


Best Practices für das Debuggen von Zephyr-basierten IoT-Anwendungen
Das Linux Foundation Zephyr Open Source Project hat sich zum Rückgrat vieler IoT-Projekte entwickelt. Zephyr bietet ein erstklassiges kleines, skalierbares Echtzeit-Betriebssystem (RTOS), das für ressourcenbeschränkte Geräte über mehrere Architekturen hinweg optimiert ist. Das Projekt hat derzeit 1.000 Mitwirkende und 50.000 Commits, die fortschrittliche Unterstützung für mehrere Architekturen aufbauen, darunter ARC, Arm, Intel, Nios, RISC-V, SPARC und Tensilica sowie mehr als 250 Boards.
Bei der Arbeit mit Zephyr sind einige wichtige Aspekte zu beachten, damit die Dinge verbunden bleiben und zuverlässig funktionieren. Entwickler können nicht alle Klassen von Problemen am Schreibtisch lösen und einige werden erst offensichtlich, wenn eine Geräteflotte wächst. Während sich Netzwerke und Netzwerkstacks weiterentwickeln, müssen Sie sicherstellen, dass Upgrades keine unnötigen Probleme mit sich bringen.
Betrachten Sie zum Beispiel eine Situation, in der wir mit GPS-Trackern konfrontiert waren, die zur Verfolgung von Nutztieren eingesetzt wurden. Das Gerät war ein sensorbasiertes Halsband mit geringem Platzbedarf. An einem bestimmten Tag durchstreifte das Tier von Mobilfunknetz zu Mobilfunknetz; Von Land zu Land; von Standort zu Standort. Durch eine solche Bewegung wurden schnell Fehlkonfigurationen und unerwartetes Verhalten aufgedeckt, das zu einem Stromausfall und damit zu großen wirtschaftlichen Verlusten führen konnte. Wir mussten nicht nur über ein Problem Bescheid wissen, wir mussten auch wissen, warum es passiert ist und wie wir es beheben können. Bei der Arbeit mit angeschlossenen Geräten sind Fernüberwachung und -debuggen von entscheidender Bedeutung, um einen sofortigen Einblick in die Fehler, die nächsten besten Schritte zur Behebung der Situation und letztendlich die Einrichtung und Aufrechterhaltung des normalen Betriebs zu erhalten.
Wir verwenden eine Kombination aus Zephyr und der Cloud-basierten Plattform zur Gerätebeobachtung Memfault, um die Geräteüberwachung und -aktualisierung zu unterstützen. Unserer Erfahrung nach können Sie beides nutzen, um Best Practices für die Fernüberwachung mithilfe von Neustarts, Watchdogs, Fehler/Asserts und Konnektivitätsmetriken festzulegen.
Einrichten einer Observability-Plattform
Memfault ermöglicht es Entwicklern, Firmware aus der Ferne zu überwachen, zu debuggen und zu aktualisieren, was uns ermöglicht:
- Vermeiden Sie Produktionsstopps zugunsten von Minimum Viable Product und Day-0-Updates
- Überwachen Sie kontinuierlich den Gesamtzustand des Geräts
- Push-Updates und Patches, bevor die meisten Endbenutzer Probleme bemerken
Das SDK von Memfault lässt sich einfach integrieren, um Datenpakete für die Cloud-Analyse und die Problemdeduplizierung zu sammeln. Es funktioniert wie ein typisches Zephyr-Modul, bei dem Sie es zu Ihrer Manifestdatei hinzufügen.
#west.yml [ ... ] - Name:memfault-firmware-sdk URL:https://github.com/memfault/memfault-firmware-sdk Pfad:modules/memfault-firmware-sdk Überarbeitung:Meister #prj.conf CONFIG_MEMFAULT=y CONFIG_MEMFAULT_HTTP_ENABLE=y
Erster Schwerpunktbereich:Neustarts
Angenommen, Sie sehen einen erheblichen Anstieg der Zurücksetzungen auf Ihrem Gerät. Dies ist oft ein Frühindikator dafür, dass sich etwas in der Topologie geändert hat oder Geräte aufgrund von Hardwaredefekten Probleme haben. Dies sind die kleinsten Informationen, die Sie sammeln können, um einen Einblick in den Gerätezustand zu erhalten, und es hilft, dies in zwei Teilen zu betrachten:Hardware-Resets und Software-Resets.
