


Die Herausforderungen der Multicore-Programmierung und des Debuggens meistern
In diesem Artikel werden verschiedene Aspekte der Multicore-Verarbeitung erörtert, einschließlich eines Blicks auf verschiedene Arten von Multicore-Prozessoren und warum diese Geräte heute üblich und beliebt werden. Wir werden uns dann einige der Herausforderungen ansehen, die durch mehr als einen Kern auf einem Chip entstehen, und wie moderne Multicore-fähige Debugger dazu beitragen können, diese komplexen Aufgaben leichter handhabbar zu machen.
Systemleistung
Es gibt viele Möglichkeiten, die Leistung eines eingebetteten Computersystems zu steigern, von cleveren Compileralgorithmen bis hin zu effizienten Hardwarelösungen. Compileroptimierungen sind wichtig, um die effizienteste Befehlsplanung aus leicht lesbarem und verständlichem Hochsprachencode zu erzielen. Darüber hinaus können Systeme die im Projekt verfügbare Parallelität nutzen, um mehr als eine Sache gleichzeitig zu verarbeiten. Und natürlich kann die Skalierung der Taktfrequenz ein effektiver Weg sein, um mehr Leistung aus Ihrem Computersystem herauszuholen.
Leider sind die Zeiten vorbei, in denen von geometrisch steigenden Taktraten ausgegangen werden konnte. Und die Code-Optimierung kann Ihnen gerade jetzt, nach vielen Generationen der Compiler-Technologieentwicklung, nur begrenzte Verbesserungen bringen. Dies lässt uns die Parallelität als die beste Möglichkeit betrachten, unsere Systemleistung im Laufe der Zeit weiter zu skalieren.
Parallelismus

Das Graben eines Brunnens ist eine schwer zu parallelisierende Aufgabe. Andere können helfen, indem sie den Schmutz wegschaufeln, aber das eigentliche Graben ist normalerweise eine Ein-Personen-Arbeit. Infolgedessen wird die Arbeit nicht schneller erledigt, wenn mehr Personen in das Loch aufgenommen werden. Tatsächlich können die anderen nur im Weg stehen und den Prozess verlangsamen. Einige Aufgaben eignen sich nicht für die Parallelisierung.
Andere Aufgaben lassen sich leicht parallelisieren. Das Ausheben eines Grabens ist eine für die Parallelisierung geeignete Aufgabe. Viele Menschen können nebeneinander arbeiten.

Dieses Bild zeigt eine Form der Parallelität namens MIMD, Multiple Instruction Multiple Data. Jeder Bagger ist eine separate Einheit und kann verschiedene Aufgaben ausführen. In diesem Fall können Sie sich vorstellen, dass vier Bagger die Arbeit in etwa 1/4 stel erledigen die Zeit eines einzelnen Baggers.
Mit SIMD, Single Instruction Multiple Data, könnte ein einzelner Bagger eine Schaufel wie diese verwenden.
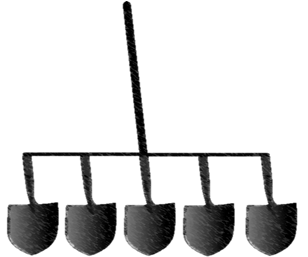
Die SIMD-Einheit kann jeweils nur eine Art von Berechnung durchführen, kann sie jedoch parallel an mehreren Datenelementen durchführen. Diese Arten von Befehlen sind in Vektorverarbeitungseinheiten in vielen Prozessoren üblich. Dies ist nützlich, wenn Ihre Daten sehr regelmäßig sind und Sie die gleichen Operationen immer wieder an einem großen Datensatz wie bei der Bildverarbeitung durchführen müssen. Für allgemeinere Rechenaufgaben fehlt diesem Modell jedoch die Flexibilität und es werden keine Leistungssteigerungen erzielt.
Dies führt uns zu der Entscheidung, mehrere vollständige CPU-Subsysteme auf einem einzigen Chip zu platzieren, wodurch Multicore-Prozessoren entstehen. Mehrere Kerne auf einem Chip können die Leistung skalieren. Jeder Kern ist eine vollständige CPU und kann unabhängig oder zusammen mit anderen Kernen arbeiten.
