


Wie analoges In-Memory-Computing die Leistungsherausforderungen der Edge-KI-Inferenz lösen kann
Machine Learning und Deep Learning sind bereits fester Bestandteil unseres Lebens. Anwendungen der künstlichen Intelligenz (KI) über Natural Language Processing (NLP), Bildklassifizierung und Objekterkennung sind tief in viele der von uns verwendeten Geräte eingebettet. Die meisten KI-Anwendungen werden über Cloud-basierte Engines bereitgestellt, die für ihre Zwecke gut funktionieren, z. B. um Wortvorhersagen beim Eingeben einer E-Mail-Antwort in Gmail zu erhalten.
So sehr wir die Vorteile dieser KI-Anwendungen genießen, dieser Ansatz bringt Datenschutz-, Verlustleistungs-, Latenz- und Kostenherausforderungen mit sich. Diese Herausforderungen können gelöst werden, wenn es eine lokale Verarbeitungsmaschine gibt, die eine teilweise oder vollständige Berechnung (Inferenz) am Ursprung der Daten selbst durchführen kann. Dies war mit herkömmlichen Implementierungen digitaler neuronaler Netze schwierig zu bewerkstelligen, bei denen der Speicher zu einem energiehungrigen Engpass wird. Das Problem kann mit Multi-Level-Speicher und der Verwendung einer analogen In-Memory-Rechenmethode gelöst werden, die es Verarbeitungsmaschinen ermöglicht, die viel niedrigeren Leistungsanforderungen von Milliwatt (mW) bis Mikrowatt (uW) für die Durchführung von KI-Inferenz bei . zu erfüllen am Rand des Netzwerks.
Herausforderungen des Cloud Computing
Wenn KI-Anwendungen über Cloud-basierte Engines bereitgestellt werden, muss der Benutzer einige Daten (freiwillig oder unfreiwillig) in Clouds hochladen, in denen Computing-Engines die Daten verarbeiten, Vorhersagen bereitstellen und die Vorhersagen nachgelagert an den Benutzer zur Nutzung senden.

Abbildung 1:Datenübertragung vom Edge in die Cloud. (Quelle:Microchip Technology)
Die mit diesem Prozess verbundenen Herausforderungen sind im Folgenden beschrieben:
- Datenschutz- und Sicherheitsbedenken: Bei immer eingeschalteten, immer wachsamen Geräten besteht die Gefahr, dass personenbezogene Daten (und/oder vertrauliche Informationen) missbraucht werden, entweder während des Hochladens oder während der Haltbarkeitsdauer in Rechenzentren.
- Unnötige Verlustleistung: Wenn jedes Datenbit in die Cloud geht, verbraucht es Strom von Hardware, Funkgeräten, Übertragung und möglicherweise unerwünschten Berechnungen in der Cloud.
- Latenz für Kleinserien-Inferenzen: Manchmal kann es eine Sekunde oder länger dauern, bis ein Cloud-basiertes System eine Antwort erhält, wenn die Daten vom Edge stammen. Für die menschlichen Sinne ist eine Latenz von mehr als 100 Millisekunden (ms) wahrnehmbar und kann störend sein.
- Datensparsamkeit muss Sinn machen: Sensoren sind überall, und sie sind sehr erschwinglich; Sie produzieren jedoch viele Daten. Es ist nicht wirtschaftlich, jedes Datenbit in die Cloud hochzuladen und es verarbeiten zu lassen.
Um diese Herausforderungen mit einer lokalen Verarbeitungsmaschine zu lösen, muss das neuronale Netzwerkmodell, das die Inferenzoperationen durchführt, zunächst mit einem bestimmten Datensatz für den gewünschten Anwendungsfall trainiert werden. Im Allgemeinen erfordert dies hohe Rechen- (und Speicher-) Ressourcen und arithmetische Gleitkommaoperationen. Daher muss der Trainingsteil einer Machine-Learning-Lösung immer noch in öffentlichen oder privaten Clouds (oder einer lokalen GPU-, CPU-, FPGA-Farm) mit einem Datensatz durchgeführt werden, um ein optimales neuronales Netzwerkmodell zu generieren. Sobald das neuronale Netzwerkmodell fertig ist, kann das Modell mit einer kleinen Rechenmaschine für eine lokale Hardware weiter optimiert werden, da das neuronale Netzwerkmodell keine Rückwärtsausbreitung für die Inferenzoperation benötigt. Eine Inferenz-Engine benötigt im Allgemeinen ein Meer von Multiply-Accumulate (MAC)-Engines, gefolgt von einer Aktivierungsschicht wie ReLU, Sigmoid oder Tanh, abhängig von der Komplexität des neuronalen Netzwerkmodells, und einer Pooling-Schicht zwischen den Schichten.
