


Bessere Geschäftsergebnisse durch Operationalisierung künstlicher Intelligenz im großen Maßstab
Künstliche Intelligenz (KI) treibt eine neue Normalität für Unternehmen in allen Branchen an. Einzelhändler können beispielsweise KI verwenden, um Bestellungen anhand historischer Bestandsdaten vorherzusagen, um intelligente Entscheidungen zur Wiederauffüllung der Lagerbestände zu treffen. Kundensupport-Teams können KI verwenden, um automatisch auf Kundensupport-Tickets mit hoher Priorität zu reagieren und diese an die richtigen Teams weiterzuleiten. Es gibt eine Welt voller Möglichkeiten, in denen Sie KI und insbesondere ML einsetzen können, um praktische Geschäftsergebnisse zu erzielen.
Laut Deloitte Insights sahen 83 % der Early Adopters von Unternehmens-KI einen positiven Return on Investment (ROI) von Projekten in der Produktion. Dazu gehörten Beispiele wie die Implementierung von Unternehmenssoftware von Drittanbietern mit KI, die Verwendung von Chatbots und virtuellen Assistenten sowie Empfehlungsmaschinen für E-Commerce-Plattformen. 83 % der befragten Unternehmen planten, die Ausgaben für KI im Jahr 2019 zu erhöhen. Von den Unternehmen, die in KI investieren, hatten 63 % ML eingeführt.
Der Aufbau einer Strategie für den pragmatischen Einsatz von KI und ML zum Erreichen von Geschäftszielen hat für viele Unternehmen oberste Priorität. Für viele besteht die größte Herausforderung bei der erfolgreichen Operationalisierung von ML darin, das Management einer ganzheitlichen ML-Bereitstellung im gesamten Unternehmen zu verstehen, zu planen und durchzuführen.
Wichtigste Überlegungen zur Operationalisierung von ML
Der „richtige“ Weg, den Data-Science-Lebenszyklus anzugehen, ist von Unternehmen zu Unternehmen unterschiedlich. Es wurden viele Versuche unternommen, Data-Science-Lebenszyklusverfahren zu kodifizieren und zu standardisieren. Allerdings berücksichtigt kein Ansatz die Anforderungen aller Unternehmen.
Die Umsetzung einer nachhaltigen und wartbaren Strategie für Daten und Data Science ist eine sich ständig weiterentwickelnde Übung, die für jedes Unternehmen unterschiedlich ist. Da die Bedürfnisse, Strukturen und Fähigkeiten jedes Unternehmens einzigartig sind, müssen Stakeholder aus dem gesamten Unternehmen konsultiert werden, um ein flexibles und skalierbares ML-Modell zu erstellen und eine ganzheitliche Data-Science-Strategie umzusetzen.
Die betrieblichen Herausforderungen und Änderungen an der Infrastruktur und den Entwicklungspraktiken, denen sich jedes Unternehmen stellen muss, werden unterschiedlich sein.
Es ist entscheidend, dass Ihr Unternehmen Ihre Kultur, Systeme und Anforderungen berücksichtigt, während es den Data-Science-Lebenszyklus definiert und weiterentwickelt. Ein grundlegendes Framework zu haben, das teamübergreifend präsentiert werden kann, hilft bei der Entwicklung einer gemeinsamen Basis für die Kommunikation, während Sie Ihre Operationalisierung von ML weiterentwickeln und weiterentwickeln.
Lassen Sie uns ein Standard-Framework durchgehen, das Ihrem Unternehmen beim Einstieg in die ML-Reise helfen kann.