Verschiedene Arten der Multicore-Verarbeitung
Es gibt verschiedene Kombinationen von Typen von Kernen, die Sie möglicherweise auf einem Prozessorchip haben, sowie wie die Arbeit auf sie verteilt wird.
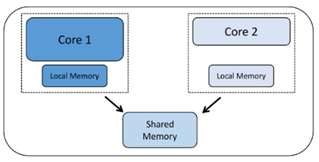
Homogene Multicore-Prozessoren haben zwei oder mehr Kopien desselben Prozessorkerns. Jeder Kern läuft autonom und kann über eine Reihe von Mechanismen wie Shared Memory oder Mailbox-Systeme mit anderen Kernen kommunizieren und sich synchronisieren. Jeder Prozessor hat seine eigenen Register und Funktionseinheiten und kann seinen eigenen lokalen Speicher oder Cache haben. Was dies jedoch homogen macht, ist die Tatsache, dass alle von uns untersuchten Kerne vom gleichen Typ sind.
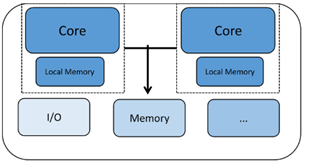
Ein anderer Typ von Mehrkernchips wird als heterogener Mehrkernchip mit zwei oder mehr verschiedenen Arten von CPU-Kernen bezeichnet. Hier können die Kerne sehr unterschiedliche Eigenschaften aufweisen, die sie für verschiedene Teile der Systemverarbeitungsanforderungen gut geeignet machen. Ein Beispiel könnte ein Bluetooth-Kommunikationschip sein, bei dem ein Kern für die Verwaltung des Bluetooth-Protokollstapels bestimmt ist, während der andere Kern die externe Kommunikation, die Anwendungsverarbeitung, die menschliche Schnittstelle usw. verwaltet. Diese Art von Mehrkernchip kann für Anwendungen verwendet werden, die beides benötigen dedizierte Echtzeitleistung auf einem Kern und Systemverwaltungsfunktionen auf dem anderen.
Jetzt schauen wir uns an, wie die Kerne verwendet werden. Symmetrisches Multiprocessing (SMP) tritt auf, wenn Sie über mehr als einen Kern verfügen und die Kerne dieselbe Projektcodebasis ausführen. Auf verschiedenen Kernen können gleichzeitig verschiedene Teile des Codes ausgeführt werden, aber der Code wird als einzelnes Projekt erstellt und von einem steuernden Programm wie einem Echtzeitbetriebssystem (RTOS) an die separaten Kerne gesendet. Notwendigerweise müssen die auf diese Weise arbeitenden Kerne vom gleichen Typ sein, da sie alle den gleichen Projektcode verwenden, der für einen Prozessortyp kompiliert wurde.
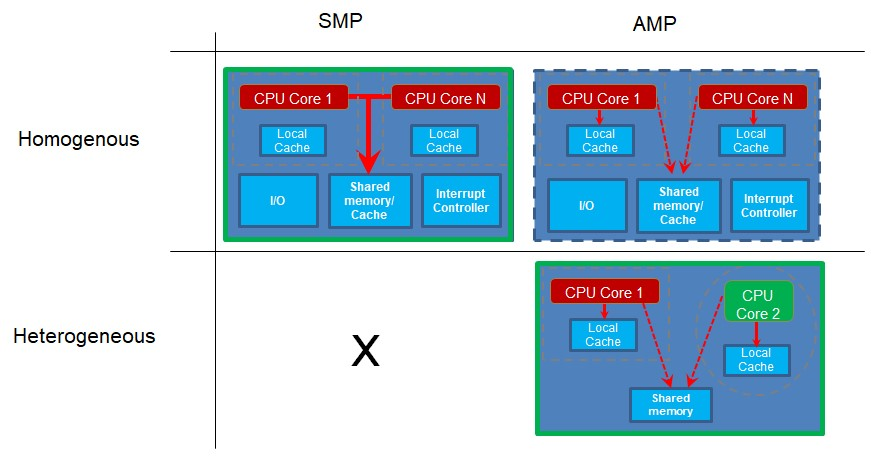
Asymmetrisches Multiprocessing (AMP) tritt auf, wenn Sie mehr als einen Kern oder Prozessor haben und jeder Prozessor seine eigene Projektanwendung ausführt. Die separaten Kerne können sich von Zeit zu Zeit synchronisieren oder kommunizieren, aber sie haben jeweils ihre eigene Codebasis, die sie ausführen. Da sie jeweils ein eigenes Projekt ausführen, können diese Kerne unterschiedlichen Typs oder heterogenen Kernen sein. Dies ist jedoch keine Voraussetzung. Wenn zwei oder mehr Kerne desselben Typs unterschiedlichen Projektcode ausführen, handelt es sich um homogene Kerne, auf denen AMP ausgeführt wird.