Die Mehrzahl der neuronalen Netzmodelle erfordert eine große Menge an MAC-Operationen. Zum Beispiel hat selbst ein vergleichsweise kleines „1.0 MobileNet-224“-Modell 4,2 Millionen Parameter (Gewichte) und erfordert 569 Millionen MAC-Operationen, um eine Inferenz durchzuführen. Da die meisten Modelle von MAC-Operationen dominiert werden, liegt der Fokus hier auf diesem Teil der Machine-Learning-Berechnung – und der Erkundung der Möglichkeit, eine bessere Lösung zu schaffen. Ein einfaches, vollständig verbundenes zweischichtiges Netzwerk ist unten in Abbildung 2 dargestellt.
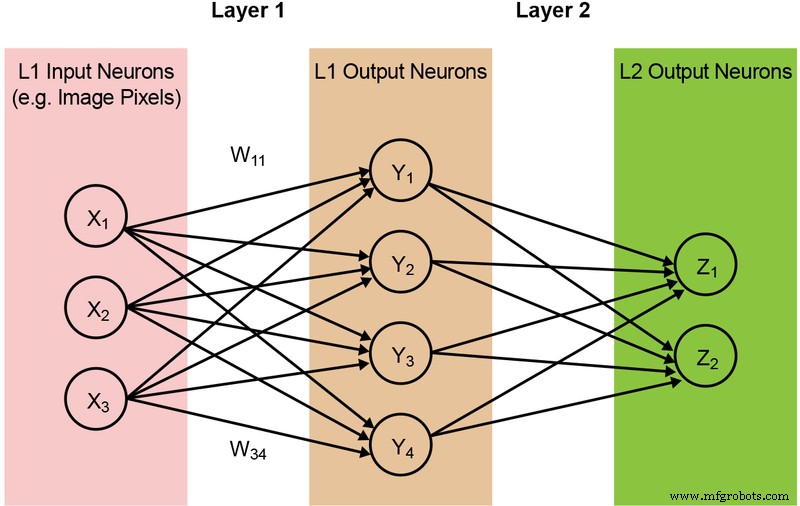
Abbildung 2:Vollständig verbundenes neuronales Netzwerk mit zwei Schichten. (Quelle:Microchip Technology)
Die Eingabeneuronen (Daten) werden mit der ersten Gewichtungsschicht verarbeitet. Die Ausgabeneuronen der ersten Schichten werden dann mit der zweiten Gewichtungsschicht verarbeitet und liefern Vorhersagen (sagen wir, ob das Modell in einem bestimmten Bild ein Katzengesicht finden konnte). Diese neuronalen Netzmodelle verwenden das „A-Punkt-Produkt“ zur Berechnung jedes Neurons in jeder Schicht, veranschaulicht durch die folgende Gleichung (wobei der „Bias“-Term in der Gleichung zur Vereinfachung weggelassen wird):
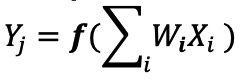
Speicher Engpass beim Digital Computing
Bei einer Implementierung eines digitalen neuronalen Netzwerks werden die Gewichte und Eingabedaten in einem DRAM/SRAM gespeichert. Die Gewichtungen und Eingabedaten müssen zur Inferenz in eine MAC-Engine verschoben werden. Wie in Abbildung 3 unten gezeigt, führt dieser Ansatz dazu, dass der größte Teil der Leistung beim Abrufen von Modellparametern und Eingabedaten in die ALU verbraucht wird, wo die eigentliche MAC-Operation stattfindet.
Abbildung 3:Speicherengpass bei Machine Learning Computing. (Quelle:Y.-H. Chen, J. Emer und V. Sze, „Eyeriss:A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks“, in ISCA, 2016.)
Um die Dinge aus einer energetischen Perspektive zu betrachten – eine typische MAC-Operation mit digitalen Logikgattern verbraucht ~250 Femtojoule (fJ oder 10 −15 Joule) Energie, aber die während der Datenübertragung verbrauchte Energie beträgt mehr als zwei Größenordnungen als die Berechnung selbst und liegt im Bereich von 50 Picojoule (pJ, oder 10 −12 Joule) auf 100 pJ. Um fair zu sein, gibt es viele Designtechniken, um die Datenübertragung vom Speicher zur ALU zu minimieren; Das gesamte digitale Schema ist jedoch immer noch durch die Von-Neumann-Architektur eingeschränkt – dies bietet also eine große Chance, Energieverschwendung zu reduzieren. Was ist, wenn die Energie zur Durchführung einer MAC-Operation von ~100 pJ auf einen Bruchteil von pJ reduziert werden kann?
Beseitigung von Speicherengpässen mit analogem In-Memory-Computing
Das Durchführen von Inferenzoperationen am Rand wird energieeffizient, wenn der Speicher selbst verwendet werden kann, um die für die Berechnung erforderliche Energie zu reduzieren. Die Verwendung einer In-Memory-Computing-Methode minimiert die Datenmenge, die verschoben werden muss. Dies wiederum eliminiert die Energieverschwendung während der Datenübertragung. Die Energiedissipation wird weiter minimiert, indem Flash-Zellen verwendet werden, die mit extrem geringer aktiver Verlustleistung arbeiten können und im Standby-Modus fast keine Energiedissipation aufweisen.
