


Cloud-Ausfall:Warum und wie passiert er?
Je mehr sich die IT auf Cloud-Services verlässt, desto wahrscheinlicher sind Ausfallzeiten und Umsatzeinbußen aufgrund eines Cloud-Ausfalls. Über 60 % der Unternehmen, die die Public Cloud nutzen, melden Verluste im Jahr 2022 aufgrund dieser Vorfälle, sodass Ausfälle kein ungewöhnliches Ereignis sind, mit dem Unternehmen wahrscheinlich nicht konfrontiert werden.
Aber sind Ausfälle Grund genug, die Cloud endgültig zu verlassen? Oder sollten Sie trotz des Risikos gelegentlicher Ausfallzeiten bei diesem Infrastrukturtyp bleiben?
In diesem Artikel wird alles behandelt, was Sie über Cloud-Ausfälle wissen müssen . Wir skizzieren ihre Hauptursachen, untersuchen aufschlussreiche Statistiken, zeigen, wie die Auswirkungen von Cloud-Ausfallzeiten minimiert werden können, und sehen uns die schwerwiegendsten Ausfälle der letzten Jahre an.

Was ist ein Cloud-Ausfall?
Ein Cloud-Ausfall ist eine Zeitspanne, in der die Dienste eines Cloud-Anbieters für Endbenutzer nicht verfügbar sind. Die Infrastruktur des Anbieters fällt aus (aufgrund eines Fehlers, Stromausfalls usw.) und die Clients verlieren den Zugriff auf Cloud-basierte Assets, bis der Anbieter das Problem behebt.
In Bezug auf die Auswirkungen gibt es keinen Unterschied zwischen einem Ausfall eines Rechenzentrums vor Ort und einem Cloud-Ausfall. Sie verlieren in beiden Fällen den Zugriff auf IT-Ressourcen, aber der praktische Ansatz für Cloud Computing fügt einige einzigartige Überlegungen hinzu:
- Cloud-Ausfälle sind kaum bis gar nicht sichtbar, sodass Benutzer in der Regel nicht wissen, was schief gelaufen ist.
- Das Team des Anbieters ist für die Behebung des Fehlers verantwortlich, sodass Clients nicht am Wiederherstellungsprozess teilnehmen.
- Da Sie das Problem nicht einsehen oder kontrollieren können, können Sie nicht wissen, wann die Dienste wieder online gehen.
Wie bei lokaler Hardware gibt es zwei Arten von möglichen Ausfällen:
- Geplant (tritt normalerweise aufgrund geplanter Wartungsarbeiten auf).
- Ungeplant (passiert, wenn der Anbieter auf einen unerwarteten Fehler stößt und Wiederherstellungsmaßnahmen durchführen muss).
Jüngste Studien zeigen, dass ungeplante Ausfälle 35 % mehr kosten als geplante Ausfallzeiten (sowohl vor Ort als auch in der Cloud). Der Preisunterschied besteht, weil die Erkennung und Behebung unerwarteter Vorfälle länger dauert – und je länger ein Ausfall dauert, desto größer ist der Schaden.
Im Vergleich zu Hardware vor Ort führt eine Cloud-basierte Infrastruktur zu häufigeren Ausfallzeiten, aber mit geringerem Schweregrad . Da kein Hosting-System eine 100-prozentige Betriebszeit bietet, sind Kunden bereit, gelegentliche Ausfälle im Gegenzug für die Vorteile des Cloud-Computing in Kauf zu nehmen. Diese Bereitschaft zeigt sich auch im Marktwachstum – die Cloud wird 2024 14,2 % der gesamten globalen IT-Ausgaben ausmachen (gegenüber 9,1 % im Jahr 2020).
