


Xilinx verdoppelt Alveo HBM und fügt Clustering für HPC- und Big-Data-Workloads hinzu
Auf der Supercomputing-Konferenz SC21 diese Woche stellte Xilinx seine Alveo U55C-Beschleunigerkarte für Rechenzentren und eine neue standardbasierte, API-gesteuerte Clustering-Lösung für die Bereitstellung von FPGAs in großem Maßstab vor. Das Unternehmen sagte, dass diese neue Karte durch das Clustering von Hunderten von Alveo-Karten und die hohe Programmierbarkeit sowohl der Anwendung als auch des Clusters die Skalierung der Rechenfunktionen von Alveo für die Ausrichtung auf High Performance Computing (HPC)-Workloads einfacher und effizienter macht als zuvor.
Xilinx sagte, dass die Alveo U55C-Karte speziell für HPC- und Big-Data-Workloads entwickelt wurde und die höchste Rechendichte und HBM-Kapazität (High Bandbreitenspeicher) im Alveo-Beschleunigerportfolio bietet. Zusammen mit der neuen Xilinx RoCE v2-basierten Clustering-Lösung kann nun ein breites Spektrum von Kunden mit umfangreichen Computing-Workloads leistungsstarkes FPGA-basiertes HPC-Clustering unter Verwendung ihrer bestehenden Rechenzentrumsinfrastruktur und ihres Netzwerks implementieren. Architektonisch bietet der FPGA-basierte Beschleuniger für viele rechenintensive Workloads die höchste Leistung zu den niedrigsten Kosten. Es führt eine auf Standards basierende Methodik ein, die die Erstellung von Alveo HPC-Clustern unter Verwendung der bestehenden Infrastruktur und des Netzwerks eines Kunden ermöglicht.
Das Unternehmen sagte, dies sei ein großer Schritt nach vorne für eine breitere Akzeptanz von Alveo und adaptivem Computing im gesamten Rechenzentrum.

In einem Interview mit embedded.com sagte Nathan Chang, HPC-Produktmanager für Rechenzentren bei Xilinx:„Wir sehen langsam, dass Computing nicht immer der Engpass ist. Tatsächlich ist es meistens die Speicherbandbreite. Immer mehr Rechenprobleme werden an die Speicherbandbreite gebunden. Also haben wir unsere Karte auf einen einzigen Steckplatz verkleinert und auch die HBM auf dieser Karte verdoppelt. Aber noch wichtiger ist, dass wir die Möglichkeit bieten, über diese Karten hinweg zu skalieren, mit der Möglichkeit, große Cluster mit Hunderten von Karten zu erstellen und alle HBM auf diesen Karten auszurichten.“
Er fuhr fort:„Die Erschließung der Bandbreite über Cluster von Alveo-Karten war schon immer ein großes Unterfangen für unsere Community. Entwickler mussten Teams bilden und dann ihre eigenen Clustering-Designs erstellen, um ihre Anforderungen zu erfüllen. Jetzt präsentieren wir ein auf offenen Standards basierendes Clustering-Paket – was bedeutet, dass wir RoCE v2 und Rechenzentrums-Bridging über Ethernet mit 200 Gbit/s Bandbreite in jeder Karte nutzen werden.“
„Das bedeutet, dass Sie diese Karten in der bestehenden Infrastruktur in Rechenzentren in vorhandene Server einbauen, sie in bestehenden Ethernet-Netzwerken nutzen und mit InfiniBand in Bezug auf Leistung und Latenz konkurrieren können.“
„Ein weiterer wichtiger Punkt ist, dass wir nicht nur Platz für größere Workloads schaffen, sondern auch sicherstellen, dass Vitis für die Entwicklergemeinschaft leichter zugänglich ist. Sie müssen RTL oder Verilog nicht mehr verstehen. Sie können Alveo-Karten und Targets auf Alveo-Boards mit bestehenden Hochsprachen wie C, C++ und Python programmieren.“
Alveo U55C-Funktionen für HPC und Big Data
Die Alveo U55C-Karte vereint viele wichtige Funktionen, die die heutigen HPC-Workloads erfordern. Es bietet laut Xilinx mehr Parallelität der Datenpipelines, überlegenes Speichermanagement, optimierte Datenbewegung in der gesamten Pipeline und die höchste Leistung pro Watt im Alveo-Portfolio. Die Karte ist ein Single-Slot Full Height, Half Length (FHHL)-Formfaktor mit einer niedrigen maximalen Leistung von 150 W. Es bietet eine überlegene Rechendichte und verdoppelt den HBM2 auf 16 GB im Vergleich zu seinem Vorgänger, der Dual-Slot-Alveo U280-Karte. Daher bietet der neue U55C mehr Rechenleistung in einem kleineren Formfaktor, um dichte Alveo-Beschleuniger-basierte Cluster zu erstellen. Dies zielt auf Streaming-Daten mit hoher Dichte, hohe E/A-Mathematik und große Rechenprobleme ab, die eine Skalierung wie Big-Data-Analysen und KI-Anwendungen erfordern.