Hardware-Resets sind oft auf Hardware-Watchdogs und Brownouts zurückzuführen. Software-Resets können durch Firmware-Updates, Asserts oder vom Benutzer initiiert werden.
Nachdem wir identifiziert haben, welche Arten von Zurücksetzungen stattfinden, können wir erkennen, ob es Probleme gibt, die die gesamte Flotte betreffen oder ob sie auf einen kleinen Prozentsatz der Geräte beschränkt sind.
Grund für Neustart aufzeichnen
ungültig fw_update_finish(void) { // ... memfault_reboot_tracking_mark_reset_imminent(kMfltRebootReason_FirmwareUpdate, ...); sys_reboot(0); } Zephyr verfügt über einen Mechanismus zum Registrieren von Regionen, die bei einem Reset, in den sich Memfault einklinkt, erhalten bleiben. Wenn Sie die Plattform neu starten möchten, empfehlen wir Ihnen, direkt vor dem Start zu speichern. Wenn Sie die Plattform neu starten, notieren Sie den Grund für Ihren Neustart – in diesem Fall ein Firmware-Update – und nennen Sie es dann Zephyr sys_reboot.
Erfassen von Geräte-Resets auf Zephyr
Init-Handler registrieren, um Boot-Informationen zu lesen
statisch int record_reboot_reason() { // 1. Grundregister für Hardware-Reset lesen. (Überprüfen Sie das MCU-Datenblatt für den Registernamen) // 2. Erfassen Sie den Grund für das Zurücksetzen der Software aus dem Noinit-RAM // 3. Daten zur Aggregation an den Server senden } SYS_INIT(record_reboot_reason, ANWENDUNG, CONFIG_KERNEL_INIT_PRIORITY_DEFAULT); Sie können ein Makro einrichten, das Systeminformationen vor dem Zurücksetzen über das MCU-Reset-Grundregister erfasst. Wenn das Gerät neu gestartet wird, registriert Zephyr Handler mithilfe des system_int-Makros. MCU-Reset-Ursachenregister haben alle leicht unterschiedliche Namen und alle sind nützlich, da Sie sehen können, ob Hardwareprobleme oder -defekte vorliegen.
Beispiel:Netzteilproblem
Sehen wir uns ein Beispiel an, wie die Fernüberwachung wichtige Einblicke in den Zustand der Flotte geben kann, indem sie Neustarts und die Stromversorgung untersucht. Hier sehen wir, wie eine kleine Anzahl von Geräten für mehr als 12.000 Neustarts verantwortlich ist (Abbildung 1).
Klicken für Bild in voller Größe

Abbildung 1:Beispiel für ein Problem mit der Stromversorgung, Diagramm der Neustarts über 15 Tage. (Quelle:Autoren)
- 12.000 Geräteneustarts pro Tag – viel zu viele
- 99 % der Neustarts werden von 10 Geräten beigetragen
- Schlechter mechanischer Teil, der zu ständigen Neustarts des Geräts beiträgt
In diesem Fall werden einige Geräte 1.000 Mal am Tag neu gestartet, wahrscheinlich aufgrund eines mechanischen Problems (schlechtes Teil, schlechter Batteriekontakt oder verschiedene chronische Frequenzprobleme).
Sobald Geräte in Produktion sind, können Sie eine Reihe dieser Probleme durch Firmware-Updates beheben. Durch die Bereitstellung eines Updates können Sie Hardwaredefekte umgehen und die Notwendigkeit umgehen, Geräte wiederherzustellen und zu ersetzen.
Zweiter Schwerpunkt:Watchdogs
Bei der Arbeit mit verbundenen Stacks ist ein Watchdog die letzte Verteidigungslinie, um ein System wieder in einen sauberen Zustand zu versetzen, ohne das Gerät manuell zurückzusetzen. Hängen können aus vielen Gründen auftreten, z. B.