Beachten Sie, dass Sie für den SMP-Betrieb über mehrere homogene Kerne verfügen müssen, da sie alle Code von derselben einzigen Projektcodebasis ausführen. Wenn Sie jedoch mehrere Projekte mit unterschiedlichen Codebasen für die verschiedenen auszuführenden Kerne haben, können dies unterschiedliche Kerne sein, beispielsweise in einem heterogenen System. Wenn die Kerne jedoch gleich sind, funktioniert das auch.
Gründe für die Verwendung von Multicore
In den letzten Jahren scheint das Mooresche Gesetz, das Mitte der 1960er Jahre geprägt wurde, endlich die Puste zu verlieren oder zumindest zu verlangsamen. Die Prozessortaktraten verdoppeln sich nicht mehr alle 2-3 Jahre und tatsächlich erreichen die CPUs mit der höchsten Geschwindigkeit seit vielen Jahren eine Obergrenze im niedrigen einstelligen GHz-Bereich.
Eine Möglichkeit, die Leistungsgrenzen weiter auszureizen, besteht darin, mehr CPU-Kerne zusammenarbeiten zu lassen, wenn Sie sie effizient nutzen können.
Während sich die Geschwindigkeiten stabilisiert haben, ist die Transistorgröße weiter geschrumpft. Obwohl langsamer als in der Vergangenheit, ermöglichen die kleinen Transistoren das Packen von mehr Logik auf einem einzigen Chip. Infolgedessen kann die Verwendung dieser Transistoren, um mehrere CPU-Kerne auf einem einzigen Chip zu platzieren, viel schnellere und breitere Busverbindungen zwischen den verschiedenen CPU- und Speichersubsystemen nutzen.
Heterogenes asymmetrisches Multiprocessing ist sehr nützlich, wenn eine Anwendung zwei oder mehr Workloads mit sehr unterschiedlichen Eigenschaften und Anforderungen hat. Einer könnte von Echtzeit und Interrupt-Latenz abhängig sein, während der andere mehr vom Durchsatz als von der Reaktionszeit abhängig sein könnte. Dieses Modell funktioniert sehr gut:Ein Gerät kann beispielsweise einen Kern für die Verwaltung eines Kommunikationsprotokollstapels wie Bluetooth oder Zigbee dedizieren, während ein anderer Kern als Anwendungsprozessor fungiert, der menschliche Interaktionen und allgemeine Systemverwaltungsvorgänge ausführt. Da der Kommunikationsprozessor isoliert ist, kann er eine ausgezeichnete Echtzeitantwort bereitstellen, die vom Protokollstapel benötigt wird. Darüber hinaus kann die Kommunikationssoftware nach einem Standard zertifiziert werden, wodurch das gesamte Produkt leicht zu zertifizieren ist, indem funktionale Änderungen von diesem Teil des Systems getrennt bleiben.
Herausforderungen bei der Verwendung von Multicore
Welche Herausforderungen ergeben sich, wenn Sie mehr als einen CPU-Kern auf einem Chip platzieren? Nun, lass uns darauf eingehen.
Eine monolithische Anwendung oder Software ist möglicherweise nicht in der Lage, die verfügbaren Computerressourcen effizient zu nutzen. Sie müssen die Anwendung in parallele Aufgaben organisieren, die gleichzeitig ausgeführt werden können, um Ressourcen von mehr als einem Kern zu verwenden. Dies kann für Software-Ingenieure eine ungewohnte Art und Weise erfordern, an eingebettetes Design zu denken. Die Migration von vorhandenem Single-Loop-Code ist möglicherweise nicht ganz einfach. Zu wenige oder sogar zu viele Threads können zu Leistungshindernissen werden.