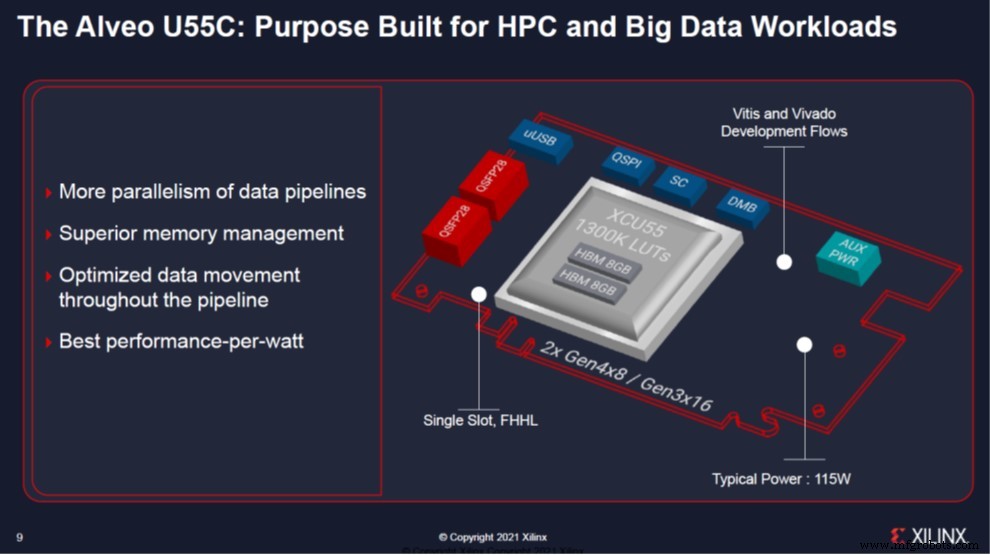
Durch die Nutzung von RoCE v2 und Rechenzentrums-Bridging in Verbindung mit 200 Gbit/s Bandbreite ermöglicht die API-gesteuerte Clustering-Lösung ein Alveo-Netzwerk, das in Leistung und Latenz mit InfiniBand-Netzwerken ohne Anbieterbindung konkurriert. Die MPI-Integration ermöglicht HPC-Entwicklern die Skalierung von Alveo-Datenpipelining von der einheitlichen Softwareplattform Xilinx Vitis. Unter Verwendung vorhandener offener Standards und Frameworks ist es nach Angaben des Unternehmens jetzt möglich, unabhängig von Serverplattformen und Netzwerkinfrastruktur und mit gemeinsam genutzten Arbeitslasten und Arbeitsspeicher auf Hunderte von Alveo-Karten zu skalieren.
Softwareentwickler und Datenwissenschaftler können die Vorteile von Alveo und adaptivem Computing durch eine hochgradige Programmierbarkeit sowohl der Anwendung als auch des Clusters unter Verwendung der Vitis-Plattform nutzen. Xilinx sagte, es habe stark in die Vitis-Entwicklungsplattform und den Werkzeugfluss investiert, um Softwareentwicklern und Datenwissenschaftlern ohne Hardware-Know-how den Zugang zu adaptivem Computing zu erleichtern. Die wichtigsten KI-Frameworks wie Pytorch und Tensorflow werden ebenso unterstützt wie höhere Programmiersprachen wie C, C++ und Python, die es Entwicklern ermöglichen, Domänenlösungen mit spezifischen APIs und Bibliotheken zu erstellen oder Xilinx-Softwareentwicklungskits zu verwenden, um wichtige HPC zu beschleunigen Workloads in einem bestehenden Rechenzentrum.