- Konnektivitäts-Stack-Blöcke bei send()
- Unendliche Wiederholungsschleifen
- Blockaden zwischen Aufgaben
- Korruption
Hardware-Watchdogs sind ein dediziertes Peripheriegerät in der MCU, das regelmäßig „gefüttert“ werden muss, um zu verhindern, dass sie das Gerät zurücksetzen. Software-Watchdogs sind in der Firmware implementiert und werden vor dem Hardware-Watchdog ausgelöst, um die Erfassung des Systemzustands zu ermöglichen, der zum Hardware-Watchdog führt
Zephyr verfügt über eine Hardware-Watchdog-API, bei der alle MCUs die generische API durchlaufen können, um den Watchdog in der Plattform einzurichten und zu konfigurieren. (Weitere Informationen finden Sie unter Zephyr API:zephyr/include/drivers/watchdog.h)
// ... ungültig start_watchdog(void) { // Konsultieren Sie den Gerätebaum für verfügbaren Hardware-Watchdog s_wdt =device_get_binding(DT_LABEL(DT_INST(0, nordic_nrf_watchdog))); struct wdt_timeout_cfg wdt_config ={ /* SoC zurücksetzen, wenn der Watchdog-Timer abläuft. */ .flags =WDT_FLAG_RESET_SOC, /* Watchdog nach maximalem Fenster ablaufen lassen */ .window.min =0U, .window.max =WDT_MAX_WINDOW, }; s_wdt_channel_id =wdt_install_timeout(s_wdt, &wdt_config); const uint8_t options =WDT_OPT_PAUSE_HALTED_BY_DBG; wdt_setup(s_wdt, Optionen); // TODO:Starten Sie einen Software-Watchdog } ungültig feed_watchdog(void) { wdt_feed(s_wdt, s_wdt_channel_id); // TODO:Software-Watchdog füttern } Lassen Sie uns anhand dieses Beispiels des Nordic nRF9160 einige Schritte durchgehen.
- Gehen Sie zum Gerätebaum und richten Sie den Nordic nRF Watchtime-Ordner ein.
- Setzen Sie die Konfigurationsoptionen für den Watchdog über die verfügbare API.
- Installieren Sie den Watchdog.
- Füttern Sie den Watchdog regelmäßig, wenn das Verhalten wie erwartet ausgeführt wird. Manchmal geschieht dies von den Aufgaben mit der niedrigsten Priorität aus. Wenn das System hängen bleibt, wird ein Neustart ausgelöst.
Wenn Sie Memfault auf Zephyr verwenden, können Sie Kernel-Timer verwenden, die von einem Timer-Peripheriegerät betrieben werden. Sie können das Software-Watchdog-Timeout so einstellen, dass es Ihrem Hardware-Watchdog voraus ist (stellen Sie beispielsweise Ihren Hardware-Watchdog auf 60 Sekunden und Ihren Software-Watchdog auf 50 Sekunden ein). Wenn der Callback jemals aufgerufen wird, wird ein Assert ausgelöst, der Sie durch den Zephyr-Fehlerhandler führt und Informationen darüber erhält, was zu dem Zeitpunkt geschah, als das System feststeckte.
Beispiel:SPI-Treiber hängt fest
Wenden wir uns noch einmal einem Beispiel für ein Problem zu, das nicht in der Entwicklung steckt, sondern im Feld auftaucht. In Abbildung 2 sehen Sie das Timing, die Fakten und die Verschlechterung der SPI-Treiberchips.