Anwendungen, die Datenstrukturen oder E/A-Geräte von mehreren Threads oder Prozessen gemeinsam nutzen, können serielle Engpässe aufweisen. Um die Datenintegrität aufrechtzuerhalten, muss der Zugriff auf diese gemeinsam genutzten Ressourcen möglicherweise mithilfe von Sperrtechniken serialisiert werden, z. B. Lesesperre, Lese-Schreib-Sperre, Schreibsperre, Spinlock, Mutex usw. Ineffizient gestaltete Sperren können aufgrund hoher Sperrenkonflikte zwischen mehreren Threads oder Prozessen, die versuchen, die Sperre zu erlangen, um eine gemeinsam genutzte Ressource zu verwenden, zu Engpässen führen. Dies könnte möglicherweise die Leistung der Anwendung oder Software beeinträchtigen. Die Leistung einer Anwendung kann sich sogar verschlechtern, wenn die Anzahl der Kerne oder Prozessoren steigt, wenn einige Kerne andere blockieren, die auf gemeinsame Sperren warten, wodurch zwei Kerne schlechter abschneiden als einer.
Eine ungleichmäßig verteilte Arbeitslast kann bei der Nutzung von Rechenressourcen ineffizient sein. Möglicherweise müssen Sie große Aufgaben in kleinere aufteilen, die parallel ausgeführt werden können. Möglicherweise müssen Sie serielle Algorithmen in parallele umwandeln, um die Leistung und Skalierbarkeit zu verbessern. Wenn jedoch einige Aufgaben sehr schnell ausgeführt werden und andere viel Zeit in Anspruch nehmen, können die schnellen Aufgaben viel Zeit damit verbringen, auf den Abschluss der langen Aufgaben zu warten. Dies führt zu einem Leerlauf von wertvollen Rechenressourcen und einer schlechten Leistungsskalierung.
Ein RTOS wird Ihnen wahrscheinlich helfen, aber möglicherweise nicht alles lösen. In einem SMP-System ist dies praktisch ein Muss, um Aufgaben über eine Reihe ähnlicher Kerne zu planen. Die zu erledigende Arbeit kann nach Daten oder nach Funktion unterteilt werden. Wenn Sie die Dinge nach Datenblöcken aufteilen, kann jeder Thread alle Schritte einer Verarbeitungspipeline ausführen. Alternativ könnte ein Thread einen Schritt in der Funktion ausführen, während ein anderer den nächsten Schritt ausführt usw. Die Vorteile einer Technik gegenüber der anderen hängen von den Merkmalen der auszuführenden Arbeit ab.
Debugging in Multicore-Umgebungen
Das erste, was beim Debuggen eines Multicore-Systems nützlich ist, ist die Sichtbarkeit aller Kerne. Im Idealfall sollten wir in der Lage sein, Kerne gleichzeitig oder einzeln zu starten und zu stoppen – d. h. einen Kern in einem Schritt ausführen, während andere ausgeführt oder gestoppt werden. Multicore-Breakpoints können sehr nützlich sein, um den Betrieb eines Kerns abhängig vom Zustand eines anderen zu steuern.
Multicore-Trace kann sehr schwierig zu implementieren sein. Die Verwaltung der hohen Bandbreite an Trace-Informationen von mehreren Kernen sowie der Umgang mit potenziell unterschiedlichen Arten von Trace-Daten von verschiedenen Arten von Kernen ist eine echte Herausforderung.
