


Fehlertoleranz und ihre Auswirkungen auf die Systemzuverlässigkeit
Geräte und Systeme, die ohne Berücksichtigung von Fehlertoleranz entwickelt wurden, weisen oft eine geringe(r) Zuverlässigkeit auf.
Aus diesem Grund ist ein fehlertolerantes Systemdesign für die meisten Zuverlässigkeits- und Konstruktionsingenieure eine offensichtliche Wahl – insbesondere wenn es um kritische Geräte geht, deren Ausfall die Zuverlässigkeit, Verfügbarkeit, Wartbarkeit und Sicherheit (RAMS) des gesamten Systems beeinträchtigen kann, das sie sind Teil von.
Begleiten Sie uns, wenn wir die Eigenschaften fehlertoleranter Systeme erforschen und Möglichkeiten zur Verbesserung der Fehlertoleranz durch redundante Designs diskutieren.
Was ist Fehlertoleranz?
Fehlertoleranz stellt die Fähigkeit eines Systems oder einer Ausrüstung dar, seinen Betrieb während des Vorliegens eines Fehlers aufrechtzuerhalten.
Systeme und Geräte mit hoher Fehlertoleranz können, abhängig vom eingesetzten Fehlertoleranzmechanismus, ihren Betrieb bei Auftreten eines Fehlers ganz oder teilweise aufrechterhalten. Damit dies in der Praxis funktioniert, dürfen solche Systeme keinen Single Point of Failure (SPOF) haben.
Das Wesen fehlertoleranter Designs
Die Entwicklung eines fehlertoleranten Designs erfordert eine sorgfältige Abwägung von Fehlern, die sich während des gesamten Gerätelebenszyklus manifestieren können, zusammen mit ihren wahrscheinlichen Ursachen und Folgen.
Die Konstrukteure müssen jedoch auch die Kosten- und Ressourcenfaktoren berücksichtigen, die erforderlich sind, um das erforderliche Maß an Toleranz, Zuverlässigkeit und Zuverlässigkeit der Ausrüstung zu erreichen.
Es wird oft missverstanden, dass ein fehlertolerantes Design eine vollständige Toleranz gegenüber allen Arten von Fehlern bieten sollte. Das ist nicht wahr. Ein gutes Design sollte den Toleranzgrad an die Kritikalität des Fehlers anpassen, sodass eine Gesamtoptimierung der Kosten- und Ressourceneffizienz erreicht werden kann.
Es kann beispielsweise nicht kosteneffizient sein, Geld für die Neugestaltung von Produkten auszugeben, nur um einen Fehler zu beheben, der eine äußerst geringe Wahrscheinlichkeit hat, auftritt.
Eigenschaften fehlertoleranter Systeme
Um ein fehlertolerantes System zu schaffen, sind in jeder Phase des Gerätelebenszyklus Anstrengungen erforderlich. Dies umfasst unter anderem die Spezifikations- und Designphase (Integration von Fehlererkennungskontrollen in das Design), Validierung und Verifizierung (V&V), Wartung und Betrieb (unter Verwendung von OEM-zugelassenen Ersatzteilen und Richtlinien für die routinemäßige Wartung) und sogar Entsorgungsphase .
Jede Stufe kann Kombinationen der unten aufgeführten Techniken anwenden, um neue Designs zu entwickeln oder bestehende zu verbessern, um ihre Fehlertoleranz zu erhöhen:
- Fehlererkennung und -anzeige
- Fehlerdiagnose und Eindämmung
- Fehlermaskierung und -kompensation
1) Fehlererkennung und -anzeige
Die Fehlererkennung bezieht sich auf die Fähigkeit des Systems/der Ausrüstung, den Fehler zu erkennen und anzuzeigen. Es ist der grundlegende Aspekt jedes fehlertoleranten Systems . Alle anderen Aspekte hängen von der Wirksamkeit des Fehlererkennungsprozesses ab. Wenn das System nicht dafür ausgelegt ist, seinen Fehler zu erkennen, oder einen Fehler irgendwie falsch erkennt, sind auch die restlichen Aspekte wirkungslos.
Beispielsweise kann ein einfacher Luftdrucksensor in einem Autoreifendruck-Überwachungssystem (TPMS) den Luftüberschuss erkennen und den Fahrer über das Armaturenbrett des Autos benachrichtigen.