Klicken für Bild in voller Größe
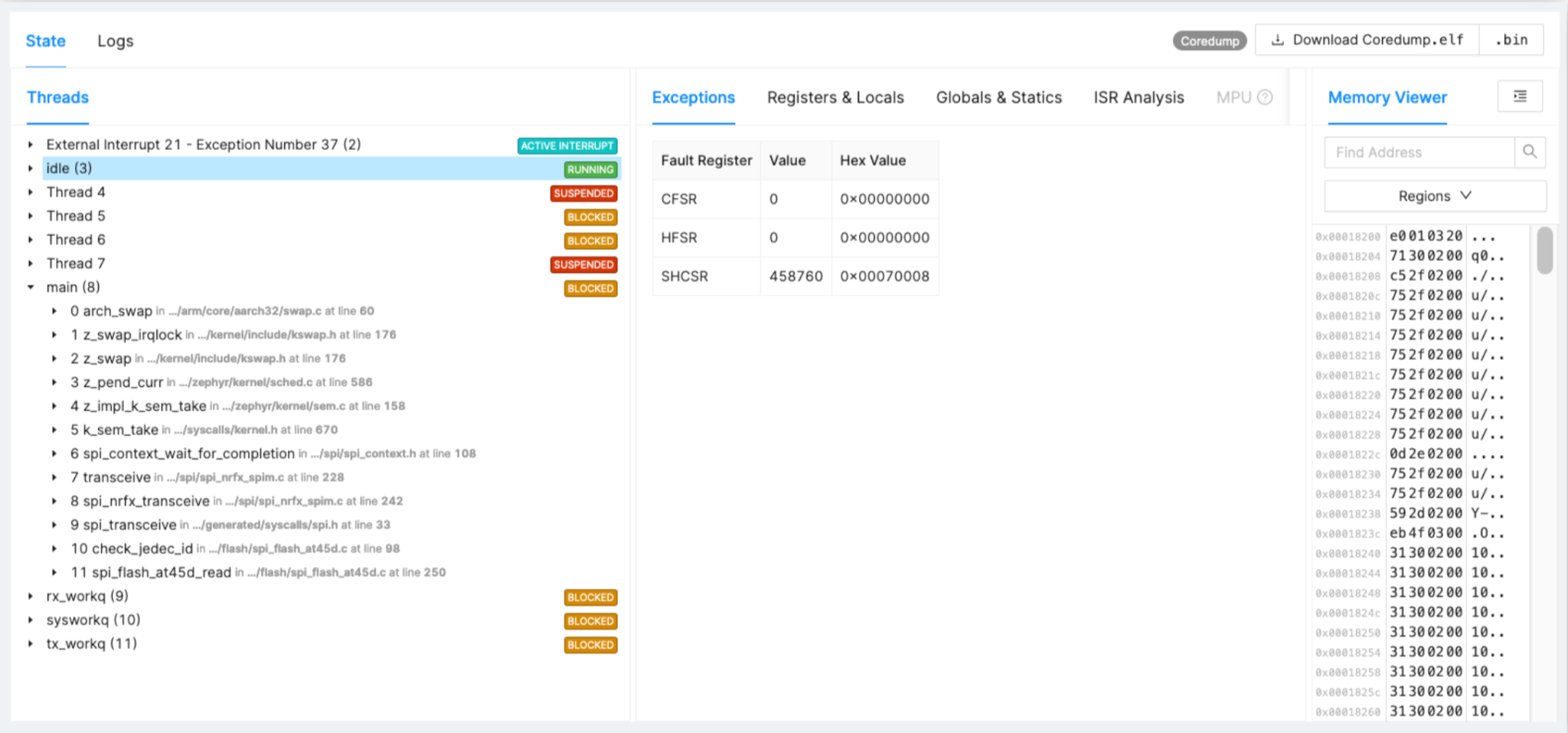
Abbildung 2:Beispiel für hängengebliebenen SPI-Treiber. (Quelle:Autoren)
- SPI-Flash verschlechtert sich im Laufe der Zeit, falsches Timing der Kommunikation
- Nach 16 Monaten Feldeinsatz bei 1 % der Geräte nachvollzogen
- Treiberkorrektur und Rollout mit der nächsten Version
Bei Flash können Sie nach einem Jahr im Feld feststellen, dass es plötzlich zu Fehlern kommt, die auf SPI-Transaktionen oder verschiedene Code-Teile zurückzuführen sind. Die vollständige Verfolgung hilft Ihnen, die Ursache zu finden und eine Lösung zu entwickeln.
Der Watchdog unten (Abbildung 3) startet den Zephyr-Fehlerhandler.