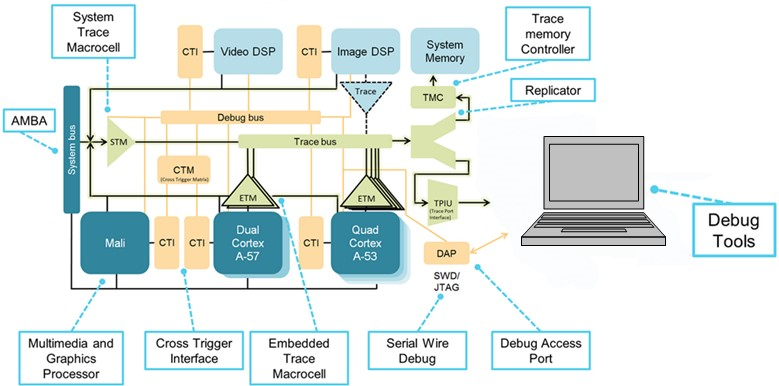
(Quelle:IAR Systems, Diagramm mit freundlicher Genehmigung von Arm Ltd.)
Hier ist ein Beispiel für einen Prozessor mit heterogenen und homogenen Multicore-Implementierungen. Es gibt zwei homogene Kerngruppen, eine basierend auf einem Dual-Arm-Cortex-A57 und die andere auf einem Quad-Cortex-A53. Diese Gruppen sind in sich homogen, aber heterogen zwischen den beiden Gruppen.
Die CoreSight-Debug-Architektur stellt Protokolle und Mechanismen für die Kommunikation mit den Debug-Ressourcen auf allen Kernen bereit und es obliegt dem Debugger, all diese Informationen zu verwalten und Nachrichten von verschiedenen Kernen zu analysieren. Die Cross-Trigger-Schnittstellen und -Matrix (CTI, CTM) ermöglichen das gleichzeitige Anhalten beider Kerne, das Triggern von Trace und mehr. Die Trace-Infrastruktur umfasst die seriellen (SWD) und parallelen (TPIU) Trace-Ports, die zum Glätten des Trace-Flusses verwendet werden, und die Trace-Trichter, die den Trace von jeder Quelle zu einem einzigen Fluss kombinieren. Im Vergleich zum Dual-Core-Teil stellt das gezeigte Diagramm einen viel komplexer zu steuernden Chip dar.
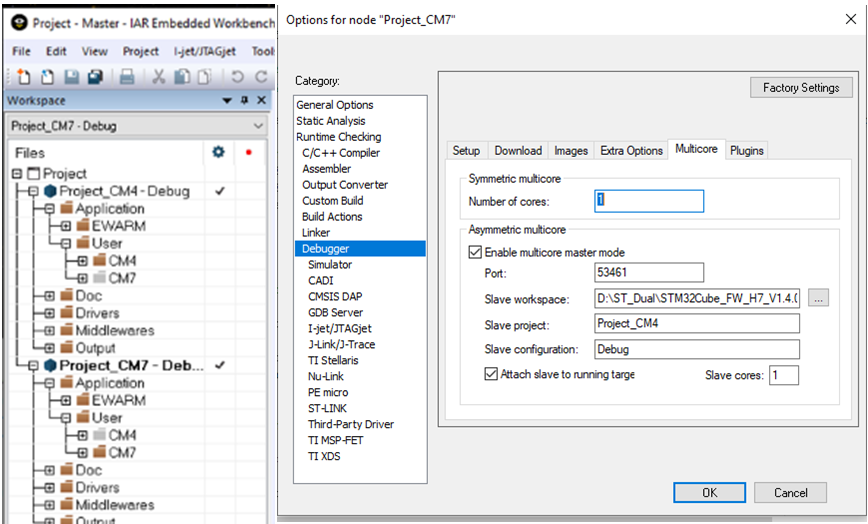
Der C-SPY Debugger in IAR Embedded Workbench unterstützt sowohl symmetrisches als auch asymmetrisches Multicore-Debugging. Dies wird über die Debugger-Optionen auf der Registerkarte Multicore aktiviert. Um das symmetrische Multicore-Debugging zu aktivieren, muss lediglich die Anzahl der Kerne eingegeben werden, um dem Debugger mitzuteilen, mit wie vielen verschiedenen Prozessoren er kommunizieren soll. Andere IDEs haben möglicherweise ähnliche Optionen.
