch eine Wissenschaft und erfordert grundlegende Kenntnisse über Betriebssysteme, Hardware und Hadoop-Kernel-Einstellungen. - Datensicherheit
Das Kerberos-Authentifizierungsprotokoll ist ein wichtiger Schritt, um Hadoop-Umgebungen sicher zu machen. Datensicherheit ist entscheidend, um Big-Data-Systeme vor Sicherheitsproblemen durch fragmentierte Daten zu schützen.
Schlussfolgerung
Hadoop ist sehr effektiv bei der Bewältigung der Big-Data-Verarbeitung, wenn es effektiv mit den erforderlichen Schritten zur Bewältigung seiner Herausforderungen implementiert wird. Es ist ein vielseitiges Werkzeug für Unternehmen, die mit umfangreichen Datenmengen umgehen.
Einer der Hauptvorteile besteht darin, dass es auf jeder Hardware ausgeführt werden kann und ein Hadoop-Cluster auf Tausende von Servern verteilt werden kann. Diese Flexibilität ist besonders wichtig in Infrastruktur-als-Code-Umgebungen.
Cloud Computing
- Big Data und Cloud Computing:Eine perfekte Kombination
- Was ist Cloud-Sicherheit und warum ist sie erforderlich?
- Welche Beziehung besteht zwischen Big Data und Cloud Computing?
- Einsatz von Big Data und Cloud Computing in Unternehmen
- Was Sie 2018 von IoT-Plattformen erwarten können
- Vorausschauende Wartung – Was Sie wissen müssen
- Was genau ist DDR5-RAM? Funktionen &Verfügbarkeit
- Was ist IIoT?
- Big Data vs. künstliche Intelligenz
- Big Data aus Little Data aufbauen