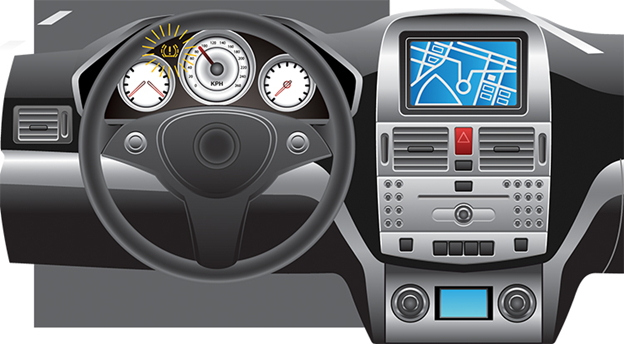
Eine Darstellung der TPMS-Aktivierung
In diesem Fall ist die Erkennung und Anzeige die einzige akzeptable Toleranzgrenze für dieses Fehlerereignis. Der Kunde kann den Luftschlauch sicher lösen, bevor der Reifen platzt.
Wenn die Druckerkennung ungenau ist, kann der Fahrer den Schlauch zu früh/zu spät lösen und während der Fahrt einen Reifenschaden feststellen. Da keine automatische Korrektur des Luftdrucks erfolgt, beschränkt sich der Toleranzaspekt für diesen Fehler auf die reine Erkennung und Anzeige.
2) Fehlerdiagnose und Eindämmung
Bei komplexeren Systemen werden oft in der Produktentwicklungsphase zusätzliche Schichten hinzugefügt. Ihr Zweck besteht darin, neben der Erkennung und Anzeige auch die Eindämmung zu diagnostizieren und durchzuführen. Diese zusätzlichen Schichten sind aufgrund der Kritikalität des Systems oder aufgrund verschiedener Sicherheitsbedenken gewährleistet.
Beispielsweise überwacht ein Distributed Control System (DCS) – ein Leitsystem für Prozessanlagen – nicht nur kritische Prozessparameter durch eine Reihe von Sensoren, sondern führt auch eine Diagnose durch, um den Ort des Fehlers zu erkennen und die erforderliche Eindämmung durchzuführen.
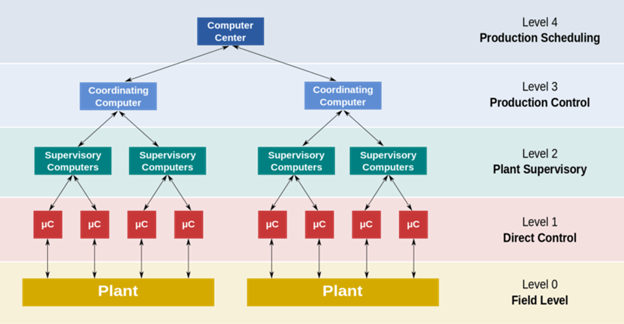
Eine Darstellung des DCS-Systems
Bei Überdruck von Mineralölprodukten in einem Behälter wird das System beispielsweise durch entsprechende Drucksensoren ausgelöst. Es öffnet das Sicherheitsdruckventil und führt die Dämpfe im Fackelkamin ab.
In diesem Beispiel erfolgt die Eindämmung durch Umleiten des brennbaren Hochdruckdampfes zum Abgaskamin, um das System vor Feuer oder Explosion zu schützen.
3) Fehlermaskierung und -kompensation
Ein weiterer effektiver Ansatz zur Fehlertoleranz besteht darin, den Fehlerzustand zu maskieren. Es ist sehr effektiv für Geräte, die über die Internet of Things (IoT)-Technologie überwacht und gesteuert werden können.
Bei solchen Geräten stellen Cybersicherheitsbedrohungen eine der größten Herausforderungen dar. Diese Arten von Bedrohungen können versuchen, den Fehler zu verursachen, indem sie den Zustand des Geräts durch die Eingabe falscher Gerätedaten in den Server ändern.
Bei falschen Aufzeichnungen über den Gerätezustand kann das ursprünglich zum Schutz gedachte Kontroll- und Überwachungssystem stattdessen den Ausfall des Assets verursachen. Alternativ kann es „getäuscht“ werden, um zu glauben, dass sich das Asset in einem guten Zustand befindet, obwohl dies tatsächlich nicht der Fall ist.
Durch die Integration von Fehlermaskierung ist das System so ausgelegt, dass es diese falschen Werte erkennen und maskieren kann.
In den Stromnetzen werden die Leistungsschalter beispielsweise oft durch Supervisory Control and Data Acquisition (SCADA) gesteuert und überwacht.
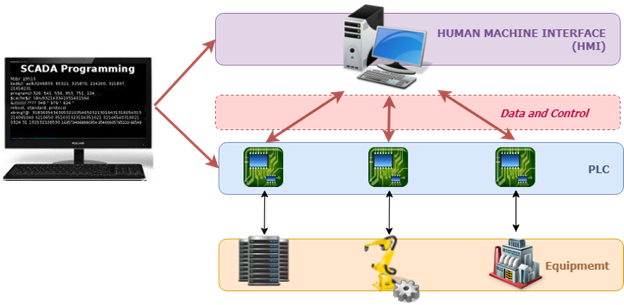
Eine Darstellung des SCADA-Systems
Ein solches System überwacht die Spannungs- und Frequenzparameter der elektrischen Ausrüstung genau und veranlasst sie, sich zu schließen oder zu öffnen, um die Stabilität des Stromnetzes aufrechtzuerhalten.