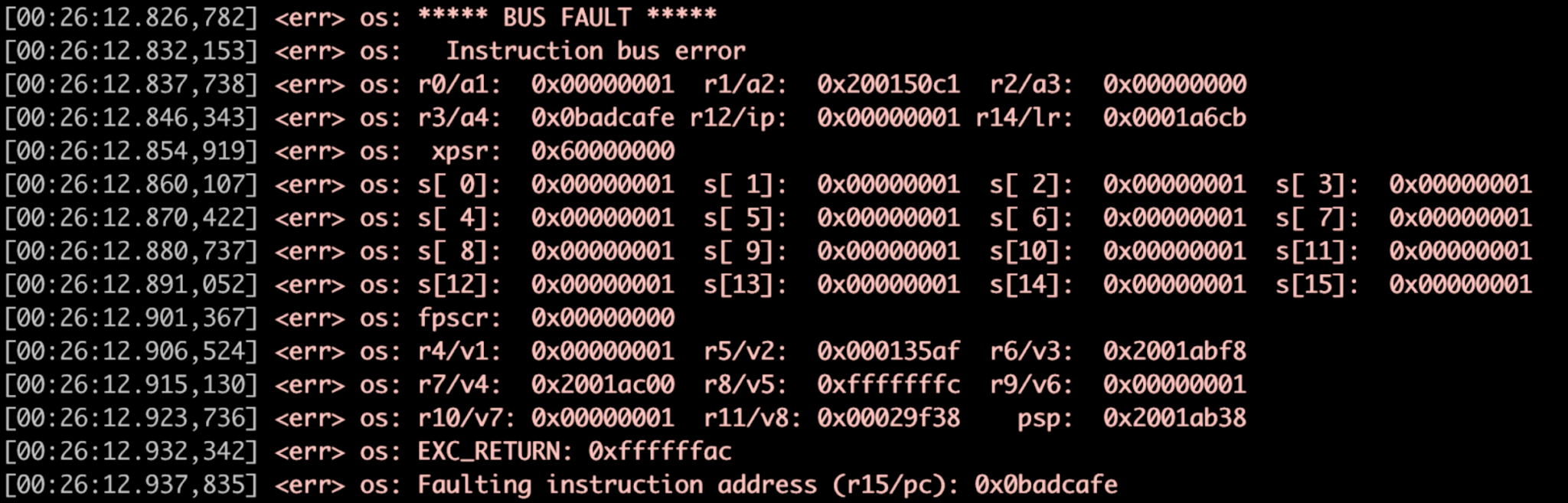
Abbildung 3:Fehlerbehandlungsbeispiel, Registerdump. (Quelle:Autoren)
Dritter Bereichsfokus:Fehler/Asserts:
Die dritte zu verfolgende Komponente sind Fehler und Bestätigungen. Wenn Sie jemals ein lokales Debugging durchgeführt oder einige eigene Funktionen erstellt haben, haben Sie wahrscheinlich einen ähnlichen Bildschirm zum Registerstatus gesehen, wenn ein Fehler auf der Plattform aufgetreten ist. Diese können folgende Ursachen haben:
- Behauptungen oder
- Zugriff auf schlechten Speicher
- durch Null dividieren
- falsche Verwendung eines Peripheriegeräts
Hier ist ein Beispiel für einen Fehlerbehandlungsablauf, der auf Cortex-M-Mikrocontrollern auf Zephyr angewendet wird.
ungültig network_send(void) { const size_t package_size =1500; void *buffer =z_malloc(packet_size); // NULL-Prüfung fehlt! memcpy(buffer, 0x0, packet_size); // ... } ↓ungültig network_send(void) { const size_t package_size =1500; void *buffer =z_malloc(packet_size); // NULL-Prüfung fehlt! memcpy(buffer, 0x0, packet_size); // ... } ↓bool memfault_coredump_save(const sMemfaultCoredumpSaveInfo *save_info) { // Registerstatus speichern // _Kernel- und Aufgabenkontexte speichern // Ausgewählte .bss- und .data-Regionen speichern } ↓ungültig sys_arch_reboot(int-Typ) { // ... } Wenn ein Assert oder ein Fehler gestartet wird, wird ein Interrupt ausgelöst und ein Fehlerhandler in Zephyr aufgerufen, der den Registerzustand zum Zeitpunkt des Absturzes bereitstellt.