Ein Beispiel für diesen Ansatz ist die memBrain™-Technologie von Silicon Storage Technology (SST), einem Unternehmen von Microchip Technology. Basierend auf SSTs SuperFlash ® Speichertechnologie umfasst die Lösung eine In-Memory-Computing-Architektur, die es ermöglicht, Berechnungen dort durchzuführen, wo die Gewichte des Inferenzmodells gespeichert sind. Dies beseitigt den Speicherengpass bei der MAC-Berechnung, da es keine Datenbewegung für die Gewichte gibt – nur Eingabedaten müssen von einem Eingabesensor wie einer Kamera oder einem Mikrofon zum Speicherarray übertragen werden.
Dieses Speicherkonzept basiert auf zwei Grundlagen:(a) Die analoge elektrische Stromantwort eines Transistors basiert auf seiner Schwellenspannung (Vt) und den Eingangsdaten und (b) dem Kirchhoffschen Stromgesetz, das besagt, dass die algebraische Summe der Ströme in ein Netz von Leitern, die sich an einem Punkt treffen, ist Null.
Es ist auch wichtig, die grundlegende Bitzelle des nichtflüchtigen Speichers (NVM) zu verstehen, die in dieser mehrstufigen Speicherarchitektur verwendet wird. Das Diagramm unten (Abbildung 4) ist ein Querschnitt von zwei ESF3 (Embedded SuperFlash 3 rd Generation) Bitzellen mit gemeinsamem Erase Gate (EG) und Source Line (SL). Jede Bitzelle hat fünf Anschlüsse:Control Gate (CG), Work Line (WL), Erase Gate (EG), Source Line (SL) und Bitline (BL). Der Löschvorgang an der Bitzelle erfolgt durch Anlegen einer Hochspannung an EG. Der Programmiervorgang erfolgt durch Anlegen von Hoch-/Niederspannungs-Vorspannungssignalen an WL, CG, BL und SL. Der Lesevorgang erfolgt durch Anlegen von Niederspannungs-Vorspannungssignalen an WL, CG, BL und SL.
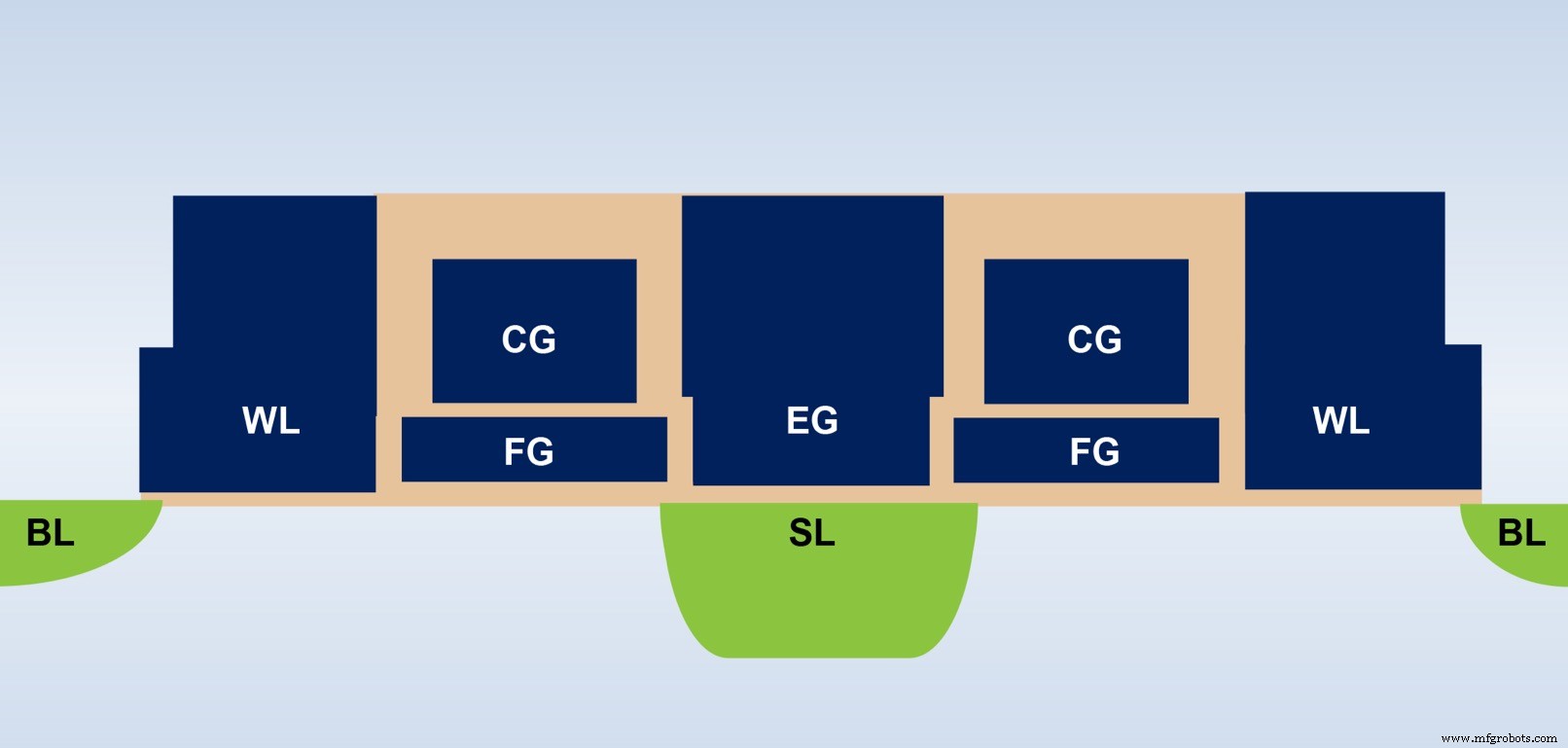
Abbildung 4:SuperFlash ESF3-Zelle. (Quelle:Microchip Technology)
Mit dieser Speicherarchitektur kann der Benutzer die Speicherbitzellen auf verschiedenen Vt-Pegeln durch feinkörnige Programmieroperationen programmieren. Die Speichertechnologie verwendet einen intelligenten Algorithmus, um das Floating-Gate (FG) Vt der Speicherzelle abzustimmen, um eine bestimmte elektrische Stromantwort von einer Eingangsspannung zu erreichen. Je nach Anforderung der Endanwendung können die Zellen entweder im linearen oder unterschwelligen Betriebsbereich programmiert werden.