Ein eingehender Cyberangriff könnte die Spannungs- und Frequenzgrenzen des Geräts ändern. Konsequenzen? Das System könnte einen Stromausfall verursachen, anstatt ihn zu verhindern.
Die Fehlermaskierung wird häufig durch Algorithmen durchgeführt, die anomale Datenströme erkennen und falsche Daten einschleusen, um die Daten zu maskieren, die den fehlerhaften Zustand der Ausrüstung darstellen. Dies verhindert, dass die Akteure mit schlechten Daten den Fehler verbreiten und die Zuverlässigkeit des Netzes weiter verschlimmern.
Verbesserung der Fehlertoleranz durch redundante Designs
Eine der einfachen Maßnahmen, die ergriffen werden können, um die Fehlertoleranz zu erhöhen, besteht darin, Redundanzen in das Design zu integrieren. Redundanz bedeutet einfach das Vorhandensein eines alternativen Systems oder einer alternativen Lösung, die die beabsichtigte Funktion übernehmen kann, falls das primäre System ausfällt.
Während Redundanz die Fehlertoleranz verbessert, sollte das willkürliche Hinzufügen von Systemen nicht das Ziel sein, da die Kosten, die für das Hinzufügen eines neuen Systems erforderlich sind, den erreichbaren Zuverlässigkeitsvorteil deutlich aufwiegen können.
Aus Sicht der physischen Ausrüstung können sie grob als aktiv . klassifiziert werden oder passive Redundanzen .
Aktive Redundanzen
Aktive Redundanzen können aufgebaut werden, wenn mehrere Geräte gleichzeitig betrieben werden. In dieser Konfiguration trägt jedes Gerät seinen Teil dazu bei, die beabsichtigte Funktion zu erreichen, während es dennoch füreinander als Redundanz fungiert.
Eine vereinfachte aktive Redundanz ist der Parallelbetrieb von zwei Pumpen mit der Hälfte ihrer Nennleistung. Beide Pumpen arbeiten gemeinsam, um den gewünschten Förderdruck zu erreichen. Wenn eine Pumpe ausfällt, kann die andere Pumpe immer noch auf ihre Nennleistung hochgefahren werden, um den vorgesehenen Enddruck selbstständig zu erreichen. Um ein wirtschaftliches Design zu erreichen, haben sich die Zuverlässigkeitsingenieure verschiedene andere komplizierte Wege einfallen lassen, um aktive Redundanzen zu erreichen, wie beispielsweise K-von-N-Redundanzen und eine anmutige Verschlechterung.
In K von N Entlassungen , ist eine bestimmte Teilmenge der Ausrüstung immer in Betrieb. Dies erhöht die Zuverlässigkeit des Systems, da sich einige der Geräte noch im Hot-Standby befinden und bei Ausfall einiger Geräte in den Betrieb aufgenommen werden können. Dies garantiert eine höhere Zuverlässigkeit im Vergleich zum einfachen Parallelbetrieb von zwei Pumpen, da eine größere Anzahl kleiner Pumpen in Betrieb ist.
Anmutige Degradation ist eine Alternative zum Hinzufügen kostspieliger identischer und paralleler Systeme. Es stellt sicher, dass sich die Eigenschaften oder die Funktionalität der Gesamtausrüstung proportional zur Anzahl der ausgefallenen Komponenten verschlechtert. Um eine solche skalierbare Degradation zu erreichen, sollte eine Untersuchung aller möglichen Fehler innerhalb aller Komponenten durchgeführt werden. Ihr Einfluss auf die Leistung des Gesamtsystems sollte analysiert und dokumentiert werden.
Solche Techniken bieten Toleranz gegenüber Teilausfällen und ermöglichen dem System, seine Funktion mit verminderter Kapazität fortzusetzen.
Passive Redundanzen
Passive Redundanz ist die Standby-Redundanz, bei der das Ersatzgerät vorhanden ist – aber die vorgesehene Funktion nur bei Ausfall des Hauptgeräts übernehmen kann.
Wir können zwei Arten von passiven Redundanzen unterscheiden:
- Betreiben von passiven Redundanzen
- nicht betriebsbereite passive Redundanzen
Betreiben von passiven Redundanzen sind diejenigen, bei denen die alternative Ausrüstung als Hot-Spare vorhanden ist. Das Standby-Gerät ist heiß, da es im Leerlauf betrieben werden könnte. In einigen Fällen kann es eine Funktion erfüllen, die außerhalb der Definition der Funktion des Primärgeräts liegt.