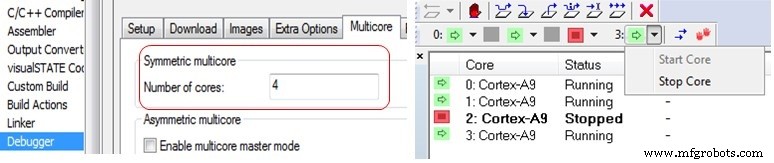
Rechts (oben) sehen Sie eine Ansicht im Debugger, in der der Status der Kerne eines 4-Kern-Cortex-A9-SMP-Clusters mit Kernnummer 2 angehalten angezeigt wird, während die anderen drei Kerne ausgeführt werden.
Ein asymmetrisches Multicore-System kann einen heterogenen Multicore-Teil verwenden, wie das ST STM32H745/755, das einen Cortex-M7-Kern und einen separaten Cortex-M4 hat. In diesem Fall verwendet der Debugger beim Ausführen zwei Instanzen der IDE (Master und Node). Einer für jeden Kern, da auf den beiden Kernen unterschiedlicher Projektcode ausgeführt wird.
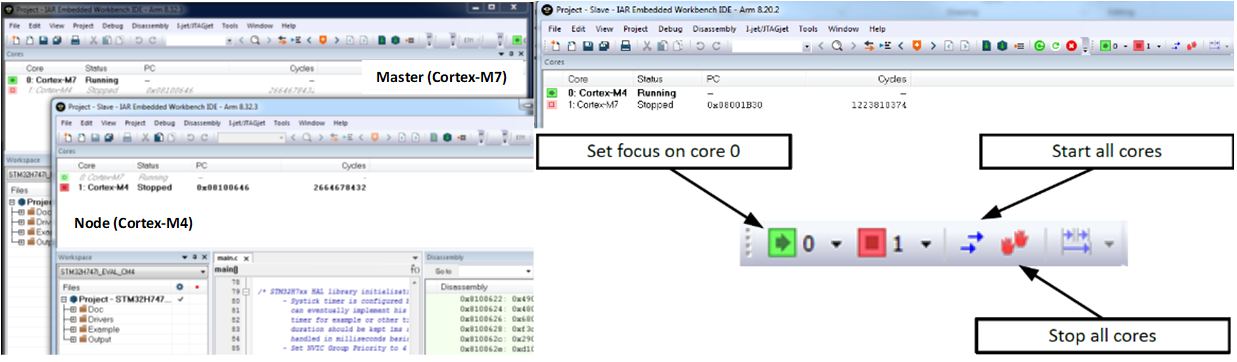
In jeder Instanz der IDE gibt es Statusinformationen über den gesteuerten Kern sowie den anderen gesteuerten Kern im anderen Fenster. Es gibt Optionen, die ausgewählt werden können, um das Verhalten des Debuggers zu steuern, sodass das Starten und Stoppen der Kerne zusammen oder separat unter der Kontrolle des Entwicklers liegt.
Diese volle Kontrolle ist dank der Cross-Trigger-Schnittstellen (CTI) und der Cross-Trigger-Matrix (CTM) möglich, die zusammen die eingebettete Cross-Trigger-Funktion des Arms bilden. Es gibt drei CTI-Komponenten, eine auf Systemebene, eine für den Cortex-M7 und eine für den Cortex-M4. Die drei CTIs sind über das CTM miteinander verbunden, wie in der Abbildung unten dargestellt. Auf die Systemebene und die Cortex-M4-CTIs kann der Debugger über den Systemzugriffsport und das zugehörige APB-D zugreifen. Der Cortex-M7 CTI ist physisch in den Cortex-M7-Kern integriert und über den Cortex-M7-Zugangsport zugänglich.