Ursachen von Cloud-Ausfällen
Cloud-Ausfälle haben eine Reihe von Ursachen, die sowohl innerhalb als auch außerhalb der Kontrolle des Anbieters liegen. Hier ist eine Liste der häufigsten:
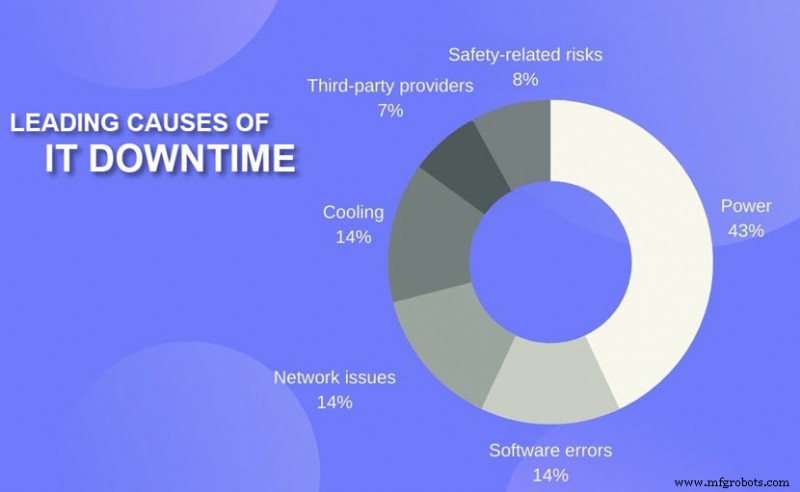
- Stromausfall: Probleme mit der Stromversorgung verursachen 43 % aller Cloud-Ausfälle mit erheblichen Ausfallzeiten und finanziellen Verlusten. Ausfälle der unterbrechungsfreien Stromversorgung (USV) sind die häufigste Ursache für Stromausfälle.
- Cybersicherheit: Cyberangriffe wie Distributed Denial of Service (DDoS) überlasten Rechenzentren mit eingehendem Datenverkehr. In diesem Fall können Endbenutzer nicht über dieselbe Netzwerkinfrastruktur auf den Dienst zugreifen. Andere Bedrohungen (z. B. Ransomware oder eine SQL-Injection) können den Anbieter dazu zwingen, Dienste herunterzufahren und das Problem offline zu beheben.
- Menschlicher Fehler: Ein einziger falscher Befehl oder ein Fehler bei der Verkabelung kann die gesamte IT-Infrastruktur zum Erliegen bringen. Menschliche Fehler verursachen sowohl physische als auch Softwareprobleme, die zu Ausfällen führen.
- Technische Probleme: Cloud-Dienste basieren auf einem komplexen System von Hardware-Technologie, sodass ein Fehler, der lange genug unter dem Radar bleibt, zu einem Cloud-Ausfall führen kann.
- Softwarefehler: Glitches und Bugs sind in Cloud-Rechenzentren üblich. Die üblichen Übeltäter hinter Problemen sind Datenformatfehler, Fehler im Zusammenhang mit Fehlern, Zeitfehlern und Fehlern mit konstanten Werten.
- Netzwerkprobleme: Probleme im Zusammenhang mit der Netzwerkkommunikation und Telekommunikationspartnern von Drittanbietern sind eine weitere häufige Ursache für Cloud-Ausfälle.
- Wartung: Geplante Wartungsarbeiten und System-Upgrades führen manchmal zu einem Ausfall, obwohl Endbenutzer normalerweise im Voraus über diese Vorkommnisse Bescheid wissen.
- Umweltbedingte Ursachen: Ereignisse wie Wirbelstürme, Brände, Gewitter und Erdbeben lösen ebenfalls Cloud-Ausfallzeiten aus, indem sie entweder die Anlage gefährden oder das Stromnetz der Region beschädigen.
- Komplexere Bereitstellungen: Kompliziertere Bereitstellungsmodelle (z. B. hybride, verteilte und Multi-Cloud) erschweren den Rechenzentrumsbetrieb und schaffen mehr Möglichkeiten für Fehler.
Was passiert, wenn die Wolke untergeht?
Im besten Fall dauert ein Cloud-Ausfall nur wenige Minuten und betrifft eine kleine Anzahl von Benutzern oder Diensten. Im schlimmsten Fall legt ein Ausfall das Geschäft eines Kunden für einen halben Tag oder länger lahm. Ein Unternehmen verliert den Zugriff auf alle Cloud-basierten Assets und bleibt bis zum Ende des Ausfalls abgeschnitten.