Fig. 5 veranschaulicht die Fähigkeit zum Speichern und Lesen mehrerer Ebenen auf der Speicherzelle. Nehmen wir an, wir versuchen, einen 2-Bit-Ganzzahlwert in einer Speicherzelle zu speichern. Für dieses Szenario müssen wir jede Zelle in einem Speicherarray mit einem von vier möglichen Werten der 2-Bit-Ganzzahlwerte (00, 01, 10, 11) programmieren. Die vier folgenden Kurven sind eine IV-Kurve für jeden der vier möglichen Zustände, und die elektrische Stromantwort der Zelle würde von der an CG angelegten Spannung abhängen.
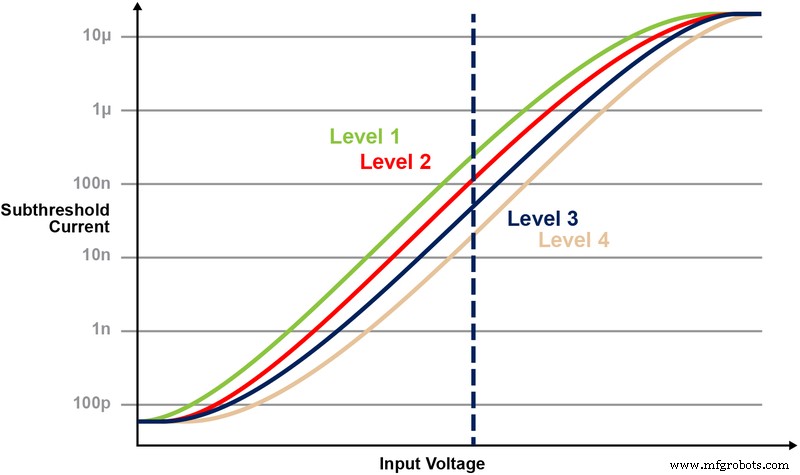
Abbildung 5:Programmierung der Vt-Pegel in einer ESF3-Zelle. (Quelle:Microchip Technology)
Multiplizieren-Akkumulieren-Vorgang mit In-Memory-Computing
Jede ESF3-Zelle kann als variable Leitfähigkeit modelliert werden (gm ). Die Leitfähigkeit einer ESF3-Zelle hängt vom Floating Gate Vt der programmierten Zelle ab. Ein Gewicht aus einem trainierten Modell wird als Floating Gate Vt der Speicherzelle programmiert, daher gm der Zelle repräsentiert eine Gewichtung des trainierten Modells. Wenn eine Eingangsspannung (Vin) an die ESF3-Zelle angelegt wird, wäre der Ausgangsstrom (Iout) durch die Gleichung Iout =gm . gegeben * Vin, das ist die Multiplikationsoperation zwischen der Eingangsspannung und dem auf der ESF3-Zelle gespeicherten Gewicht.
Abbildung 6 unten zeigt das Multiplikations-Akkumulations-Konzept in einer kleinen Array-Konfiguration (2×2-Array), bei der die Akkumulationsoperation durch Addieren von Ausgangsströmen (von den Zellen (von der Multiplikationsoperation) durchgeführt wird, die mit derselben Spalte verbunden sind (zum Beispiel I1 =I11 + I21) Je nach Anwendung kann die Aktivierungsfunktion entweder innerhalb des ADC-Blocks oder mit einer digitalen Implementierung außerhalb des Speicherblocks durchgeführt werden.