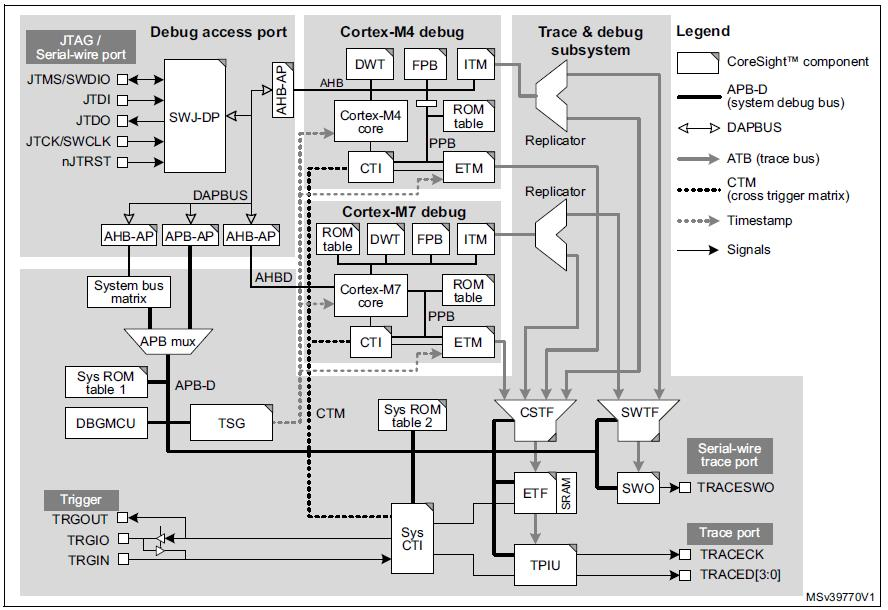
(Quelle:IAR Systems, Diagramm mit freundlicher Genehmigung von STMicroelectronics aus dem M0399 Referenzhandbuch)
Die CTIs ermöglichen Ereignissen aus verschiedenen Quellen, Debug- und Trace-Aktivitäten auszulösen. Beispielsweise kann ein in einem der Prozessorkerne erreichter Breakpoint den anderen Prozessor stoppen, oder ein an einem externen Triggereingang erkannter Übergang könnte so eingestellt werden, dass die Codeverfolgung gestartet wird.
In diesem Beispiel mit einem heterogenen Multicore-Prozessor, der einen Cortex-M7-Kern und einen Cortex-M4-Kern auf einem einzigen Chip hat, werden zwei separate Programme verwendet:eines läuft auf dem Cortex-M4 und das andere läuft auf dem Cortex-M7. Jedes Projekt verwendet FreeRTOS, um die auf den Prozessoren ausgeführte Software zu verwalten. Die beiden Kerne kommunizieren über eine gemeinsam genutzte Speicherschnittstelle. Die Anwendungen verwenden jedoch beide die FreeRTOS-Meldungsweitergabemechanismen, um mit dem anderen Prozessor zu kommunizieren, und verbergen die Komplexität der zugrunde liegenden Mechanismen. Aus der Sicht einer CPU sendet oder empfängt sie also nur Nachrichten mit einer anderen Aufgabe. Es ist klar, dass die andere Aufgabe zufällig auf einem anderen CPU-Kern ausgeführt wird.
Das Bild unten zeigt das Workspace-Explorer-Witwe in der IDE. Die Übersicht über zwei Projekte wird hier angezeigt, sodass Sie die Inhalte der beiden Cortex-M7- und Cortex-M4-Projekte sehen können.
Durch Auswahl einer der anderen Registerkarten am unteren Rand des Fensters können Sie den Fokus entweder auf das M4-Projekt oder das M7-Projekt umschalten.
Das Cortex-M7-Projekt hat einen Task, der Nachrichten an Tasks sendet, die auf dem Cortex-M4 laufen. Der Cortex-M4 hat zwei Instanzen einer laufenden Empfangsaufgabe. Der Cortex-M7 hat eine „Check“-Aufgabe, die regelmäßig ausgeführt wird, um zu sehen, ob die Dinge noch richtig laufen.
Schließlich lädt der Debugger beide Projekte. Dies bedeutet, dass eine zusätzliche Instanz von Embedded Workbench für den zweiten Debugger gestartet wird.
Um den Debugger für asymmetrische Multiprocessing-Unterstützung einzurichten, müssen wir ein Projekt als „Master“ und das andere als „Node“-Projekt festlegen. Tatsächlich ist die Auswahl willkürlich und bestimmt nur, welches Projekt die Fähigkeit hat, das andere beim Start zu starten.
Das „Node“-Projekt hat keine speziellen Einstellungen und weiß nicht, dass es als „Node“ zu einem anderen Projekt läuft.