Das Memfault SDK fügt sich automatisch in den Fehlerbehandlungsablauf ein und speichert kritische Informationen in der Cloud, einschließlich des Registerstatus, des Status des Kernels und eines Teils aller Tasks, die zum Zeitpunkt des Absturzes auf dem System ausgeführt wurden.
Es gibt drei Dinge, auf die Sie achten müssen, wenn Sie lokal oder remote debuggen:
- Das Cortex M-Fehlerstatusregister sagt Ihnen, warum die Plattform behauptet oder fehlerhaft war.
- Memfault stellt die genaue Codezeile wieder her, die das System vor dem Absturz ausgeführt hat, sowie den Status aller anderen Aufgaben.
- Sammle den _kernel Struktur im Zephyr RTOS, um den Scheduler zu sehen, und wenn es sich um eine verbundene Anwendung handelt, den Status der Bluetooth- oder LTE-Parameter.
Vierter Fokusbereich:Tracking-Metriken für die Gerätebeobachtbarkeit
Mithilfe von Tracking-Metriken können Sie ein Muster für die Vorgänge auf Ihrem System erstellen und Vergleiche zwischen Ihren Geräten und Ihrer Flotte anstellen, um zu verstehen, welche Änderungen sich auswirken.
Einige nützliche Metriken sind:
- CPU-Auslastung
- Konnektivitätsparameter
- Wärmenutzung
Mit dem Memfault SDK können Sie Metriken auf Zephyr mit zwei Codezeilen hinzufügen und mit deren Definition beginnen:
- Messwert definieren
MEMFAULT_METRICS_KEY_DEFINE( LteDisconnect, kMemfaultMetricType_Unsigned)
- Messwert im Code aktualisieren
ungültig lte_disconnect(void) { memfault_metrics_heartbeat_add( MEMFAULT_METRICS_KEY(LteDisconnect), 1); //... } Memfault-SDK + Cloud
- Serialisiert und komprimiert Messwerte für den Transport
- Indiziert Metriken nach Gerät und Firmware-Version
- Stellt eine Weboberfläche zum Durchsuchen von Metriken nach Gerät und für die gesamte Flotte bereit
Dutzende von Metriken können gesammelt und nach Gerät und Firmware-Version indiziert werden. Ein paar Beispiele:
- NB-IoT/LTE-M-Basiskonnektivität: Sehen Sie, wie sich ein Modem auf die Batterielebensdauer auswirkt, entweder durch Anschließen oder Anschließen.
- Tracking von Basisstationen und PSM in NB-IoT/LTE-M: Die Qualität des mobilen Signals kann schmerzhaft sein und die Batterielebensdauer beeinträchtigen, wenn sie nicht verwaltet wird. Erstellen Sie Metriken für Netzwerkstatus, Ereignisse, Mobilfunkmastinformationen, Einstellungen, Timer und mehr. Überwachen Sie auf Änderungen und verwenden Sie Benachrichtigungen.
- Testen großer Flotten: Unerwartet große Datenmengen können die Kosten für die Gerätekonnektivität erhöhen und helfen, Ausreißer zu erkennen.