Klicken für größeres Bild
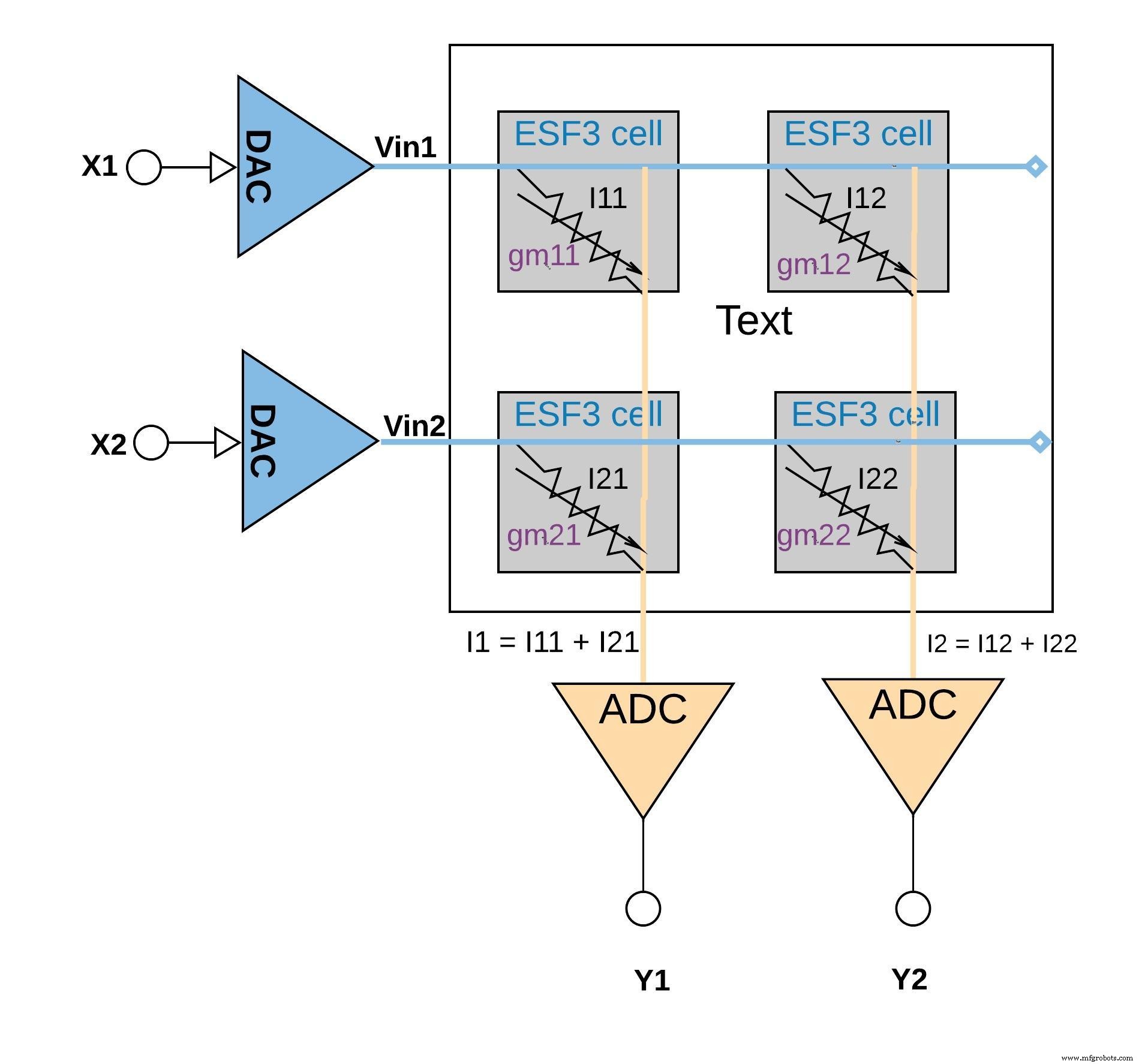
Abbildung 6:Multiplizieren-Akkumulieren-Operation mit ESF3-Array (2×2). (Quelle:Microchip Technology)
Um das Konzept auf einer höheren Ebene weiter zu veranschaulichen; einzelne Gewichte eines trainierten Modells werden als Floating Gate Vt der Speicherzelle programmiert, sodass alle Gewichte von jeder Schicht des trainierten Modells (sagen wir eine vollständig verbundene Schicht) auf einem Speicherarray programmiert werden können, das physikalisch wie eine Gewichtsmatrix aussieht , wie in Abbildung 7 dargestellt.
