


Databus vs. Database:Die 6 Fragen, die sich jeder IIoT-Entwickler stellen muss

Das Industrial Internet of Things (IIoT) steckt voller verwirrender Begriffe. Das ist unvermeidlich; Trotz der Wiederverwendung bekannter Konzepte in Computern und Systemen ist das IIoT eine grundlegende Veränderung in der Art und Weise, wie die Dinge funktionieren. Grundlegende Veränderungen erfordern grundlegend neue Konzepte. Eines der wichtigsten ist das Konzept eines "Datenbusses".
Die demnächst erscheinende IIC-Referenzarchitekturversion 2 enthält ein neues Muster, das als "geschichteter Datenbus"-Muster bezeichnet wird. Ich kann jetzt nicht mehr viel über die IIC-Version sagen, aber der Dokumentationsprozess war großartig, um klare Definitionen zu erzielen.
Die Datenbusdefinition lautet:
Ein Datenbus ist eine datenzentrierte Informationsaustauschtechnologie, die einen virtuellen, globalen Datenraum implementiert. Softwareanwendungen lesen und aktualisieren Einträge in einem globalen Datenraum. Updates werden über einen Publish-Subscribe-Kommunikationsmechanismus zwischen Anwendungen ausgetauscht.
Hauptmerkmale eines Datenbusses sind:
- die Teilnehmer/Anwendungen greifen direkt auf die Daten zu,
- die Infrastruktur versteht und kann die Daten daher selektiv filtern, und
- die Infrastruktur legt Regeln und Garantien für Quality of Service (QoS)-Parameter wie Rate, Zuverlässigkeit und Sicherheit des Datenflusses fest.
Natürlich erzeugen neue Konzepte Fragen. Einige der besten Fragen kamen von einem Architekten eines großen Datenbankunternehmens. Normalerweise versuchen wir, das Datenbus-Konzept aus der Perspektive eines Netzwerk- oder Software-Architekten zu erklären. Aber Data Science ist vielleicht ein besserer Ansatz. Sowohl Datenbanken als auch Datenbusse sind schließlich Data-Science-Konzepte.
Schauen wir uns die 6 häufigsten Fragen an.
Frage 1:Wie unterscheidet sich ein Datenbus von einer Datenbank (jeglicher Art)?
Kurze Antwort:Eine Datenbank implementiert datenzentrierte Speicherung. Es rettet altes Informationen, die Sie später suchen können indem Sie Eigenschaften der gespeicherten Daten in Beziehung setzen. Ein Datenbus implementiert datenzentrierte Interaktion. Es verwaltet die Zukunft Informationen, indem Sie filtern nach Eigenschaften der eingehenden Daten.
Lange Antwort:Datenzentrierung kann durch diese Eigenschaften definiert werden:
- Die Schnittstelle sind die Daten. Es gibt keine künstlichen Wrapper oder Blocker für diese Schnittstelle wie Nachrichten, Objekte, Dateien oder Zugriffsmuster.
- Die Infrastruktur versteht diese Daten. Dies ermöglicht Filtern/Suchen, Tools und Selektivität. Es entkoppelt Anwendungen von den Daten und nimmt dadurch einen Großteil der Komplexität aus den Anwendungen.
- Das System verwaltet die Daten und legt Regeln für den Datenaustausch zwischen Anwendungen fest. Dies liefert einen Begriff von "Wahrheit". Es ermöglicht Datenlebensdauern, Datenmodellabgleich, CRUD-Schnittstellen usw.
Eine relationale Datenbank ist eine datenzentrierte Speichertechnologie. Vor Datenbanken waren Speichersysteme Dateien mit anwendungsdefinierter (Ad-hoc-)Struktur. Eine Datenbank ist auch eine Datei, aber eine sehr spezielle Datei. Eine Datenbank weiß, wie die Daten zu interpretieren sind und erzwingt die Zugriffskontrolle. Eine Datenbank definiert somit "Wahrheit" für das System; Daten in der Datenbank können nicht beschädigt werden oder verloren gehen.
Durch die Durchsetzung einfacher Regeln, die das Datenmodell steuern, sorgen Datenbanken für Konsistenz. Da die Daten der Suche und dem Abruf durch alle Benutzer ausgesetzt sind, erleichtern Datenbanken die Systemintegration erheblich. Durch das Auffinden von Daten und Schemas ermöglichen Datenbanken auch generische Tools zum Überwachen, Messen und Mining von Informationen.