Beispiel:NB-IoT/LTE-M-Datengröße
Klicken für Bild in voller Größe
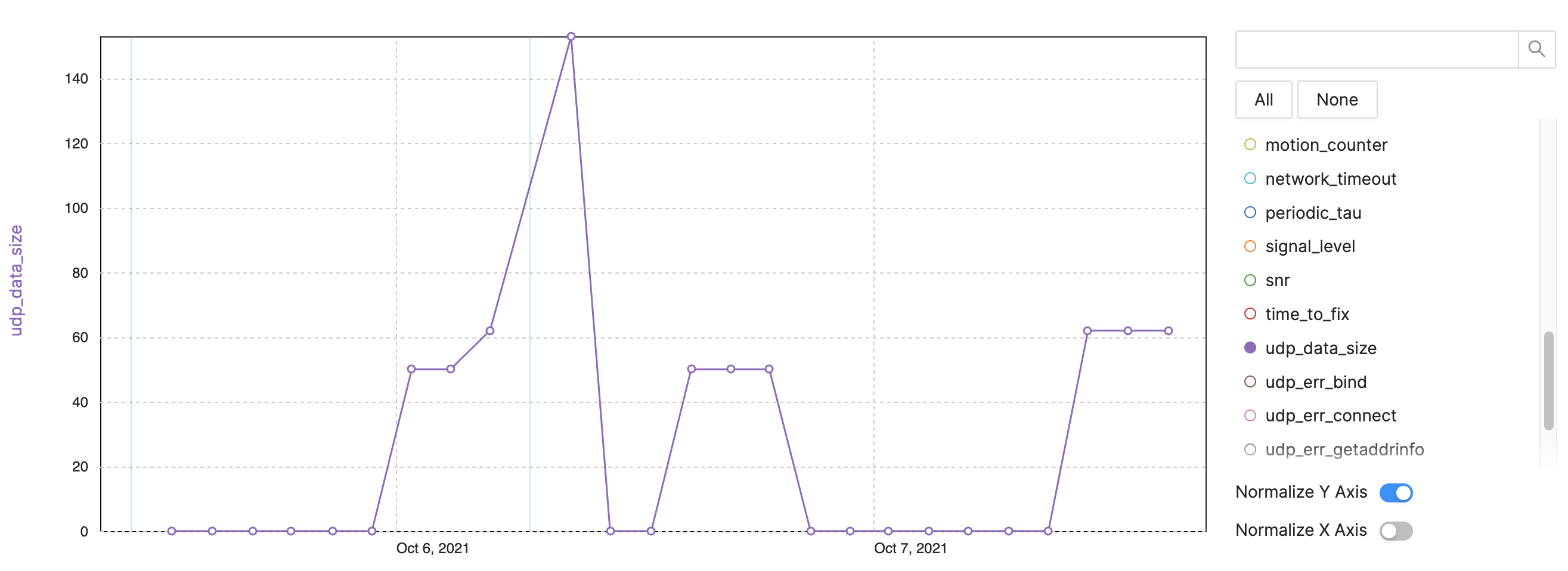
Abbildung 4:Tracking-Metriken für die Beobachtbarkeit von Geräten – NB-IoT-Beispiel, LTE-M-Datengröße. (Quelle:Autoren)
- UDP-Datengröße:Track-Bytes pro Sendeintervall (Abbildung 4)
- Nach dem Neustart werden mehr Daten gesendet
- Einige Pakete sind aufgrund weiterer Informationen oder Spuren größer
- Problem beim Datenverbrauch verfolgen
Schlussfolgerung
Mithilfe von Zephyr und Memfault können Entwickler eine Fernüberwachung implementieren, um die Funktionalität der angeschlossenen Geräte besser zu beobachten. Durch die Konzentration auf Neustarts, Watchdogs, Fehler/Zusicherungen und Konnektivitätsmetriken können Entwickler die Kosten und Leistung von IoT-Systemen optimieren.
Erfahren Sie mehr, indem Sie sich eine aufgezeichnete Präsentation vom Zephyr Developer Summit 2021 ansehen.
Internet der Dinge-Technologie
- Best Practices für synthetisches Monitoring
- Bidirektionale 1G-Transceiver für Dienstanbieter und IoT-Anwendungen
- ETSI will Standards für IoT-Anwendungen in der Notfallkommunikation festlegen
- IIC und TIoTA kooperieren bei IoT/Blockchain Best Practices
- NIST veröffentlicht Entwürfe von Sicherheitsempfehlungen für IoT-Hersteller
- Partnerschaft zielt auf endlose Batterielebensdauer von IoT-Geräten ab
- Die 3 besten Gründe für den Einsatz von IoT-Technologie für das Asset Management
- Warum das IoT als beste Plattform für die Umweltüberwachung betrachten?
- Beste Anwendungen für Druckluftsysteme
- Best Practices für das Fertigungsmarketing für 2019