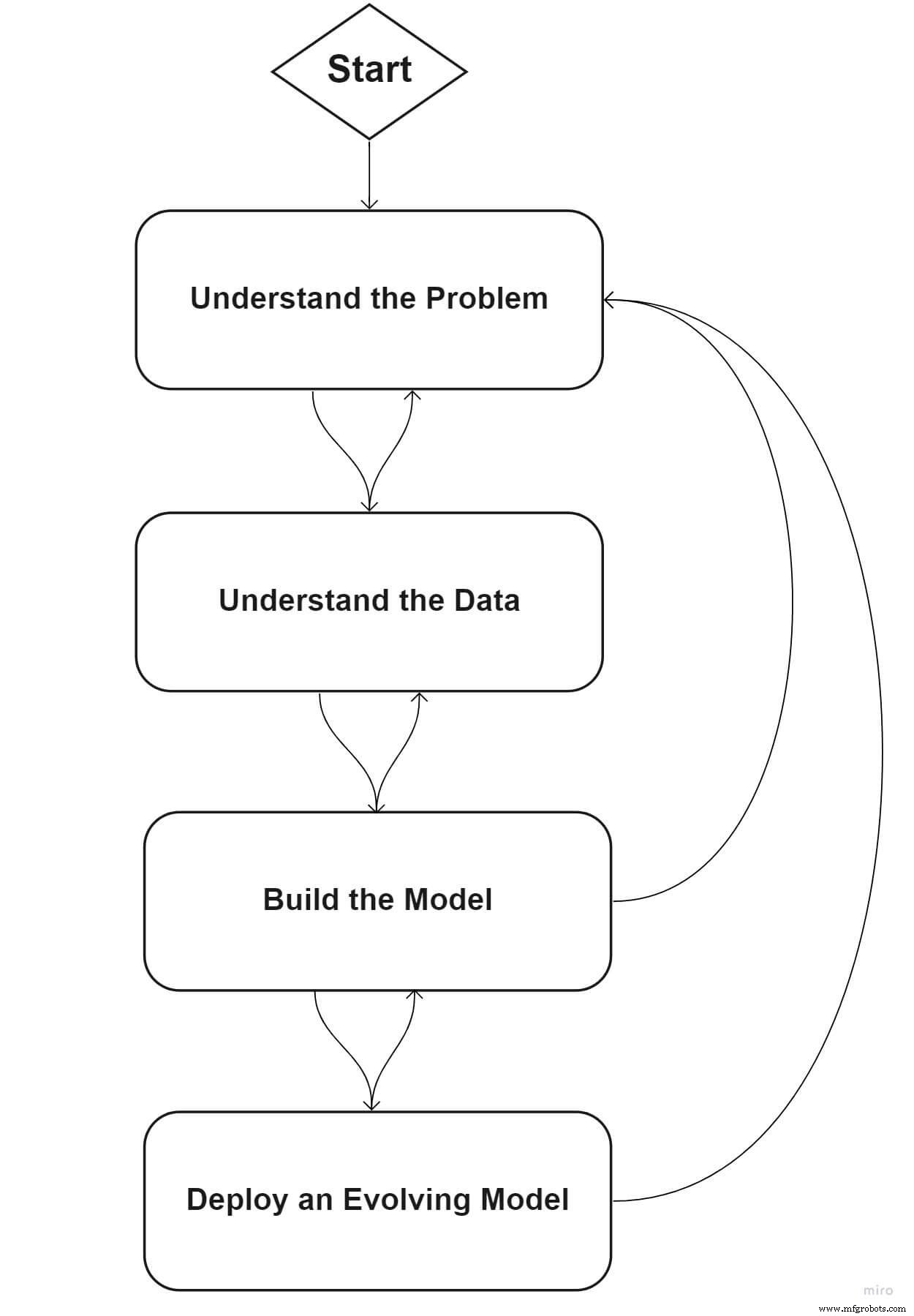
Phase eins:Definieren Sie Ihr Problem
Im Mittelpunkt jeder ML-Initiative stehen zwei Fragen:
1. Welches Problem versuchen Sie zu lösen?
2. Warum glauben Sie, dass ML und ein besseres Verständnis Ihrer Daten Ihnen helfen können, das vorliegende Problem zu lösen?
Die Antworten auf diese Fragen hängen davon ab, wie Ihr Unternehmen über Strategien denkt und geschäftliche Probleme bewertet.
In Phase eins sollten wichtige Interessengruppen zusammenkommen, um den anfänglichen Umfang des Problems und seine Anforderungen zu definieren.
Phase zwei:Verstehen Sie Ihre Daten
Was ist die Geschichte Ihrer Daten? Woher stammen Ihre Daten und wie viele Datenquellen sind relevant, um Sie bei der Lösung Ihres spezifischen Geschäftsproblems zu unterstützen?
Während dieser Phase konzentrieren sich Unternehmen auf:
-
Zuordnung relevanter Datenquellen und der Umgebungen, in denen sie leben (solche Umgebungen können lokal oder in der Cloud sein, als Data Warehouse, Data Lake oder Streaming-Datenplattformen eingerichtet sein)
-
Definieren, welche Datenpipelines derzeit vorhanden sind und welche Datenpipelines für die Datenvalidierung, -bereinigung und -exploration erstellt werden müssen
-
Verstehen, wie häufig Daten aktualisiert werden
-
Verstehen der Vertrauenswürdigkeit der Daten
-
Bewertung von Überlegungen und Anforderungen zum Datenschutz
-
Ermöglichung der Datenexploration durch Visualisierungen, statistische Eigenschaften von Rohdaten und transformierten Daten usw.
Ihre Daten zu verstehen ist keine leichte Aufgabe. Es ist wichtig, diese Phase iterativ anzugehen. Wenn Sie mehr über Ihre Daten erfahren, stellen Sie möglicherweise Probleme fest, die sich auf Ihre Fähigkeit zur Lösung des Problems auswirken, was eine Neudefinition oder Neudefinition des Problems ab Phase 1 erforderlich machen kann.