Obwohl bedrohlich, Fehler von Drittanbietern waren die Ursache für "nur" 7 % der schwerwiegenden Ausfälle im Jahr 2021 . Ein schwerwiegender Ausfall muss eine (oder mehrere) der folgenden Ursachen haben:
- Erhebliche finanzielle Verluste.
- Rufschaden.
- Compliance-Verstöße.
- Verlust von Menschenleben.
Obwohl es dringendere Bedenken gibt (wie im Donut-Diagramm unten gezeigt), denken Sie daran, dass eine durchschnittliche Minute Ausfallzeit 5.600 $ kostet (Diese Zahl pro Minute beläuft sich für Unternehmen auf 9.000 US-Dollar). Wenn Sie unvorbereitet sind (d. h. Sie haben keine Datensicherungen, Notfallwiederherstellung usw.), könnte ein Cloud-Ausfall Ihren Dienst zum Erliegen bringen und massive Einbußen beim Endergebnis verursachen.
Ein Unternehmen, das einen kleinen Teil des Betriebs in der Cloud hält, ist weniger anfällig für Ausfälle. Wenn Sie beispielsweise nur E-Mails in der Cloud hosten, ist selbst ein ganztägiger Ausfall keine Katastrophe. Sie können den Vorfall abwarten oder Apps mit eingeschränkter Funktionalität ausführen, eine Strategie, die nicht funktioniert, wenn Sie die Cloud verwenden, um eine IoT-Plattform zu betreiben oder die Zahlungsabwicklung durchzuführen.
In einigen Fällen führt ein Cloud-Ausfall zu einem dauerhaften Datenverlust (die Menge der verlorenen Daten hängt von der Häufigkeit der Sicherungen ab). Darüber hinaus müssen Kunden in bestimmten Branchen gesetzliche Bußgelder zahlen, wenn ein Ausfall zu einer Datenpanne oder einem Datenleck führt. Seien Sie also vorsichtig, wenn Sie entscheiden, was Sie im Cloud-Speicher aufbewahren.
Was können Benutzer tun?
Unternehmen tun Folgendes, um die Auswirkungen von Cloud-Ausfällen abzumildern:
- Single Points of Failure entfernen: Erstellen Sie ein Backup jeder geschäftskritischen IT-Komponente, entweder in einem Serverraum vor Ort oder bei einem sekundären Anbieter. Wenn die Cloud ausfällt, führen Sie ein Failover durch (der Prozess des Umschaltens auf einen Standby-Server, eine Hardwarekomponente, ein Netzwerk usw.), um die Geschäftskontinuität sicherzustellen.
- Haben Sie einen Notfallplan: Ein Disaster-Recovery-Plan skizziert eine Schritt-für-Schritt-Strategie für das Vorgehen des Teams im Falle eines Ausfalls. Dieser Plan enthält Anweisungen zum Schutz von Daten, zur Durchführung von Failover, zur Sicherstellung der Geschäftskontinuität und zur Wiederherstellung des Betriebs. Eine rechtzeitige Planung für einen Cloud-Ausfall vermeidet Zeitverschwendung bei der Bewertung der besten Vorgehensweise während der Ausfallzeit.
- Investieren Sie in ein SLA mit höherer Verfügbarkeit: Wenn sich Ihre geschäftskritischen Aufgaben keine langen Cloud-Ausfälle leisten können, suchen Sie nach einem Service Level Agreement (SLA) für höhere Verfügbarkeit, z. Diese Verträge sind teurer, aber die Online-Bereitstellung Ihrer Dienste wird für den Cloud-Anbieter immer wichtiger.
- Führen Sie regelmäßige Datensicherungen durch: Ein Backup stellt sicher, dass Ihr Team eine Möglichkeit hat, eine aktuelle Version von Dateien wiederherzustellen, wenn ein Cloud-Ausfall eine Datenbank beschädigt oder löscht. Im Idealfall sollten Sicherungen automatisch und irgendwo zwischen einmal pro Stunde und einmal pro Tag (je nach geschäftskritischer Bedeutung) erfolgen.