Klicken für größeres Bild
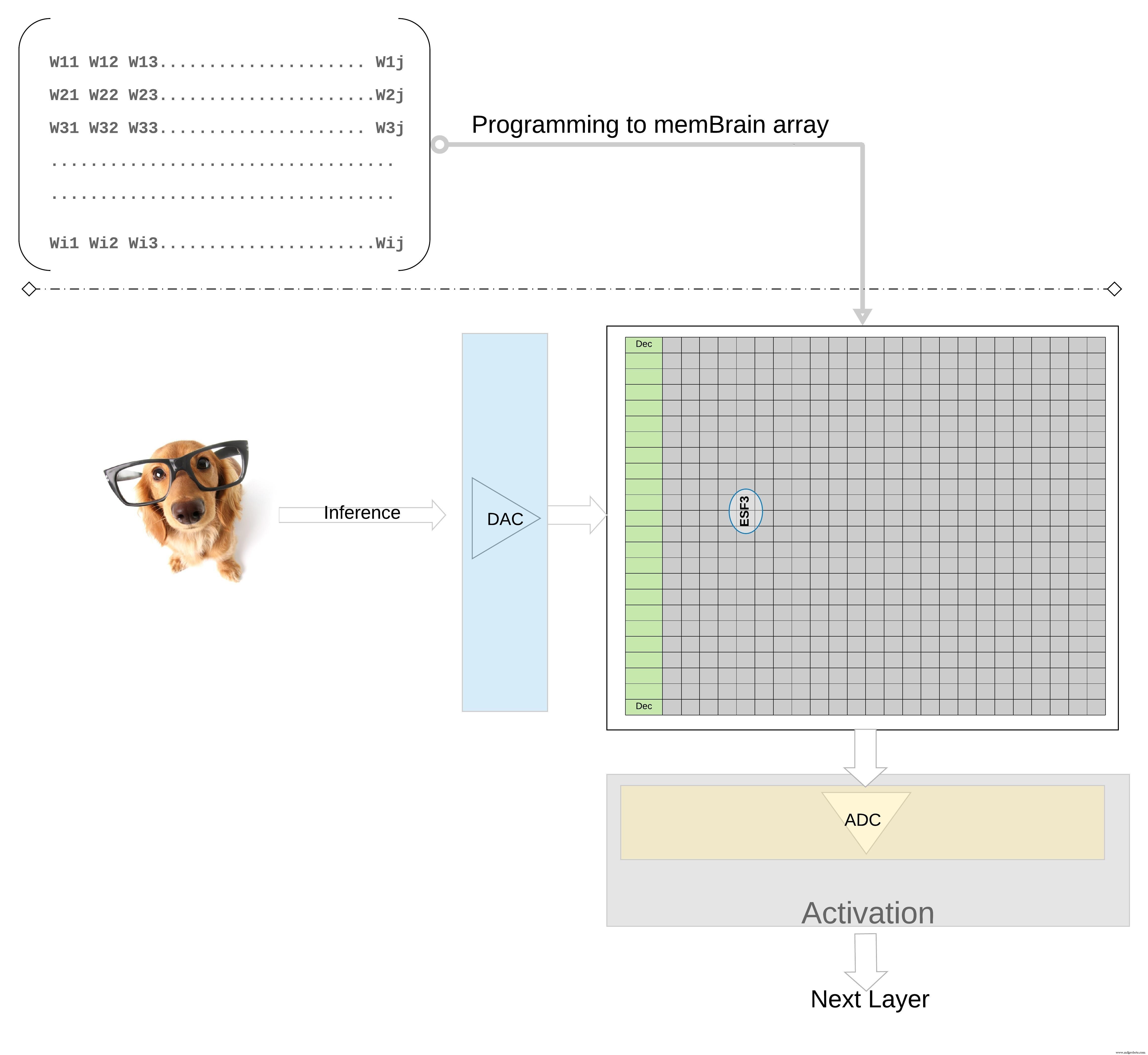
Abbildung 7:Gewichtsmatrix-Speicherarray für Inferenz. (Quelle:Microchip Technology)
Für eine Inferenzoperation wird ein digitaler Eingang, sagen wir Bildpixel, zuerst mit einem Digital-Analog-Wandler (DAC) in ein analoges Signal umgewandelt und an das Speicherarray angelegt. Das Array führt dann Tausende von MAC-Operationen parallel für den gegebenen Eingangsvektor aus und erzeugt eine Ausgabe, die an die Aktivierungsstufe der jeweiligen Neuronen gehen kann, die dann mit einem Analog-Digital-Wandler (ADC) wieder in digitale Signale umgewandelt werden können. Die digitalen Signale werden dann für das Pooling verarbeitet, bevor sie zur nächsten Schicht gehen.
Diese Art von Speicherarchitektur ist sehr modular und flexibel. Viele memBrain-Kacheln können zusammengefügt werden, um eine Vielzahl großer Modelle mit einer Mischung aus Gewichtsmatrizen und Neuronen zu erstellen, wie in Abbildung 8 dargestellt. In diesem Beispiel wird eine 3×4-Kachelkonfiguration mit einem analogen und digitalen Gewebe zwischen den Kacheln und Daten können über einen gemeinsamen Bus von einer Kachel zur anderen verschoben werden.