Wie eine Datenbank versteht die datenzentrierte Middleware (ein Datenbus) den Inhalt der übertragenen Daten. Der Datenbus sendet auch Nachrichten, aber er sendet sehr spezielle Nachrichten. Es sendet nur Nachrichten, die speziell zur Aufrechterhaltung des Zustands benötigt werden. Klare Regeln regeln den Zugriff auf die Daten, wie sich Daten im System ändern und wann Teilnehmer Updates erhalten. Wichtig ist, dass nur die Infrastruktur Nachrichten sendet. Für die Anwendungen sieht das System wie ein kontrollierter globaler Datenraum aus. Anwendungen interagieren direkt mit Daten und Daten "Quality of Service" (QoS)-Eigenschaften wie Alter und Rate. Es gibt kein Bewusstsein oder Konzept der "Nachricht" auf Anwendungsebene. Programme, die einen Datenbus verwenden, lesen und schreiben Daten, sie senden und empfangen keine Nachrichten.
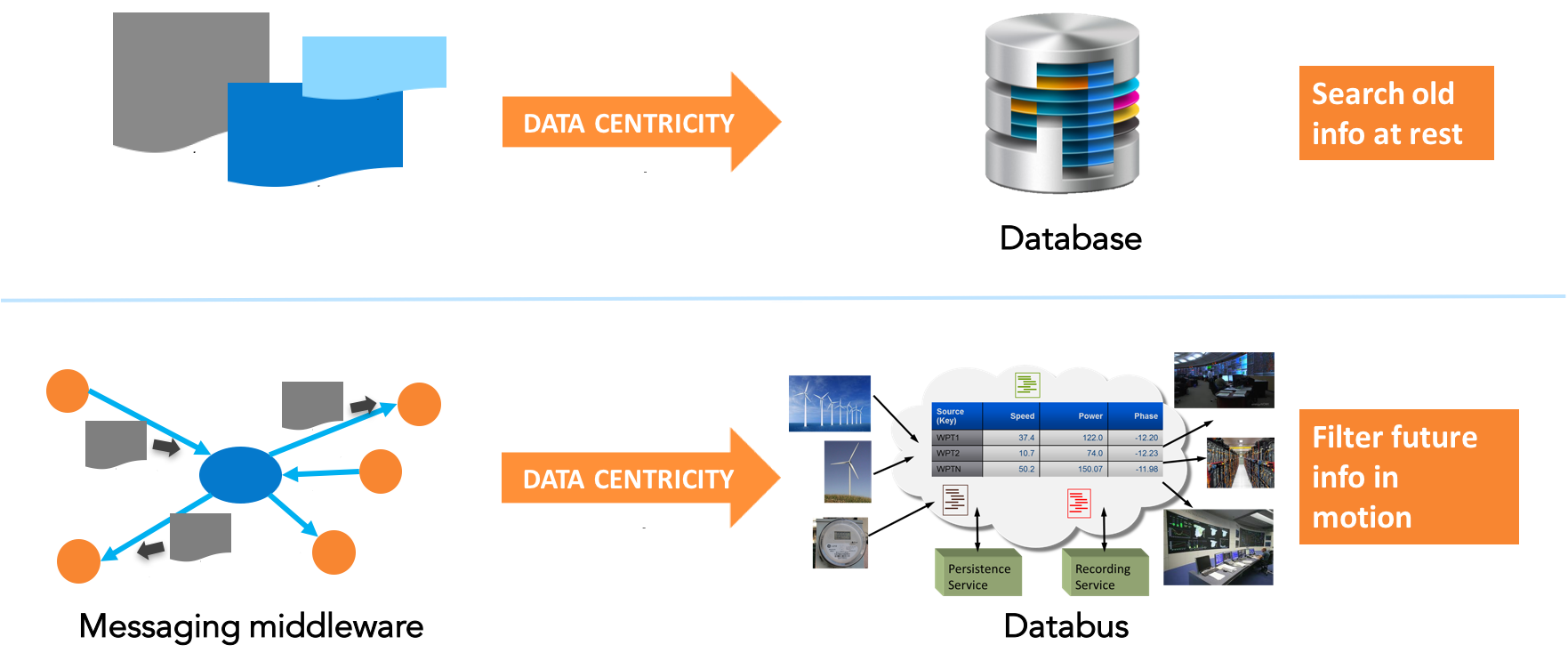
Mit Kenntnis der Struktur und Anforderungen an die Daten kann die Datenbus-Infrastruktur beispielsweise Informationen filtern und auswählen, wann oder ob Aktualisierungen durchgeführt werden sollen. Die Infrastruktur selbst kann QoS wie Aktualisierungsrate, Zuverlässigkeit und garantierte Benachrichtigung über die Peer-Lebendigkeit steuern. Die Infrastruktur kann Datenflüsse erkennen und diese Anwendungen und generischen Tools gleichermaßen anbieten. Dieses Wissen über den Datenstatus in einem verteilten System ist eine klare Definition von "Wahrheit". Wie bei Datenbanken macht die Infrastruktur die Daten, sowohl die Struktur als auch den Inhalt, anderen Anwendungen zugänglich. Diese zugängliche Quelle der Wahrheit erleichtert die Systemintegration erheblich. Es ermöglicht auch generische Tools und Dienste, die den Informationsfluss überwachen und anzeigen, Nachrichten weiterleiten und das Caching verwalten.
