


Tief in den Data Science-Lebenszyklus eintauchen
Seit dem Aufkommen von Big Data erreicht die moderne Informatik neue Leistungsfähigkeiten und Rechenleistungs-Benchmarks. Heutzutage ist es nicht ungewöhnlich, Anwendungen zu finden, die Datensätze von 100 Terabyte oder mehr produzieren, was als Big Data bezeichnet wird.
Bei solch großen Informationsmengen ist es leicht, desorganisiert zu werden und Zeit mit nutzlosen Inhalten zu verschwenden. Dies sind zwei Gründe, warum es sehr wichtig ist, einer Methodik zu folgen, die die Wirksamkeit und Effizienz eines Big-Data-Projekts erhöht.

Abbildung 1. Moderne Data Science arbeitet mit sehr großen Datensätzen, auch Big Data genannt.
Der Data Science-Lebenszyklus bietet einen Rahmen, der hilft, Big-Data-Projekte zu definieren, zu sammeln, zu organisieren, auszuwerten und bereitzustellen. Es ist ein iterativer Prozess, der aus einer Reihe von Schritten besteht, die in einer logischen Reihenfolge angeordnet sind, um Feedback und Pivoting zu erleichtern.
Wie sieht der Lebenszyklusablauf aus? Die Antwort lautet:Es gibt kein einziges universelles Modell, dem jeder folgt. Viele Unternehmen, die Big-Data-Projekte durchführen, passen den Data Science-Lebenszyklus an ihre Geschäftsprozesse an und umfassen in der Regel mehr Schritte. Trotzdem haben all die vielen Modelle und Prozessabläufe einen gemeinsamen Nenner. In diesem Artikel wird das CRISP-DM-Prozessmodell verwendet, das eines der ersten und beliebtesten Lebenszyklusmodelle der Datenwissenschaft ist.
Das CRISP-DM-Modell
CRISP-DM steht für Cross Industry Standard Process for Data Mining. Es wurde erstmals 1999 von ESPRIT veröffentlicht, einem europäischen Programm zur Förderung der Forschung in der Informationstechnologie (IT). Das CRISP-DM-Modell besteht aus sechs Schritten oder Phasen, die das Big-Data-Projekt leiten. Es ermutigt die Stakeholder, über das Geschäft nachzudenken, indem es wichtige Fragen zu dem Problem stellt und beantwortet.
Lassen Sie uns die sechs Phasen des CRISP-DM-Modells im Detail betrachten.
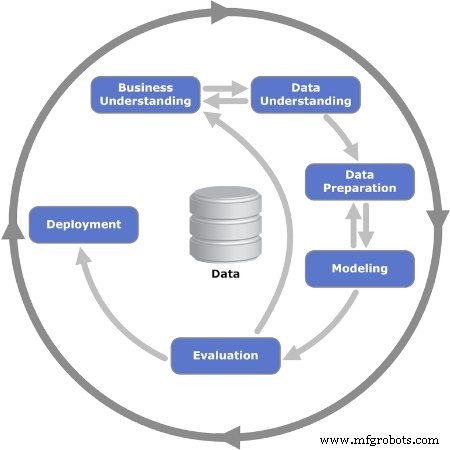
Abbildung 2. Die iterativen sechs Phasen des CRISP-DM-Modells werden gezeigt. Bild mit freundlicher Genehmigung von Kenneth Jensen
Phase 1:Geschäftsverständnis
Die erste Phase besteht aus mehreren Aufgaben, die das Problem definieren und Ziele festlegen. Hier werden die Projektziele mit dem Fokus auf das Geschäft – oder anders gesagt den Kunden – festgelegt. Normalerweise muss das Team, das für die Arbeit an einem Big-Data-Projekt zusammengestellt wird, dem Kunden eine Lösung liefern, bei der es sich um einen anderen Bereich oder eine andere Abteilung innerhalb des Unternehmens handeln kann.
Sobald die Geschäftsanforderung oder das Problem festgestellt wurde, besteht der nächste Schritt darin, Erfolgskriterien zu definieren. Dies können Key Performance Indicators (KPI) oder Service Level Agreements (SLA) sein, die objektive Mittel zur Bewertung des Fortschritts und der Fertigstellung bieten.
Als nächstes muss die Geschäftssituation analysiert werden, um Risiken, Rollback-Pläne, Notfallmaßnahmen und vor allem die Ressourcenverfügbarkeit zu identifizieren. Ein Projektplan wird erstellt, einschließlich der Ressourcen für Meilensteine.