Klicken für größeres Bild
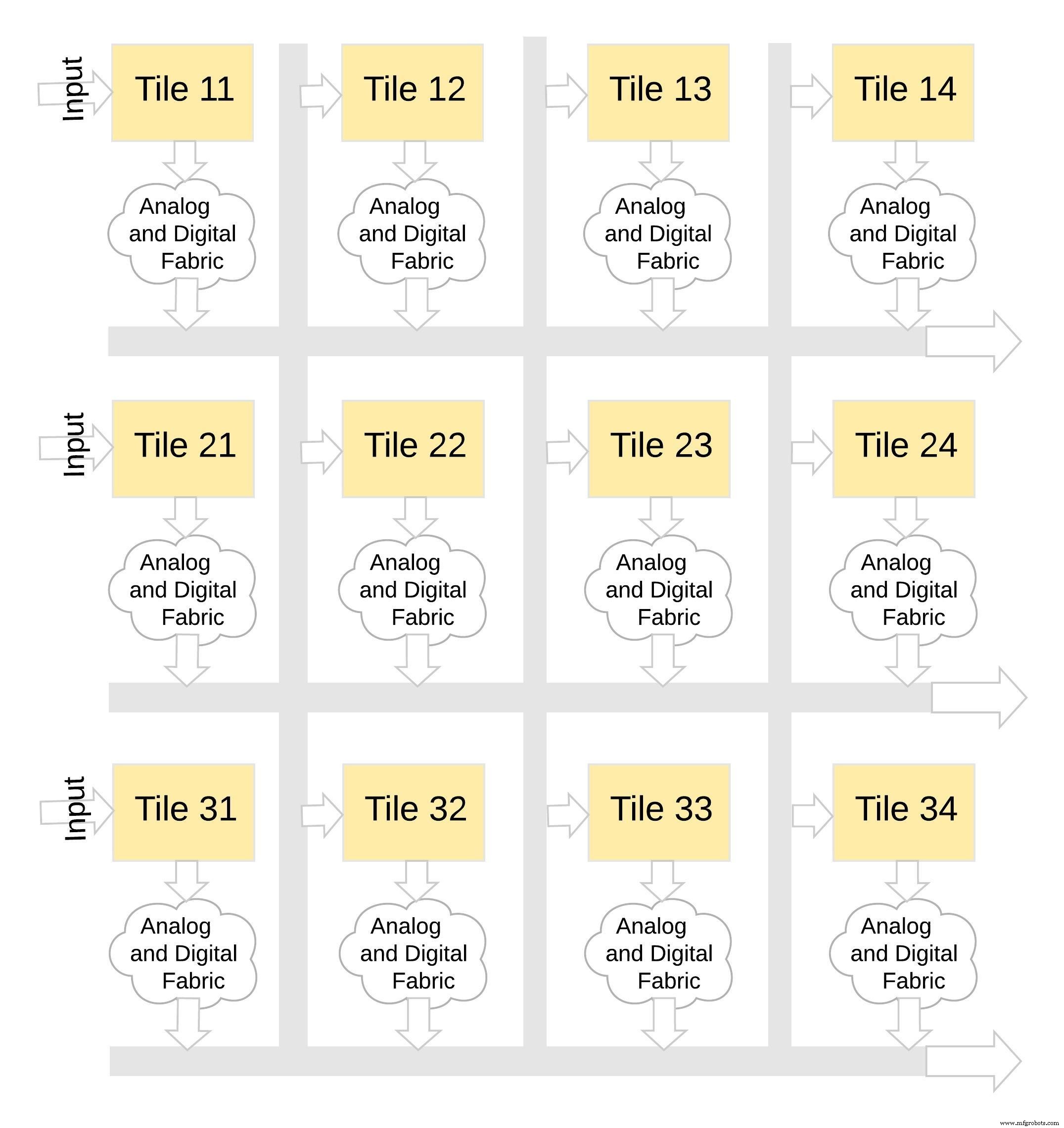
Abbildung 8:memBrain™ ist modular. (Quelle:Microchip Technology)
Bisher haben wir hauptsächlich die Siliziumimplementierung dieser Architektur diskutiert. Die Verfügbarkeit eines Software Development Kit (SDK) (Abbildung 9) hilft bei der Bereitstellung der Lösung. Zusätzlich zum Silizium erleichtert das SDK die Bereitstellung der Inferenz-Engine.