Wer verwendet die Karten?
Chang sagte, das Unternehmen habe mit mehreren Organisationen an Proof-of-Concept-Designs unter Verwendung der U55C-Karten zusammengearbeitet.

Einer von ihnen ist CSIRO, Australiens nationale Forschungsorganisation zusammen mit dem weltweit größten Radioastronomie-Antennen-Array, das den U55C anstelle von GPUs verwendet hat, da die Alveo-Karte eine Single-Slot-Karte ermöglicht und keine NIC (Network Interface Card) benötigt. CSIRO verwendet Alveo U55C-Karten zur Signalverarbeitung im Quadratkilometer-Array-Radioteleskop. Der Einsatz der Alveo-Karten als netzwerkgebundene Beschleuniger mit HBM ermöglicht einen massiven Durchsatz im gesamten HPC-Signalverarbeitungs-Cluster. Der beschleunigerbasierte Cluster von Alveo ermöglicht es CSIRO, die massive Rechenaufgabe der Aggregation, Filterung, Aufbereitung und Verarbeitung von Daten von 131.000 Antennen in Echtzeit zu bewältigen. Die 460 Gbit/s HBM2-Bandbreite im Signalverarbeitungs-Cluster wird von 420 Alveo U55C-Karten bedient, die vollständig über P4-fähige 100 Gbit/s-Switches miteinander vernetzt sind. Der Alveo U55C-Cluster bietet Verarbeitungsleistung mit einem Gesamtdurchsatz von 15 Tb/s bei kompakter Leistung und kosteneffizienter Grundfläche. CSIRO stellt jetzt ein beispielhaftes Alveo-Referenzdesign fertig, um anderen Radioastronomen oder angrenzenden Branchen zu helfen, denselben Erfolg zu erzielen.
Ein weiteres Anwendungsbeispiel ist die Crash-Simulationssoftware Ansys LS-DYNA, die von fast jedem Automobilunternehmen weltweit verwendet wird. Der Entwurf von Sicherheits- und Struktursystemen hängt von der Leistung von Modellen ab, da sie die Kosten für physikalische Crashtests mit computergestützten Simulationen der Finite-Elemente-Methode (FEM) senken. FEM-Löser sind die primären Algorithmen, die Simulationen mit Hunderten von Millionen Freiheitsgraden antreiben. Diese enormen Algorithmen können in rudimentärere Löser wie PCG, Sparse Matrizen und ICCG unterteilt werden. Durch die horizontale Skalierung über viele Alveo-Karten mit hyperparallelem Datenpipelining kann LS-DYNA die Leistung im Vergleich zu x86-CPUs um mehr als das Fünffache beschleunigen. Dies führt zu mehr Arbeit pro Taktzyklus in einer Alveo-Pipeline, wobei LS-DYNA-Kunden von bahnbrechenden Simulationszeiten profitieren. „Im Geiste unermüdlicher Innovation freuen wir uns über die Zusammenarbeit mit Xilinx, um die Finite-Elemente-Solver, die 90 % des Rechenaufwands für implizite Mechanik darstellen können, in unserer LS-DYNA-Simulationsanwendung erheblich zu beschleunigen“, sagte Wim Slagter , Direktor für strategische Partnerschaften bei Ansys. „Wir freuen uns darauf, dass die Beschleunigung von Xilinx uns bei unserer Mission unterstützt, Innovatoren bei der Entwicklung der Zukunft zu unterstützen.“