Phase drei:Erstellen Sie das ML-Modell
Sobald Sie die Daten bereit haben, ist es an der Zeit, dass Ihre Data Scientists ein ML-Modell erstellen. Zu den gängigen Schritten zum Erstellen eines robusten ML-Modells gehören:
-
Extraktions- und Konstruktionsfunktionen (einschließlich Binning, Data Whitening und Anwenden statistischer Transformationen)
-
Funktionen auswählen
-
Trainieren des Modells (umfasst das Aufteilen der Daten in eine beliebige Anzahl von Trainings-, Kreuzvalidierungs- und Validierungsdatensätzen)
-
Anpassen von Hyperparametern
-
Evaluierung des Modells
-
Validierung der statistischen Signifikanz
Die Entwicklung eines Modells erfordert kontinuierliches Feedback von den Interessenvertretern des Unternehmens. Beispielsweise kann das Geschäftsproblem eine Affinität zur Sensibilität gegenüber der Spezifität erfordern. Auf ähnliche Weise können Sie eine leichte Vorhersageleistung (z. B. F1-Ergebnis) gegen eine operative Leistung des Modells (z. B. schnellere Vorhersagen) oder die Erklärbarkeit des Modells abwägen.
Das Ziel des Datenwissenschaftlers ist es, ein Modell zu erstellen, das Daten verwendet, um eine klare Geschichte im Zusammenhang mit dem Geschäftsproblem zu erzählen. Wenn sich das Problem weiterentwickelt und sich die Anforderungen ändern, muss sich auch der Modellierungsansatz weiterentwickeln, um dem aktuellen Kontext gerecht zu werden.
Phase vier:Bereitstellen eines sich entwickelnden Modells
Das Erstellen des ersten Modells ist nur der Anfang der ML-Reise. Die Bereitstellung eines sich entwickelnden Modells ist ein entscheidender Schritt zur langfristigen Wertschöpfung für das Unternehmen.
Die Bereitstellung eines sich entwickelnden Modells erfordert Folgendes:
-
Bereitstellen des Modells (das Modell hochverfügbar und horizontal skalierbar machen)
-
Verwalten von Modellversionen (einschließlich Rollbacks und Canary/Challenger-Bereitstellungen)
-
Neutrainieren des Modells (Ändern oder Erstellen eines neuen Modells, wenn neue Daten in das System kommen)
-
Überwachung des Modells (Nachverfolgung sowohl von Betriebs- als auch von Benutzererfahrungsmetriken zu Bereitstellungs- und Trainingszeiten)
Die Überwachung von Daten- und Modellabweichungen, die Spezialisierung eines Modells für gezielte Anwendungsfälle innerhalb der Organisation und die Pflege von Datenpipelines (neben anderen Wartungselementen) sind entscheidend für den anhaltenden Erfolg eines Modells.
Unternehmens- und branchenweite Anforderungen können sich schnell weiterentwickeln und sich auf Datenquellen und Eingaben auswirken. Governance und Compliance im großen Maßstab sind beispielsweise Überlegungen, die den gesamten Data-Science-Lebenszyklus umfassen.
Die Einhaltung von Vorschriften – wie der Datenschutz-Grundverordnung (DSGVO) der Europäischen Union (EU) – erfordert eine tiefere Ebene der Rückverfolgbarkeit auf den Ebenen Datenversionierung, Modellversionierung und Modelleingabe. Der Aufbau einer Strategie zur Reaktion auf diese Branchenveränderungen und -anforderungen durch Daten kann Unternehmen dabei helfen, ML weiterhin zu nutzen, um bessere Geschäftsergebnisse wie Umsatzwachstum, Kostensenkung und geringere Risiken zu erzielen.
Was kommt als nächstes?
Die Operationalisierung von ML auf flexible, wartbare und skalierbare Weise erfordert viele Schritte und Überlegungen, die über den allgemeinen Umfang dessen hinausgehen, was wir in diesem Blog skizziert haben. Der Teufel steckt im Detail.
In unserem nächsten Blog werden wir tiefer in technische Überlegungen eintauchen, Herausforderungen, die sich aus einer Ad-hoc-Implementierung eines großen ML-Systems ergeben können, und wie UiPath dabei hilft, allgemeine Herausforderungen für Unternehmenskunden zu bewältigen.
Automatisierungssteuerung System
- Bosch fügt Industrie 4.0 künstliche Intelligenz hinzu
- Ist künstliche Intelligenz Fiktion oder Modeerscheinung?
- Wird künstliche Intelligenz früher oder später einen Einfluss auf das IoT haben?
- Warum das Internet der Dinge künstliche Intelligenz braucht
- So erstellen Sie eine erfolgreiche Business Intelligence-Strategie
- Evolution der Testautomatisierung mit künstlicher Intelligenz
- Industrielles AIoT:Kombination von künstlicher Intelligenz und IoT für Industrie 4.0
- Roboter mit künstlicher Intelligenz
- Vor- und Nachteile künstlicher Intelligenz
- Big Data vs. künstliche Intelligenz