Frage 2:"Softwareanwendungen lesen und aktualisieren Einträge in einem globalen Datenraum. Updates werden zwischen Anwendungen über einen Publish-Subscribe-Kommunikationsmechanismus geteilt." Bedeutet das, dass dies eine Datenbank ist, mit der Sie über eine Pub-Sub-Schnittstelle interagieren?
Kurze Antwort:Nein, es gibt keine Datenbank. Eine Datenbank impliziert eine Speicherung:Die Daten befinden sich physisch irgendwo. Ein Datenbus implementiert ein rein virtuelles Konzept, das als "globaler Datenraum" bezeichnet wird.
Lange Antwort:Der Datenraum des Datenbusses definiert, wie mit zukünftigen Informationen umgegangen wird. Wenn "Sie" beispielsweise ein Kreuzungscontroller sind, können Sie Updates von Fahrzeugen im Umkreis von 200 m um Ihre Position abonnieren. Diese Updates werden Ihnen dann zugestellt, sollte sich jemals ein Fahrzeug nähern. Die Zustellung ist in vielerlei Hinsicht garantiert (Start innerhalb von 0,01 Sek., aktualisiert 100x/Sek., zuverlässig usw.). Beachten Sie, dass die Daten möglicherweise nie gespeichert werden. (Obwohl einige QoS-Einstellungen, wie z allgemein) vom Datenbus gespeichert...es wird gerade geliefert.
Frage 3:"Die Teilnehmer/Anwendungen haben eine direkte Schnittstelle zu den Daten." Könnten Sie näher erläutern, was das bedeutet?
Mit "nachrichtenzentrierter" Middleware schreiben Sie eine Anwendung, die in Nachrichten verpackte Daten an eine andere Anwendung sendet. Sie können dies beispielsweise tun, indem Sie Clients Daten an Server senden lassen. Beide Enden müssen etwas über das andere Ende wissen, normalerweise einschließlich Dinge wie das Schema, aber auch wahrscheinlich angenommene Eigenschaften der Daten wie "es ist weniger als 0,01 Sekunden alt" oder "es wird 100x/Sekunde kommen" oder zumindest dass es ein anderes lebendes Ende gibt, zB der Server läuft. All diese angenommenen Eigenschaften sind vollständig im Anwendungscode verborgen, was die Wiederverwendung, Systemintegration und Interoperabilität sehr erschwert.
Bei einem Datenbus müssen Sie nichts über die Quellanwendungen wissen. Sie machen Ihren Datenbedarf klar und der Datenbus liefert ihn. Somit interagiert bei einem Datenbus jede Anwendung nur mit dem Datenraum. Als Anwendung schreiben Sie einfach in den Datenraum oder lesen mit einer CRUD-Schnittstelle aus dem Datenraum. Natürlich benötigen Sie möglicherweise etwas QoS von diesem Datenraum, z. Sie müssen Ihre Daten 100x pro Sekunde aktualisieren. Der Datenraum selbst (der Datenbus) garantiert Ihnen, dass Sie diese Daten erhalten (oder einen Fehler anzeigen). Sie müssen nicht wissen, ob es nur eine oder 27 redundante Quellen für diese Daten gibt oder ob sie über ein Netzwerk oder gemeinsam genutzten Speicher kommen oder ob es sich um ein C-Programm unter Linux oder ein C#-Programm unter Windows handelt. Alle Interaktionen erfolgen mit Ihrer eigenen Ansicht des Datenraums. Es ist beispielsweise auch sinnvoll, Daten in einen Space ohne Empfänger zu schreiben. In diesem Fall kann der Datenbus, abhängig von Ihren QoS-Einstellungen, möglicherweise überhaupt nichts tun oder Informationen für eine spätere Lieferung zwischenspeichern.
Beachten Sie, dass sowohl die Datenbank- als auch die Datenbus-Technologie die Anwendung-Anwendung-Interaktion durch die Anwendung-Daten-Anwendung-Interaktion ersetzen. Diese Abstraktion ist absolut kritisch. Es entkoppelt Anwendungen und erleichtert die Skalierung, Interoperabilität und Systemintegration erheblich. Der Unterschied beste
Internet der Dinge-Technologie
- Stellen Sie die richtigen Cloud-Fragen
- Sinn oder Nicht-Sinn:Die Vorteile des IIoT für Ihre Fabrik
- Fetch sagt, dass jede Maschine im IoT einen wirklich guten Agenten braucht
- Warum das Internet der Dinge künstliche Intelligenz braucht
- IIoT wird die Facility-Management-Branche stören, aber das ist in Ordnung!
- Demokratisierung des IoT
- Der Weg des IIoT beginnt mit der Remote-Telemetrie
- Galerie:10 Fragen, die Sie bei der Auswahl einer IIoT-Plattform stellen sollten
- Top 10 der IIoT-Plattformen
- Verändern Edge Computing und IIoT unser Denken über Daten?