Bei einem Ausfall der Primärausrüstung kann die Betriebsbereitschaftsausrüstung automatisch in die Ausführung der Funktion der Primärausrüstung überführt werden.
Ein Beispiel für den Betrieb passiver Redundanzen kann ein sekundärer Wechselstromgenerator sein, der unter Leerlaufbedingungen arbeitet und alle anderen Parallelschaltungsbedingungen erfüllt, wie beispielsweise dieselbe Klemmenspannung, Frequenz und Phasenfolge. Bei Ausfall der Primärlichtmaschine kann die Sekundärlichtmaschine automatisch mit dem System synchronisiert werden und die Last übernehmen.
Bei nicht betriebsbereiten passiven Redundanzen , wird das Standby-Gerät ausgeschaltet. Bei Ausfall von Primärgeräten kann das Standby-Equipment automatisch oder manuell in den Betriebszustand versetzt werden und die Funktionalität des Primärgerätes übernehmen.
Ein gutes Beispiel für nicht betriebsbereite passive Redundanz ist eine städtische Standby-Wasserpumpe, die manuell gestartet und betrieben werden kann, um Wasser an die Bewohner zu liefern, wenn die primäre Wasserpumpe ausfällt. Da die Wiederherstellung des Betriebs nicht kritisch ist, kann ein Bediener die Pumpe starten (und sie später bei Bedarf mit dem System synchronisieren).
Zuverlässigkeitstechniken zur Analyse der Fehlertoleranz
Fehlertoleranz ist ein Teil der Bemühungen der Zuverlässigkeitstechnik und erfordert eine sorgfältige Prüfung aller möglichen Fehler, die innerhalb der Ausrüstung auftreten können. Die Fehlermöglichkeits-Effekt-Analyse (FMEA) und die Fehlerbaumanalyse (FTA) sind zwei bekannte Techniken, um das Systemdesign aus Bottom-Up- bzw. Top-Down-Ansätzen zu analysieren.
Um die Toleranz besser zu verstehen, müssen die Fehlerreihenfolge und Abhängigkeiten analysiert und untersucht werden. Eine besonders nützliche Technik zum Analysieren von Abhängigkeiten und Sequenzen ist das Markov-Modell, bei dem die Wahrscheinlichkeit eines Fehlerereignisses vom Zustand des vorherigen Ereignisses abhängt.
In ähnlicher Weise sind Monte-Carlo-Simulationen eine weitere leistungsstarke Technik, mit der die Auswirkungen von Unsicherheiten jedes Fehlerereignisses auf die Systemleistung modelliert werden können.
Fehlertoleranz und Wartungsarbeiten
Benötigen fehlertolerante Systeme weniger Wartung? Nun ja und nein.
Aufgrund von Redundanzen und anderen Eigenschaften, die wir zuvor besprochen haben, können solche Systeme normalerweise mehr Fehler aufnehmen, bevor ihre Funktionalität beeinträchtigt wird. Wenn die Probleme jedoch nicht behoben werden, führt die Anhäufung von Fehlern schließlich zu einem System- oder Geräteausfall. Daher sollten Wartungsteams ein CMMS-System verwenden, um sicherzustellen, dass rechtzeitig korrigierende Wartungsmaßnahmen ergriffen werden.
In gewisser Weise gibt Fehlertoleranz Wartungs- und Supportteams mehr Raum zum Atmen. Sie müssen sich immer noch mit dem Problem befassen, aber vielleicht nicht sofort.
Obwohl fehlertolerante Designs ihre Herausforderungen in Bezug auf erhöhte Kosten und Komplexität haben, machen sie dies in Form einer verbesserten Gerätezuverlässigkeit wett.
Gerätewartung und Reparatur
- COVID 19 und Cloud; COVID 19 und seine Auswirkungen auf das Geschäft
- Beste Leistung bei Wartung und Zuverlässigkeit
- Wartung und Zuverlässigkeit - gut genug ist nie
- Details sind wichtig für Wartung und Zuverlässigkeit
- Wartungs- und Zuverlässigkeitslieferanten:Käufer aufgepasst
- Flexible Fertigung und Zuverlässigkeit können nebeneinander bestehen
- Anwenden von Entropie auf Wartung und Zuverlässigkeit
- UT benennt Programm in Reliability and Maintenance Center um
- Zuverlässigkeit und Sicherheit aus der Perspektive eines Kajakfahrers
- ISA veröffentlicht Buch über die Sicherheit und Zuverlässigkeit von Kontrollsystemen