Phase 2:Datenverständnis
Nachdem in der vorherigen Phase die Grundlagen geschaffen wurden, ist es an der Zeit, sich auf die Daten zu konzentrieren. Diese Phase beginnt mit einer ersten Definition der Daten, die als notwendig erachtet werden, und dokumentiert dann einige Einzelheiten dazu:wo sie zu finden sind, Art der Daten, Format, Beziehungen zwischen verschiedenen Datenfeldern usw.
Nachdem die erste Dokumentation fertig ist, besteht der nächste Schritt darin, den ersten Datenerfassungslauf durchzuführen. Dies liefert eine nützliche Momentaufnahme davon, wie sich die Struktur bildet. Diese Momentaufnahme der Informationen wird dann auf ihre Qualität hin bewertet.
Phase 3:Datenaufbereitung
Die dritte Phase verstärkt die vorherige Phase und bereitet den Datensatz für die Modellierung vor. Datenfelder aus der ersten Sammlung werden weiter kuratiert und alle als unnötig erachteten Informationen werden aus dem Satz entfernt:Dies wird als Bereinigen der Daten bezeichnet.
Außerdem muss eine bestimmte Information möglicherweise aus anderen verfügbaren Informationen abgeleitet werden; zu anderen Zeiten muss es kombiniert werden. Mit anderen Worten, die Daten müssen verarbeitet werden, um ein endgültiges Format zu erzeugen.
Phase 4:Modellierung
Die wichtigste Aufgabe in dieser Phase ist die Auswahl eines Algorithmus zur Verarbeitung der gesammelten Daten. In diesem Zusammenhang ist ein Algorithmus ein Satz von Sequenzschritten und Regeln, die in Computersoftware programmiert sind, die für Big-Data-Projekte entwickelt wurde.
Viele Algorithmen können verwendet werden:Lineare Regressionen, Entscheidungsbäume und Support-Vektor-Maschinen sind einige Beispiele. Die Auswahl des richtigen Algorithmus zur Lösung des Problems erfordert Fähigkeiten, die erfahrene Data Scientists haben.
Abbildung 3. Lineare Regression ist eine Art von Algorithmus, der bei der Big-Data-Modellierung verwendet wird.
Der nächste Schritt besteht darin, den Algorithmus in die Softwareanwendung zu codieren. Zu diesem Zeitpunkt wird auch die Testphase geplant, die darin besteht, bestimmte Datensätze für Tests und Validierung zuzuweisen.
Phase 5:Evaluierung
Manchmal ist es schwierig, von Anfang an einen Algorithmus auszuwählen. In diesem Fall führen Wissenschaftler mehrere Algorithmen aus und analysieren die Ergebnisse, um eine endgültige Entscheidung zu treffen. Nach Abschluss der Testphase werden die Ergebnisse auf Vollständigkeit und Richtigkeit überprüft.
Noch wichtiger ist, dass dies eine Gelegenheit ist, zu beurteilen, ob die Ergebnisse zu einer Lösung führen. Im iterativen Modell ist dies ein entscheidender Schnittpunkt, an dem große Iterationssequenzen gestartet oder eine Entscheidung getroffen werden kann, in die Endphase überzugehen.
Phase 6:Bereitstellung
Zu diesem Zeitpunkt wechselt das Projekt von einer Testumgebung in eine Live-Produktionsumgebung. Die Planung des Bereitstellungszeitplans und der Bereitstellungsstrategie ist sehr wichtig, um Risiken und potenzielle Systemausfallzeiten zu reduzieren.
Obwohl das Modelldiagramm nahelegt, dass dies das Ende des Projekts ist, sind danach noch zahlreiche Schritte zu verfolgen:Überwachung und Wartung. Monitoring ist ein Zeitraum der genauen Beobachtung, auch Hypercare genannt, unmittelbar nach dem Go-Live. Wartung ist ein semipermanenter Prozess zur Wartung und Aktualisierung der implementierten Lösung.
Big Data wird aus einem bestimmten Grund so genannt:Es gibt eine riesige Datenmenge, die analysiert werden muss. Die Implementierung eines der Data-Science-Lebenszyklusmodelle hilft bei der Entscheidung, welche Informationen es wert sind, aufbewahrt und für Prozesse wie die vorausschauende Wartung verwendet zu werden.
Internet der Dinge-Technologie
- Über das Smartphone hinaus:Aus Daten Sounds machen
- Ausgelagerte KI und Deep Learning im Gesundheitswesen – Ist der Datenschutz gefährdet?
- Wartung in der digitalen Welt
- Optimierung des SIM-Lebenszyklus
- Demokratisierung des IoT
- Maximierung des Wertes von IoT-Daten
- Datenwissenschaft in die Hände von Domänenexperten geben, um wertvollere Erkenntnisse zu liefern
- Warum die Direktverbindung die nächste Phase des industriellen IoT ist
- Der Wert der analogen Messung
- Tableau, die Daten hinter den Informationen