- Ausfälle so schnell wie möglich erkennen: Alle zusätzlichen Cloud-Überwachungsfunktionen, die Ihr Team einrichtet, helfen dabei, einen Ausfall in Echtzeit zu erkennen, anstatt auf die Benachrichtigung des Anbieters warten zu müssen. Hier ist eine Liste der besten Cloud-Überwachungstools, um die Erkennung von Ausfallzeiten zu verbessern und ein rechtzeitiges Failover sicherzustellen.
Größte aktuelle Cloud-Ausfälle
Cloud-Ausfälle sind bei der Nutzung der Cloud unvermeidlich, und selbst die beliebtesten Anbieter (wie Azure, AWS und Google Cloud) sind vor Ausfallzeiten nicht gefeit. Sehen wir uns einige der bedeutendsten Cloud-Ausfälle in der jüngeren Geschichte an.
Azure-Ausfall (Oktober 2021)
Im Oktober 2021 kam es bei Microsoft Azure zu einer Unterbrechung, die die Dienste virtueller Maschinen für sechs Stunden lahmlegte . Für die Dauer des Ausfalls konnten viele Benutzer keine neuen VMs bereitstellen oder Erweiterungen aktualisieren. Grundlegende Dienstverwaltungsvorgänge (wie Starten, Erstellen und Löschen) führten ebenfalls zu Fehlern.
Die Ursache für den Cloud-Ausfall war die Unfähigkeit von VM-Abfragen, die erforderlichen Versionsdaten eines Artefakts abzurufen. Ein Bericht nach der Wiederherstellung ergab, dass der softwarebasierte Fehler auftrat, als Microsoft eine seiner VM-Architekturen migrierte.
Google Cloud-Ausfall (November 2021)
Google Cloud fiel für etwa zwei Stunden aus Mitte November letzten Jahres, die Folgendes betrifft:
- Baumarkt.
- Snapchat.
- Etsy.
- Zwietracht.
- Spotify.
Betroffene Websites zeigten 404-Fehler an, wenn Besucher versuchten, auf sie zuzugreifen. Google berichtete, dass die Ursache für den Cloud-Ausfall ein Fehler in einer Netzwerkkonfiguration war, die für den Lastenausgleich verantwortlich ist.
AWS-Ausfall (Dezember 2021)
Ein großer Anstieg der Verbindungsaktivität überwältigte Netzwerkgeräte in einer der Flaggschiff-Einrichtungen von AWS und wirkte sich auf verschiedene Websites und Apps aus. Einige der bemerkenswertesten "Opfer" waren:
- Website von Amazon.
- Prime-Video.
- Netflix.
- IMDb.
- PlayStation Network.
Das Rechenzentrumsproblem verursachte erhebliche Latenzen in internen AWS-Netzwerken. Kunden-Apps spürten die Auswirkungen und litten unter Verkehrsverzögerungen oder Totalabschaltungen für etwa sieben Stunden .
Zwei aufeinander folgende IBM-Ausfälle (Januar 2022)
Ein Problem mit der IBM-Infrastruktur beeinträchtigte Cloud-Services in der Region Dallas für mehr als fünf Stunden . Das interne Team löste das Problem, verursachte jedoch versehentlich ein zusätzliches einstündiges Problem mit der Virtual Private Cloud. Das sekundäre Problem betraf Benutzer auf der ganzen Welt, darunter die USA, Japan, Kanada und Deutschland.
AWS/Slack-Ausfall (Februar 2022)
Slack erlitt im Februar einen Ausfall seiner AWS-Cloud-Ressourcen, wodurch die normale Nutzung der Kommunikationsplattform für fünf Stunden verhindert wurde . Über 11.000 gemeldete Benutzer konnten Folgendes nicht:
- Nachrichten senden oder empfangen.
- Dateien hochladen.
- Kanälen beitreten.
- Starten Sie die Desktop-App.
Das Team von Slack teilte nie den Grund für den Cloud-Ausfall mit und forderte alle betroffenen Benutzer auf, die App neu zu starten und ihren Cache nach der Wiederherstellung zu löschen.
iCloud-Ausfall (März 2022)
Fünfzehn wichtige Apple-Dienste fielen für vier Stunden aus im März aufgrund eines Cloud-Ausfalls, einschließlich:
- App Store.
- Apple-Karten.
- Apple TV.