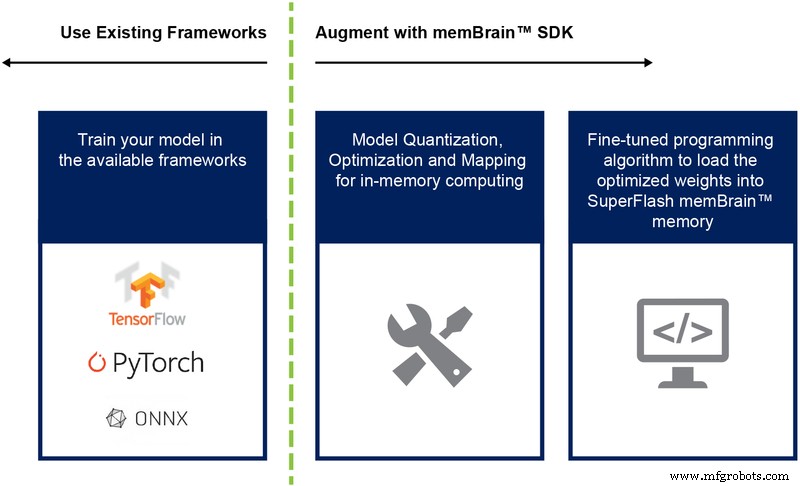
Abbildung 9:memBrain™ SDK Flow. (Quelle:Microchip Technology)
Der SDK-Flow ist unabhängig vom Trainingsframework. Der Benutzer kann ein neuronales Netzwerkmodell in jedem der verfügbaren Frameworks wie TensorFlow, PyTorch oder anderen erstellen, wobei er nach Wunsch Gleitkommaberechnungen verwendet. Sobald ein Modell erstellt wurde, hilft das SDK bei der Quantisierung des trainierten neuronalen Netzwerkmodells und der Abbildung auf das Speicherarray, wo die Vektor-Matrix-Multiplikation mit dem von einem Sensor oder Computer kommenden Eingangsvektor durchgeführt werden kann.
Schlussfolgerung
Zu den Vorteilen dieses Multi-Level-Memory-Ansatzes mit seinen In-Memory-Computing-Fähigkeiten gehören:
- Extrem geringer Stromverbrauch: Die Technologie ist für Low-Power-Anwendungen ausgelegt. Der Leistungsvorteil der ersten Ebene ergibt sich aus der Tatsache, dass die Lösung In-Memory-Computing ist, sodass keine Energie für die Übertragung von Daten und Gewichten vom SRAM/DRAM während der Berechnung verschwendet wird. Der zweite Energievorteil ergibt sich daraus, dass Flash-Zellen im Subthreshold-Modus mit sehr niedrigen Stromwerten betrieben werden und somit die aktive Verlustleistung sehr gering ist. Der dritte Vorteil besteht darin, dass im Standby-Modus fast keine Energie verloren geht, da die nichtflüchtige Speicherzelle keinen Strom benötigt, um die Daten für das Always-On-Gerät zu speichern. Der Ansatz ist auch gut geeignet, um die Knappheit bei Gewichtungen und Eingabedaten auszunutzen. Die Speicherbitzelle wird nicht aktiviert, wenn die Eingabedaten oder das Gewicht Null sind.
- Geringerer Paketbedarf: Die Technologie verwendet eine Split-Gate-(1,5T)-Zellenarchitektur, während eine SRAM-Zelle in einer digitalen Implementierung auf einer 6T-Architektur basiert. Außerdem ist die Zelle im Vergleich zu einer 6T-SRAM-Zelle eine viel kleinere Bitzelle. Außerdem kann eine Zellenzelle den gesamten 4-Bit-Ganzzahlwert speichern, im Gegensatz zu einer SRAM-Zelle, die dazu 4*6 =24 Transistoren benötigt. Dies bietet einen wesentlich geringeren Platzbedarf auf dem Chip.
- Geringere Entwicklungskosten: Aufgrund von Engpässen bei der Speicherleistung und Einschränkungen der Von-Neumann-Architektur neigen viele speziell entwickelte Geräte (wie Nvidias Jetsen oder Googles TPU) dazu, kleinere Geometrien zu verwenden, um Leistung pro Watt zu steigern, was eine teure Möglichkeit ist, die Edge-KI-Computing-Herausforderung zu lösen. Beim Multi-Level-Memory-Ansatz, der analoge On-Memory-Computing-Methoden verwendet, erfolgt die Berechnung auf dem Chip in Flash-Zellen, sodass größere Geometrien verwendet und Maskenkosten und Vorlaufzeiten reduziert werden können.
Edge-Computing-Anwendungen sind vielversprechend. Doch bevor Edge Computing durchstarten kann, müssen noch einige Herausforderungen in Bezug auf Leistung und Kosten gelöst werden. Eine große Hürde kann durch die Verwendung eines Speicheransatzes genommen werden, der Berechnungen auf dem Chip in Flash-Zellen durchführt. Dieser Ansatz nutzt eine produktionserprobte De-facto-Standardlösung für mehrstufige Speichertechnologie, die für Anwendungen des maschinellen Lernens optimiert ist.
Eingebettet
- Wie Edge Computing der Unternehmens-IT zugute kommen könnte
- Wie Cloud Computing IT-Mitarbeitern helfen kann?
- Eine Einführung in Edge Computing und Anwendungsbeispiele
- Edge Computing:5 potenzielle Fallstricke
- Wie IIoT-Daten die Rentabilität in der schlanken Fertigung steigern können
- Näher am Edge:Wie Edge Computing Industrie 4.0 vorantreiben wird
- Wie ein Stromausfall Ihre Netzteile beschädigen kann
- 6 gute Gründe für Edge Computing
- Edge-Computing und 5G skalieren das Unternehmen
- Wie kleine Geschäfte digital werden können – wirtschaftlich!