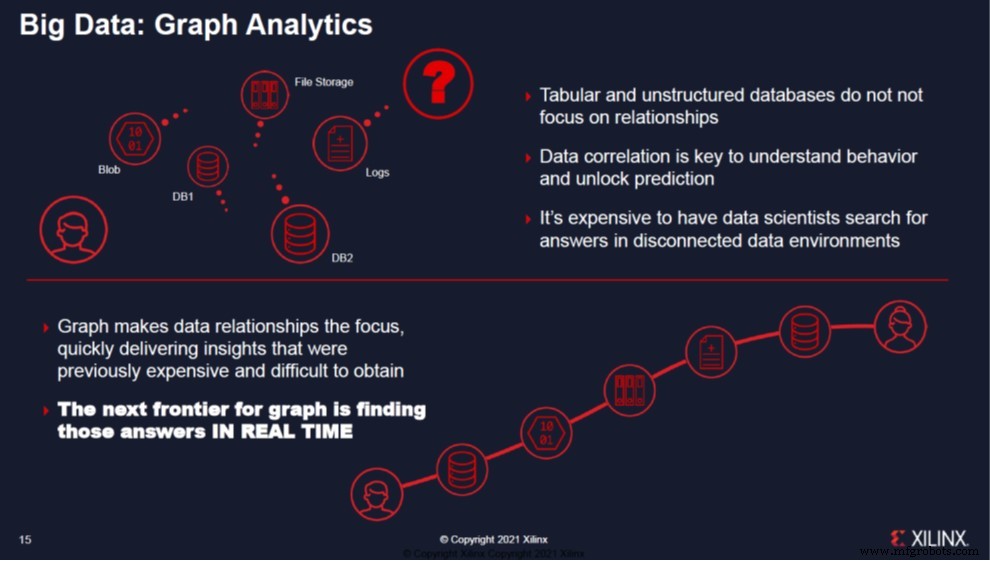
Xilinx nannte ein drittes Beispiel, das von TigerGraph, einem Anbieter einer führenden Plattform zur Graphanalyse. Das Unternehmen verwendet mehrere Alveo U55C-Karten, um die beiden produktivsten Algorithmen zu clustern und zu beschleunigen, die grafikbasierte Empfehlungs- und Clustering-Engines steuern. Graphdatenbanken sind eine disruptive Plattform für Data Scientists. Diagramme übernehmen Daten aus Silos und fokussieren die Beziehungen zwischen den Daten. Die nächste Grenze für Graphen besteht darin, diese Antworten in Echtzeit zu finden. Alveo U55C beschleunigt die Abfragezeiten und Vorhersagen für Empfehlungsmaschinen von Minuten auf Millisekunden. Durch die Verwendung mehrerer U55C-Karten zum Skalieren von Analysen beschleunigen die überlegene Rechenleistung und Speicherbandbreite die Grafikabfragegeschwindigkeiten im Vergleich zu CPU-basierten Clustern bis zu 45-mal schneller. Die Qualität der Scores steigt ebenfalls um bis zu 35 %, was zu einem größeren Vertrauen führt und falsch positive Ergebnisse drastisch auf niedrige einstellige Werte reduziert.
Die Alveo U55C-Karte ist derzeit auf der Xilinx-Website und über autorisierte Xilinx-Händler erhältlich. Es steht auch zur Evaluierung über öffentliche Cloud-basierte FPGA-as-a-Service-Anbieter sowie ausgewählte Colocation-Rechenzentren für private Vorschauen zur Verfügung. Clustering ist jetzt für private Vorschauen verfügbar. Die allgemeine Verfügbarkeit wird voraussichtlich im zweiten Quartal des nächsten Jahres erfolgen.
Eingebettet
- Siemens ergänzt Veloce für nahtlose hardwaregestützte Verifizierung
- TI:BAW-Resonatortechnologie ebnet den Weg für die Kommunikation der nächsten Generation
- DATENMODUL:neue Verbindungstechnologie für Großserienprojekte
- Cervoz:robuste SSD in Militärqualität für geschäftskritische Anwendungen
- CEVA:KI-Prozessor der zweiten Generation für tiefe neuronale Netzwerk-Workloads
- Kontron:neuer Embedded Computing Standard COM HPC
- acceed:I/O-Module für skalierbare Datenkommunikation
- Vier große Herausforderungen für das industrielle Internet der Dinge
- Wird Big Data ein Allheilmittel für marode Gesundheitsbudgets sein?
- Big Data vs. künstliche Intelligenz