Apples Unternehmens- und Einzelhandelssysteme fielen ebenfalls aus. Das Unternehmen gab später bekannt, dass die Hauptursache ein Problem im Zusammenhang mit dem Domain Name System (DNS) des Unternehmens war.
Google Cloud-Ausfall (März 2022)
Am 8. März 2022 kam es bei Google Cloud-Nutzern zweieinhalb Stunden lang zu Dienstfehlern . Spotify und Discord waren unter anderem von dem Ausfall betroffen.
Der Fehler wurde durch eine Änderung am Traffic Director-Code zur Verarbeitung von Konfigurationen verursacht. Laut dem Post-Recovery-Bericht vernachlässigten fehlerhafte Codeänderungen die Migration des Konfigurationsdatenformats, sodass die Plattform versehentlich die Programmierung des Benutzers löschte.
Atlassian-Ausfall (April 2022)
Der größte Atlassian-Ausfall des Jahres begann am 5. April und endete am 18. April (obwohl einige Benutzer bereits am 8. April mit der Wiederherstellung der Dienste begonnen haben). Das Unternehmen erklärte, dass der Ausfall auf eine unzureichende Teamkommunikation und einen schlecht geplanten Plan zur Reaktion auf Vorfälle zurückzuführen sei.
Obwohl dieser Cloud-Ausfall fast zwei Wochen dauerte Bei einigen Benutzern gab es keine Berichte über erhebliche Verluste von Kundendaten. Benutzer der beiden Flaggschiff-Produkte von Atlassian, Trello und Jira, waren jedoch von dem Problem betroffen.
Microsoft Azure-Ausfall (Juni 2022)
Am 7. Juni konnten Azure-Kunden keine Verbindung zu Ressourcen herstellen, die in der Region „USA, Osten 2“ (hauptsächlich Virginia) gehostet wurden. Der Ausfall dauerte ungefähr zwölf Stunden und wirkte sich nicht auf Verbraucher aus, die sich auf eine zonenredundante Infrastruktur verlassen. Eingeschlossene kompromittierte Dienste:
- Application Insights.
- Log Analytics.
- Verwalteter Identitätsdienst.
- Mediendienste.
- NetApp-Dateien.
Schuld daran war eine plötzliche Stromoszillation in einem der lokalen Rechenzentren, die dazu führte, dass Air Handling Units (AHUs) heruntergefahren wurden.
Cloudflare-Ausfall (Juni 2022)
Im Juni verursachte ein versehentlicher Ausfall bei Cloudflare größere Störungen, die eineinhalb Stunden andauerten , das Entfernen beliebter Websites wie:
- Zwietracht.
- Shopify.
- Fitbit.
- Hauptfeld.
Der in San Francisco ansässige Anbieter erklärte, dass die ungeplante Ausfallzeit auf eine Änderung der Netzwerkkonfiguration in 19 seiner Rechenzentren zurückzuführen sei.
Übersehen Sie nicht den Wert der Cloud-Ausfallplanung
Beispiele von Cloud-Ausfällen in den letzten Jahren senden eine klare Botschaft:Auch wenn die Cloud ein IT-Game-Changer ist, ist die Technologie nicht narrensicher . Unternehmen, denen die Verfügbarkeit von Endbenutzern und Anwendungen am Herzen liegt, müssen auf gelegentliche Ausfallzeiten vorbereitet sein, was Backup und Disaster Recovery (BDR) zu einem integralen Bestandteil der Nutzung von Cloud-basierten Ressourcen macht.
Cloud Computing
- Was ist Spritzpressen und wie funktioniert es?
- Wie (und warum) Sie Ihre Public Cloud-Leistung vergleichen können
- Was ist Cloud-Sicherheit und warum ist sie erforderlich?
- Cloud und wie sie die IT-Welt verändert
- Agentenlose vs. agentenbasierte Architekturen:Warum ist das wichtig?
- Was ist ein verschleierter VPN-Server und wie funktioniert er?
- Wie funktioniert Google Cloud Storage?
- Warum und wie man ein Vakuum-Audit durchführt
- Was ist eine Industriekupplung und wie funktioniert sie?
- Kraninspektionen:Wann, warum und wie?