Auf diese Weise wird beim Starten des Debuggers des „Master“-Projekts automatisch eine weitere Instanz der IDE gestartet, um eine zweite Debugger-Sitzung aufzunehmen, in der das zweite Projekt ausgeführt wird.
Zusammenfassung
Multicore ermöglicht Leistungssteigerungen, wenn das Mooresche Gesetz abgelaufen ist. Multicore stellt jedoch Herausforderungen beim Debuggen dar und erfordert spezifische Entwicklungsansätze, damit die Anwendung die Multicore-Architektur optimal nutzen kann.
Sobald das Debug-Setup konfiguriert ist, war Multicore-Debugging noch nie so einfach. Wenn Sie schon einmal Tools zum Debuggen von Monocores verwendet haben, werden Sie alles erkennen, was darin enthalten ist, und Sie werden wahrscheinlich nie verstehen, wie andere Leute darüber sprechen, wie schwierig Multicore-Debugging für sie ist.
Moderne Hardware- und Softwaretools helfen Ihnen, die Herausforderungen beim Multicore-Debugging zu meistern.
Hinweis:Abbildungsbilder stammen von IAR Systems, sofern nicht anders angegeben.
 Aaron Bauch ist Senior Field Application Engineer bei IAR Systems und arbeitet mit Kunden im Osten der Vereinigten Staaten und Kanada. Aaron hat mit eingebetteten Systemen und Software für Unternehmen wie Intel, Analog Devices und Digital Equipment Corporation gearbeitet. Seine Designs decken ein breites Anwendungsspektrum ab, darunter medizinische Instrumente, Navigations- und Banksysteme. Aaron hat auch eine Reihe von Studiengängen auf College-Niveau unterrichtet, darunter Embedded System Design als Professor an der Southern NH University. Herr Bauch hat einen Bachelor-Abschluss in Elektrotechnik von The Cooper Union und einen Master in Elektrotechnik von der Columbia University, beide in New York, NY.
Aaron Bauch ist Senior Field Application Engineer bei IAR Systems und arbeitet mit Kunden im Osten der Vereinigten Staaten und Kanada. Aaron hat mit eingebetteten Systemen und Software für Unternehmen wie Intel, Analog Devices und Digital Equipment Corporation gearbeitet. Seine Designs decken ein breites Anwendungsspektrum ab, darunter medizinische Instrumente, Navigations- und Banksysteme. Aaron hat auch eine Reihe von Studiengängen auf College-Niveau unterrichtet, darunter Embedded System Design als Professor an der Southern NH University. Herr Bauch hat einen Bachelor-Abschluss in Elektrotechnik von The Cooper Union und einen Master in Elektrotechnik von der Columbia University, beide in New York, NY. Verwandte Inhalte:
- Gewährleistung des Software-Timing-Verhaltens in kritischen Multicore-basierten eingebetteten Systemen
- Multicore-Systeme, Hypervisoren und Multicore-Frameworks
- Hochleistungs-Embedded-Computing – Parallelität und Compiler-Optimierung
- Sie denken, Ihre Software funktioniert? Beweisen Sie es!
- Software-Tracing in feldeingesetzten Geräten
- Compiler in der fremden Welt der funktionalen Sicherheit
Für mehr Embedded, abonnieren Sie den wöchentlichen E-Mail-Newsletter von Embedded.
Eingebettet
- WiFi-Netzwerke, SaaS-Anbieter und die damit verbundenen Herausforderungen für die IT
- Boards – Breakout the Pi – I2C, UART, GPIO und mehr
- Die fünf wichtigsten Probleme und Herausforderungen für 5G
- Die komplexen Risikofaktoren für Luft- und Raumfahrt und Verteidigung
- 5G, IoT und die neuen Herausforderungen der Lieferkette
- Stellen Sie sich den ETL-Herausforderungen von IoT-Daten und maximieren Sie den ROI
- Die Herausforderungen des Hartdrehens meistern
- Die 4 größten Herausforderungen für die Luft- und Raumfahrt- und Verteidigungs-OEM-Industrie
- Die Bedeutung und Herausforderungen aktueller Dokumentation
- Die Vorteile und Herausforderungen der Hybridfertigung verstehen